
Fig. 3 |. Naïve listeners distinguish infant-directed vocalizations from adult-directed vocalizations across cultures.
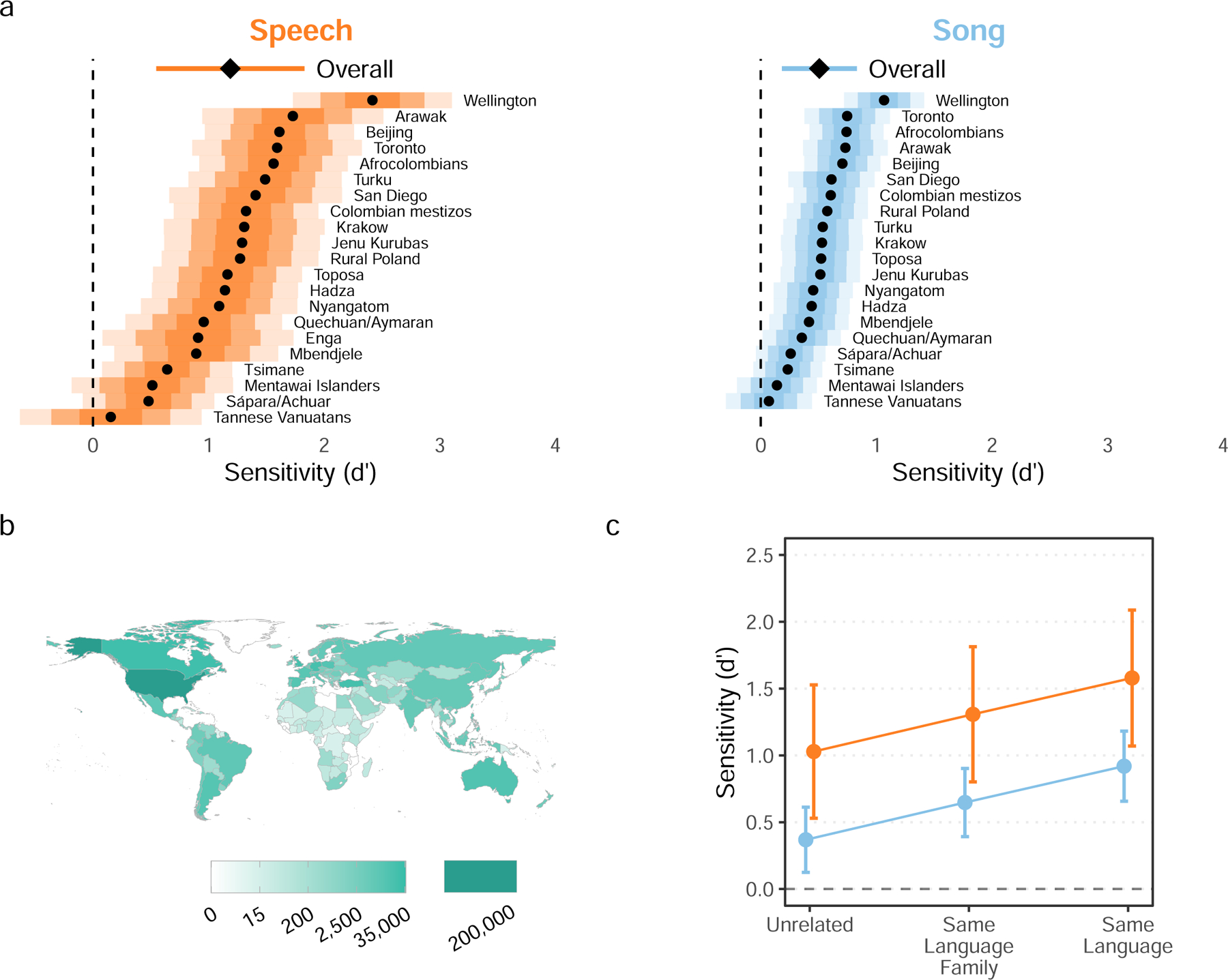
Participants listened to vocalizations drawn at random from the corpus, viewing the prompt “Someone is speaking or singing. Who do you think they are singing or speaking to?” They could respond with either “adult” or “baby” (Extended Data Fig. 3). From these ratings (after exclusion n = 473 song recordings; n = 394 speech recordings), we computed listener sensitivity (d′). a, Listeners reliably detected infant-directedness in both speech and song, overall (indicated by the diamonds, with 95% confidence intervals indicated by the horizontal lines), and across many fieldsites (indicated by the black dots), although the strength of the fieldsite-wise effects varied substantially (see the distance between the vertical dashed line and the black dots; the shaded regions represent 50%, 80%, and 95% confidence intervals, in increasing order of lightness). Note that one fieldsite-wise d′ could not be estimated for song; complete statistical reporting is in Supplementary Table 5. b, The participants in the citizen-science experiment hailed from many countries; the gradients indicate the total number of vocalization ratings gathered from each country. c, The main effects held across different combinations of the linguistic backgrounds of vocalizer and listener. We split all trials from the main experiment into three groups: those where a language the listener spoke fluently was the same as the language of the vocalization (n = 82,094; those where a language the listener spoke fluently was in the same major language family as the language of the vocalization (n = 110,664), and those with neither type of relation (n = 285,378). The plot shows the estimated marginal effects of a mixed-effects model predicting d′ values across language and music examples, after adjusting for fieldsite-level effects. The error bars represent 95% confidence-intervals of the mean. In all three cases, the main effects replicated; increases in linguistic relatedness corresponded with increases in sensitivity.