
Extended Data Fig. 1 |. Variation across societies of infant-directed alterations.
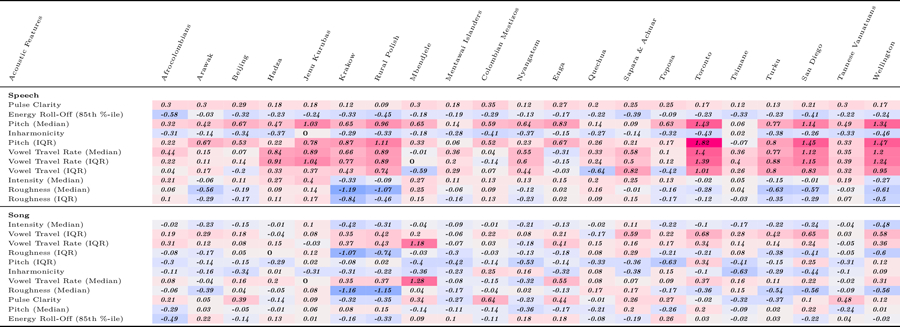
Estimated differences between infant-directed and adult-directed vocalizations, for acoustic feature, in each fieldsite (corresponding with the doughnut plots in Fig. 2). The estimates are derived from the random-effect components of the mixed-effects model reported in the main text. Cells of the table are shaded to facilitate the visibility of corpus-wide consistency (or inconsistency): redder cells represent features where infant-directed vocalizations have higher estimates than adult-directed vocalizations and bluer cells represent features with the reverse pattern. Within speech and song, acoustic features are ordered by their degree of cross-cultural regularity; some features showed the same direction of effect in all 21 societies (for example, for speech, median pitch and pitch variability), whereas others were more variable.