

Abstract
Among the most striking features of retinal organization is the grouping of its output neurons, the retinal ganglion cells (RGCs), into a diversity of functional types. Each of these types exhibits a mosaic-like organization of receptive fields (RFs) that tiles the retina and visual space. Previous work has shown that many features of RGC organization, including the existence of ON and OFF cell types, the structure of spatial RFs, and their relative arrangement, can be predicted on the basis of efficient coding theory. This theory posits that the nervous system is organized to maximize information in its encoding of stimuli while minimizing metabolic costs. Here, we use efficient coding theory to present a comprehensive account of mosaic organization in the case of natural videos as the retinal channel capacity—the number of simulated RGCs available for encoding—is varied. We show that mosaic density increases with channel capacity up to a series of critical points at which, surprisingly, new cell types emerge. Each successive cell type focuses on increasingly high temporal frequencies and integrates signals over larger spatial areas. In addition, we show theoretically and in simulation that a transition from mosaic alignment to anti-alignment across pairs of cell types is observed with increasing output noise and decreasing input noise. Together, these results offer a unified perspective on the relationship between retinal mosaics, efficient coding, and channel capacity that can help to explain the stunning functional diversity of retinal cell types.
1. Introduction
The retina is one of the most intensely studied neural circuits, yet we still lack a computational understanding of its organization in relation to its function. At a structural level, the retina forms a three-layer circuit, with its primary feedforward pathway consisting of photoreceptors to bipolar cells to retinal ganglion cells (RGCs), the axons of which form the optic nerve [1]. RGCs can be divided into 30–50 functionally distinct cell types (depending on species) with each cell responsive to a localized area of visual space (its receptive field (RF)), and the collection of RFs for each type tiling space to form a “mosaic” [2, 3, 4, 5]. Each mosaic represents the extraction of a specific type of information across the visual scene by a particular cell type, with different mosaics responding to light increments or decrements (ON and OFF cells), high or low spatial and temporal frequencies, color, motion, and a host of other features. While much is known about the response properties of each RGC type, the computational principles that drive RGC diversity remain unclear.
Efficient coding theory has proven one of the most powerful ideas for understanding retinal organization and sensory processing. Efficient coding posits that the nervous system attempts to encode sensory input by minimizing redundancy subject to biological costs and constraints [6, 7]. As more commonly formulated, it seeks to maximize the mutual information between sensory data and neural representations, with the most common cost in the retinal case being the energetic cost of action potentials transmitted by the RGCs. Despite its simplicity, this principle has proven useful, predicting the center-surround structure of RFs [8], the frequency response profile of contrast sensitivity [9], the structure of retinal mosaics [10, 11], the role of nonlinear rectification [12], different spatiotemporal kernels [13], and inter-mosaic arrangements [14, 15].
While previous studies have largely focused on either spatial or temporal aspects of efficient coding, we optimize an efficient coding model of retinal processing in both space and time to natural videos [16]. We systematically varied the number of cells available to the system and found that larger numbers of available cells led to more cell types. Each of these functionally distinct types formed its own mosaic of RFs that tiled space. We show that when and how new cell types emerge and form mosaics is the result of tradeoffs between power constraints and the benefits of specialized encoding that shift as more cells are available to the system. We show that cell types begin by capturing low-frequency temporal information and capture increasingly higher-frequency temporal information over larger spatial RFs as new cell types form. Finally, we investigated the relative arrangement of these mosaics and their dependence on noise. We show that mosaic pairs can be aligned or anti-aligned depending on input and output noise in the system [14]. Together, these results demonstrate for the first time how efficient coding principles can explain, even predict, the formation of cell types and which types are most informative when channel capacity is limited.
2. Model
The model we develop is an extension of [14], a retinal model for efficient coding of natural images, which is based on a mutual information maximization objective proposed in [10]. The retinal model takes -pixel patches of natural images corrupted by input noise , filters these with unit-norm linear kernels representing RGCs, and then feeds the resulting signals through softplus nonlinearities (we used ) with gain and threshold . Finally, these signals are further corrupted by additive output noise , to produce firing rates :
| (1) |
The model learns parameters , and to maximize the mutual information between the inputs and the outputs , under a mean firing rate constraint [10, 14]:
| (2) |
| (3) |
Here is the covariance matrix of the input distribution, contains the filters as its columns, the gain matrix , and the noise covariances are and . This objective is equivalent to the formulation in [10], which assumes normally distributed inputs and locally linear responses in order to approximate the mutual information in a closed form.
