
Fig. 1.
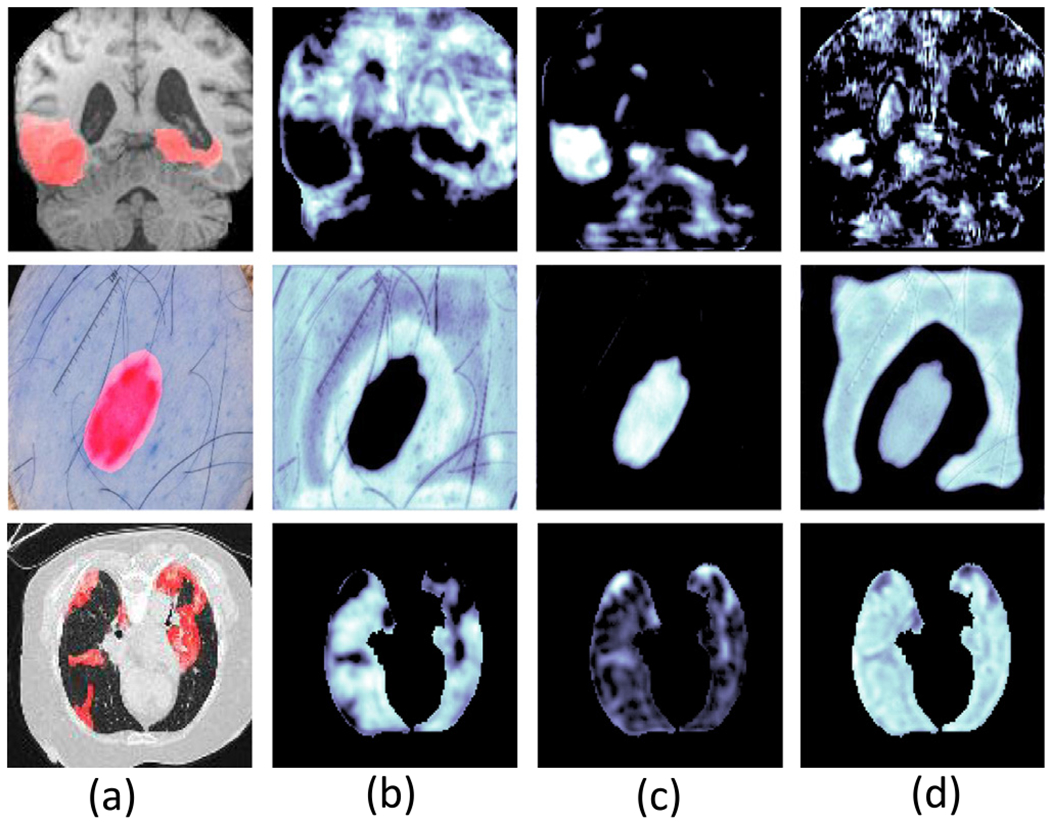
Visualization of the input images with object masks (a) and three corresponding deep features (b)–(d) extracted from three convolutional units. (b) shows that the activated values are on the background pixels/voxels, (c) shows the activated values are on the object pixels/voxels and (d) shows the activated values are on both object and background pixels/voxels.