
Fig. 1 |. Cross-cultural regularities in infant-directed vocalizations.
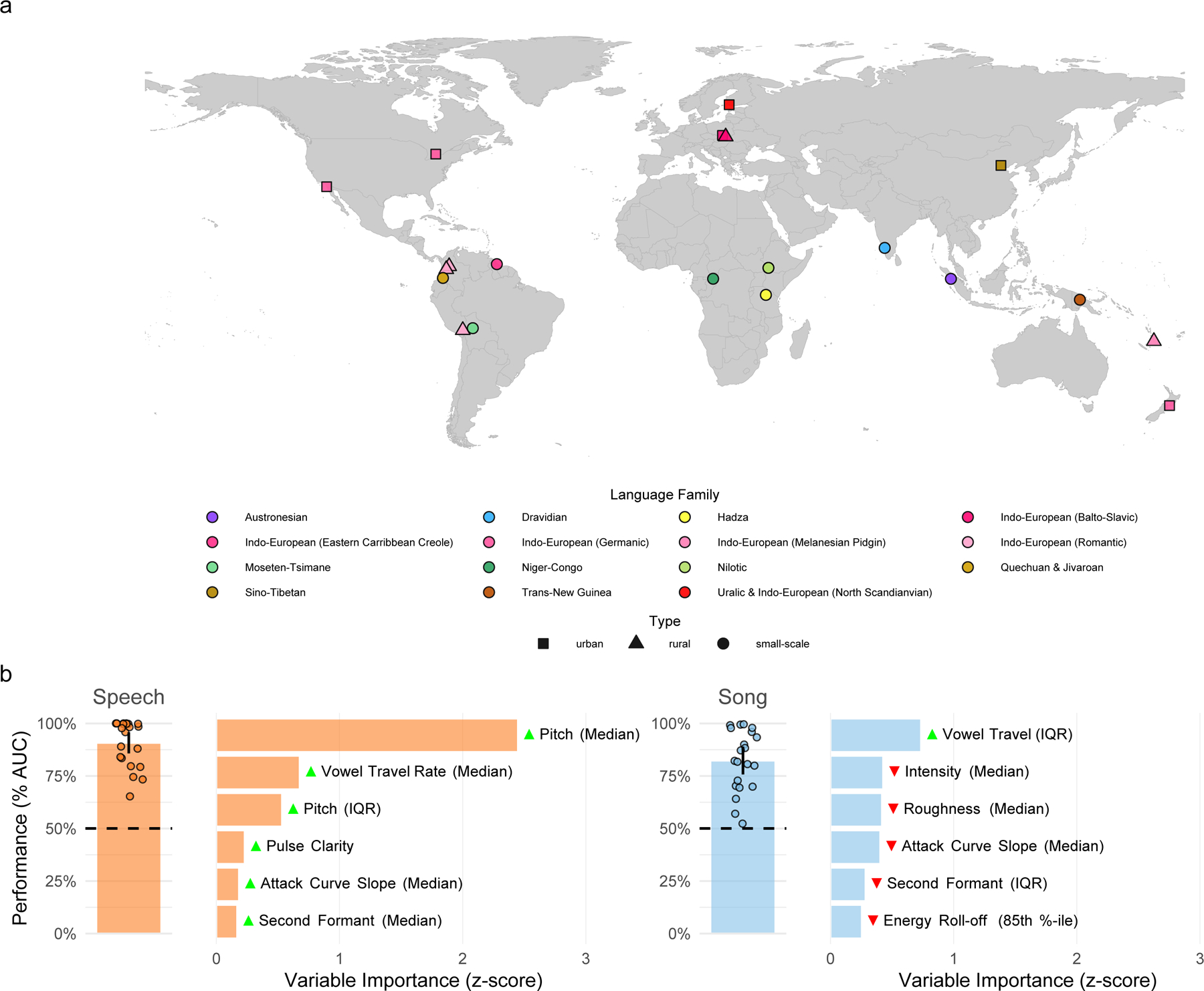
a, We recorded examples of speech and song from 21 urban, rural, or small-scale societies, in many languages. The map indicates the approximate locations of each society and is color-coded by the language family or sub-group represented by the society. b, Machine-learning classification demonstrates the stereotyped acoustics of infant-directed speech and song. We trained two least absolute shrinkage and selection operator (LASSO) models, one for speech and one for song, to classify whether recordings were infant-directed or adult-directed on the basis of their acoustic features. These predictors were regularized using fieldsite-wise cross-validation, such that the model optimally classified infant-directedness across all 21 societies studied. The vertical bars represent the mean classification performance across societies (n = 21 societies for both speech and song; quantified via receiver operating characteristic/area under the curve; AUC); the error bars represent 95% confidence intervals of the mean; the points represent the performance estimate for each fieldsite; and the horizontal dashed lines indicate chance level of 50% AUC. The horizontal bars show the six acoustic features with the largest influence in each classifier; the green and red triangles indicate the direction of the effect, e.g., with median pitch having a large, positive effect on classification of infant-directed speech. The full results of the variable selection procedure are in Supplementary Table 2, with further details in Methods.