
Extended Data Fig. 2 |. Principal-components analysis of acoustic features.
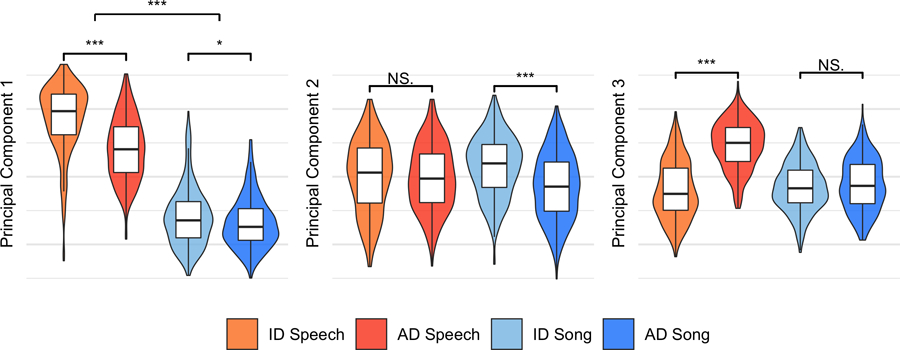
As an alternative approach to the acoustics data, we ran a principal-components analysis on the full 94 acoustic variables, to test whether an unsupervised method also yielded opposing trends in acoustic features across the different vocalization types. It did. The first three components explained 39% of total variability in the acoustic features. Moreover, the clearest differences between vocalization types accorded with the LASSO and mixed-effects modelling (Figs. 1b and 2). The first principal component most strongly differentiated speech and song, overall; the second most strongly differentiated infant-directed song from adult-directed song; and the third most strongly differentiated infant-directed speech from adult-directed speech. The violins indicate kernel density estimations and the boxplots represent the medians (centres), interquartile ranges (bounds of boxes) and 1.5xIQR (whiskers). Significance values are computed via two-sided Wilcoxon signed-rank tests (n = 1,570 recordings); *p < 0.05, **p < 0.01, ***p < 0.001. Feature loadings are in Supplementary Table 7.