
Figure 1.
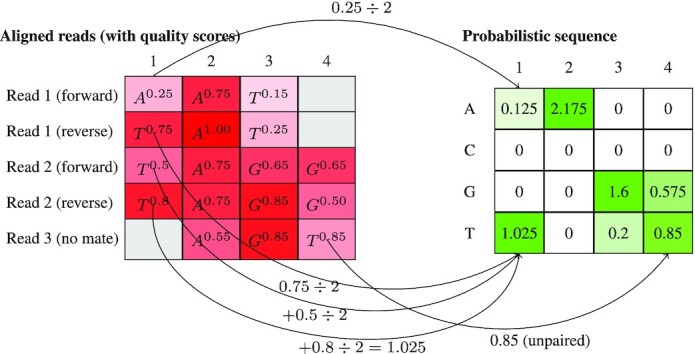
An illustration of constructing a probabilistic sequence from a SAM file. Each row in the matrix on the left is a graphical representation of a short read, and the superscript represents the quality score (from 0 to 1). Half of the quality score from paired end reads is added to the relevant cell in the matrix on the right. In both matrices, the column numbering represents a position on the reference genome. Note that this is an intermediate step prior to ensuring that the columns sum to 1. In the probabilistic sequence, we can see that the consensus sequence would be TAGT, but TAGG is also a very likely sequence given the quality scores.