
Figure 4.
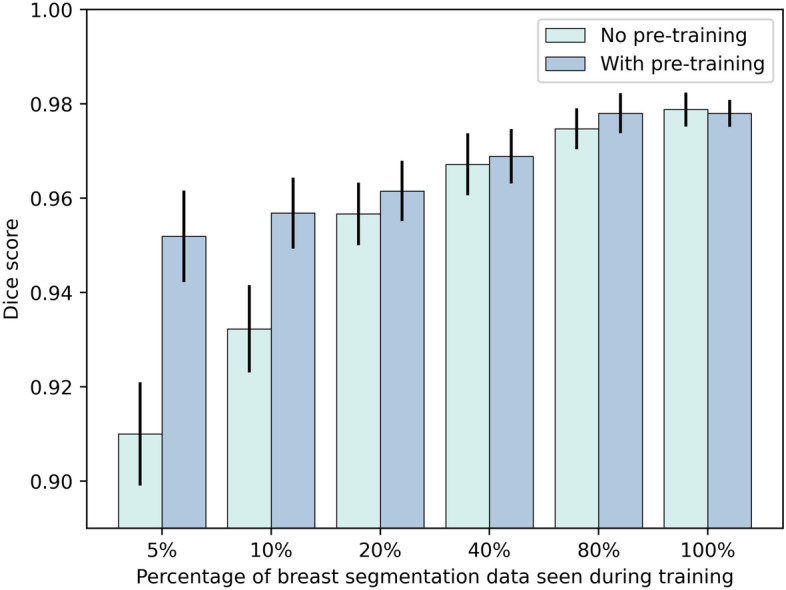
Comparison of the performance of the Swin UNETR in terms of the Dice score for breast segmentation when supplied with synthetic image data (n = 2000) during a self-supervised pre-training setting (“With pre-training”) and when no pre-training (“No pre-training”) is performed. After the optional self-supervised pre-training step, the model is finetuned with 5%, 10%, 20%, 40%, 80%, or 100% of the available internal data with corresponding breast segmentation outlines used as the ground truth (n = 200). We find that the synthetic data generated using a dataset of another institution can substantially improve the Dice score on the internal dataset when only limited data are available for training. Error bars show the standard deviation extracted through bootstrapping (n = 1000).