
Fig. 1: Model Variants:
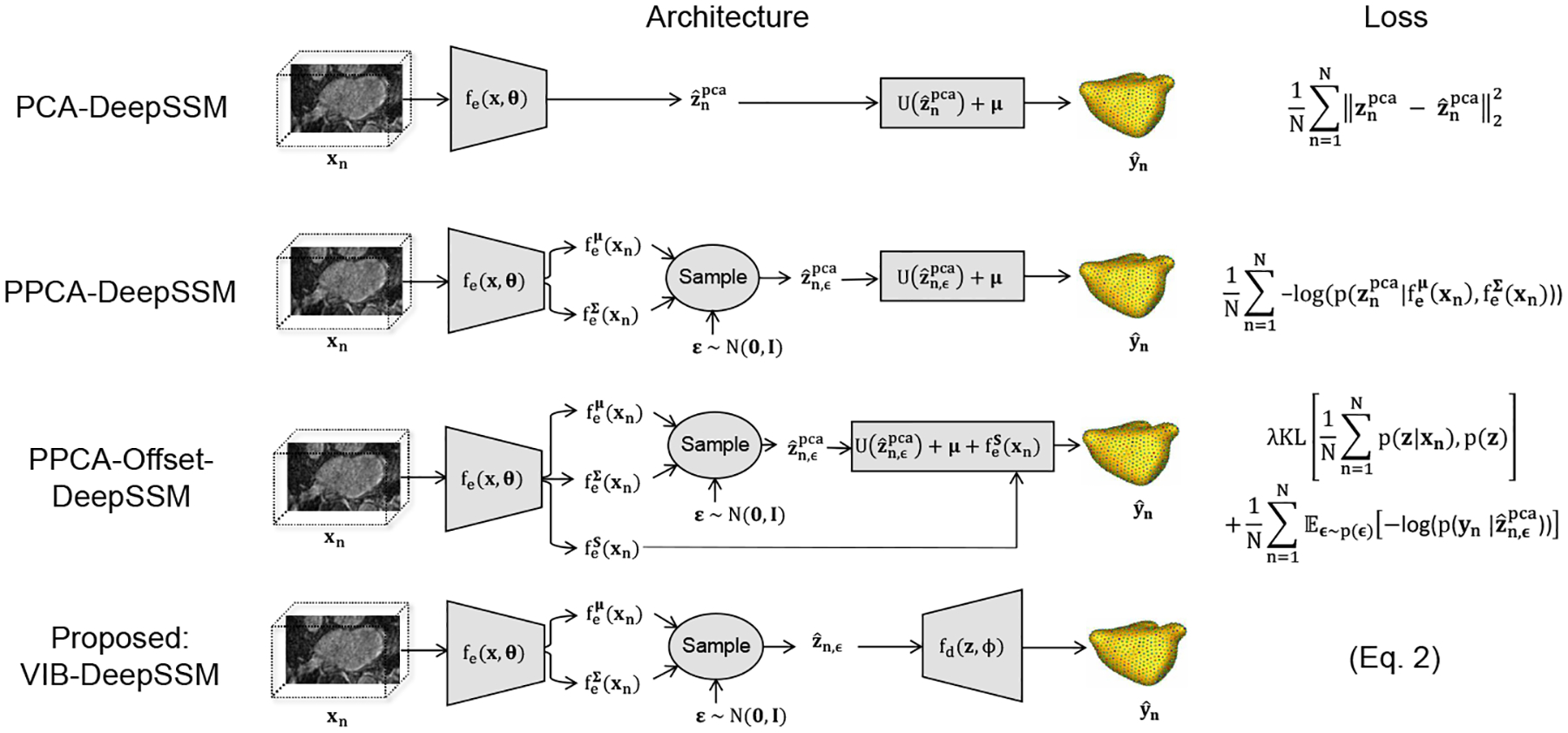
Architecture and loss of the proposed method and baseline models in comparison are shown. In each case, the encoder has the same architecture as in DeepSSM [6]; five convolutional layers with batch normalization followed by two fully connected layers. Only the output size of the last layer of the encoder is variant-dependent. In VIB-DeepSSM, the decoder fd(z;φ) is comprised of three fully connected layers with non-linear activations.