
Figure 2. Whole-slide learning method - diagram:
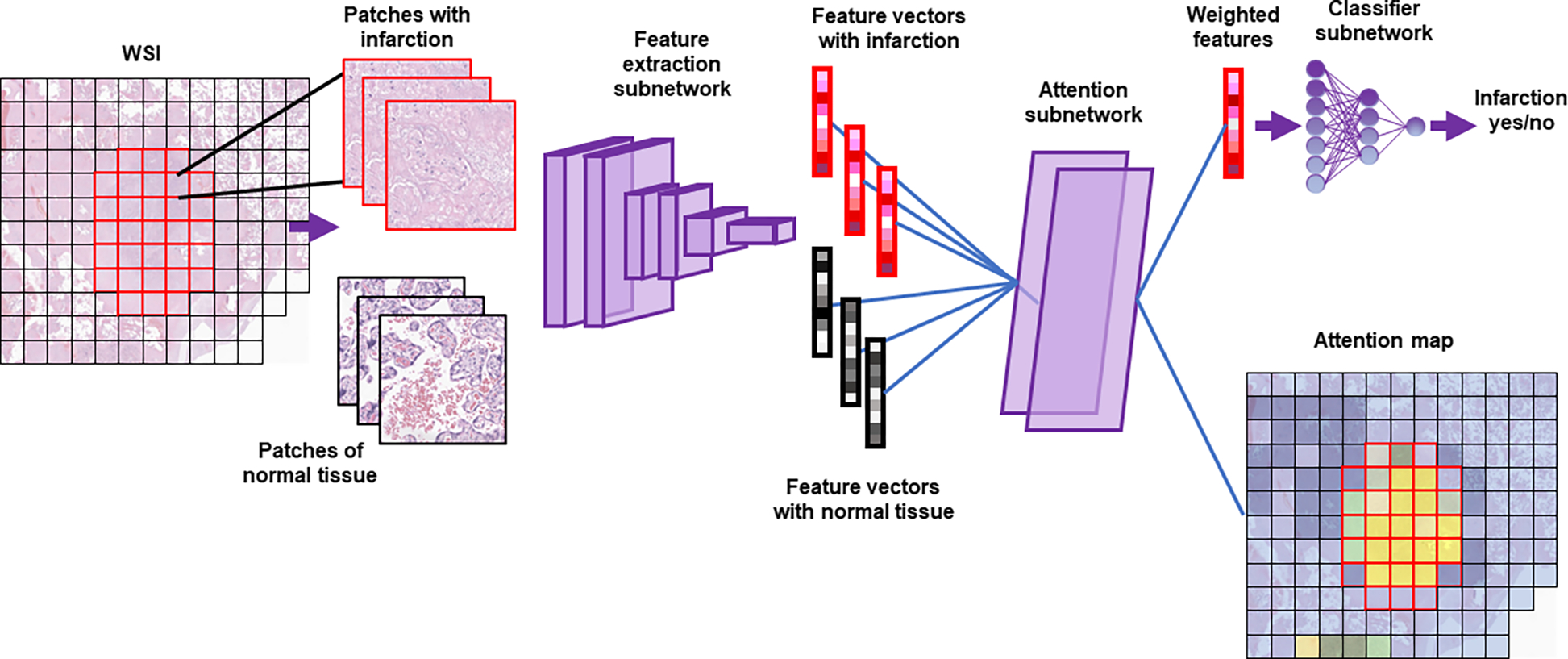
A whole slide image (WSI) is divided into a set of smaller images (patches). Images pass through a feature extraction network to become feature vectors. The attention subnetwork generates an attention value for each vector and uses that value to produce a weighted average (weighted features). The classifier subnetwork then generates a single label for the whole slide. Attention values for each patch are plotted on the attention map (blue-yellow: low-high attention). Note that a separate attention subnetwork and classifier subnetwork exist for each diagnosis, though only that for infarction is shown.