
Extended Data Fig. 5 |. Response-time analysis of naive listener experiment.
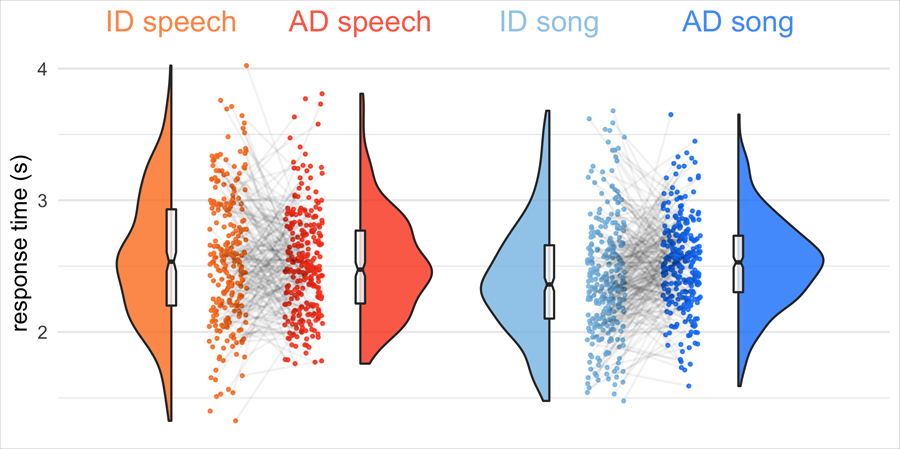
We recorded the response times of participants in their mobile or desktop browsers, using jsPsych (see Methods), and asked whether, when responding correctly, participants more rapidly detected infant-directedness in speech or song. They did not: a mixed-effects regression predicting the difference in response time between infant-directed and adult-directed vocalizations (within speech or song), adjusting hierarchically for fieldsite and world region, yielded no significant differences (ps > .05 from two-sided linear combination tests; no adjustments made for multiple comparisons). The grey points represent average ratings for each of the recordings in the corpus that were used in the experiment (after exclusions, n = 1,138 recordings from the corpus of 1,615), split by speech and song; the grey lines connecting the points indicate the pairs of vocalizations produced by the same participant; the half-violins are kernel density estimations; and the boxplots represent the medians, interquartile ranges and 95% confidence intervals (indicated by the notches).