Here, we extend this model to time-varying inputs representing natural videos (Figure 1A–B), which are convolved with linear spatiotemporal kernels :
| (4) |
Figure 1:
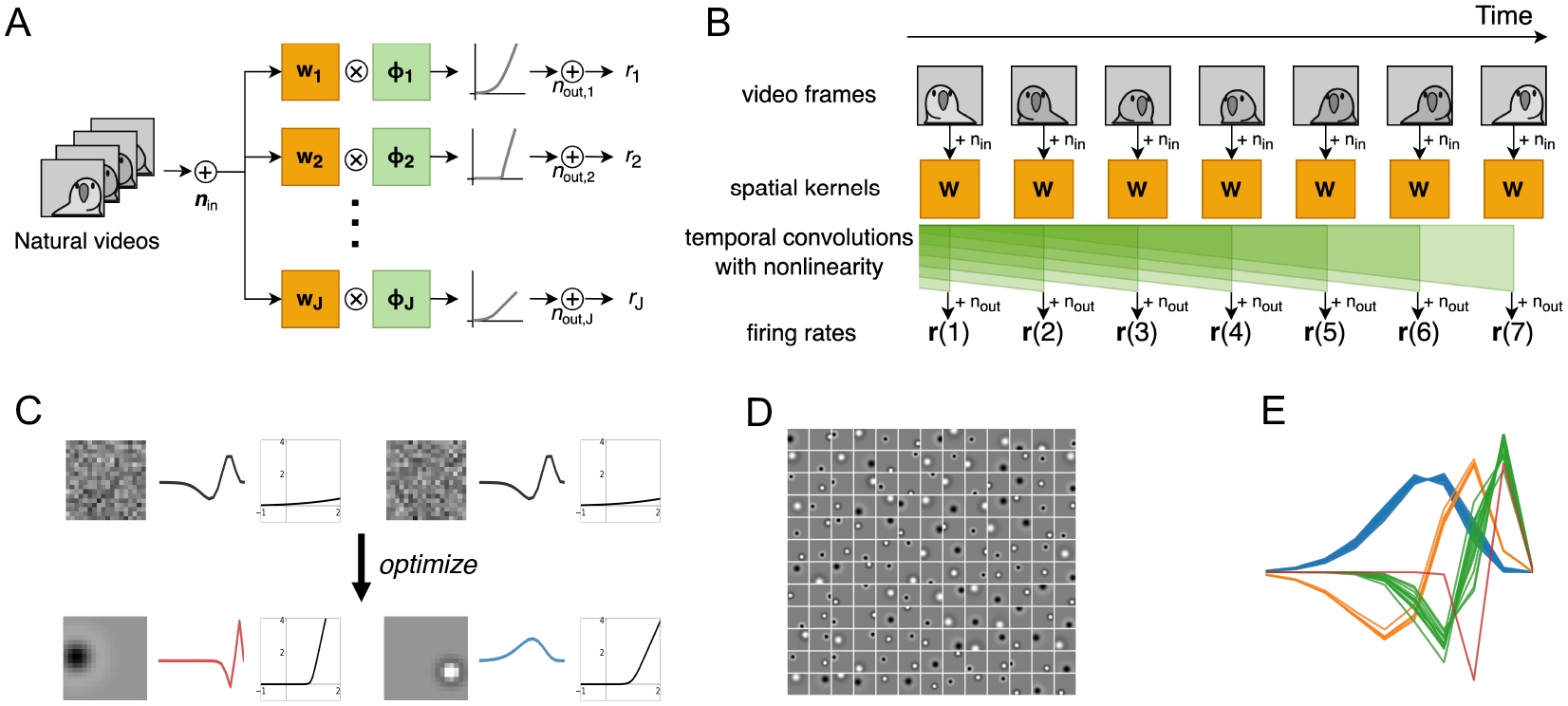
ON and OFF RF mosaics and their temporal kernels are predicted by efficient coding of natural videos. (A) Frames of natural videos plus input noise are linearly filtered with the spatial kernels and then passed through one-dimensional temporal convolutions followed by a nonlinearity, resulting firing rates for each of RGCs. (B) The same calculations shown along the time axis, visualizing the temporal convolutions. (C) Examples of initial and optimized spatial filters, temporal filters, and nonlinearities: (left) fast OFF kernel, (right) slow ON kernel. (D) Unconstrained spatial filters learned center-surround shapes, about half of which are ON RFs. (E) Temporal filters using the parameterization (6) converged to four distinct clusters.
We additionally assume that the convolutional kernels are separable in time and space:
| (5) |
and the temporal kernels are unit-norm impulse responses taking the following parametric form:
| (6) |
where are learnable parameters, and is fixed. Previous work assumed an unconstrained form for these filters, adding zero-padding before and after the model’s image inputs to produce the characteristic shape of the temporal filters in primate midget and parasol cells [13], but this zero-padding represents a biologically implausible constraint, and the results fail to correctly reproduce the observed delay in retinal responses [17, 18, 19]. Rather, optimizing (2) with unconstrained temporal filters produces a filter bank uniformly tiling time (Supplementary Figure 4).
By contrast, (6) is motivated by the arguments of [20], which showed that the optimal minimum-phase temporal filters of retinal bipolar cells, the inputs to the RGCs, take the form
| (7) |
when . Thus, we model RGC temporal filters as a linear combination of these forms. In practice, we take only two filters and use rather than , since these have been shown to perform well in capturing observed retinal responses [19]. The results produced by more filters or different exponents are qualitatively unchanged (Supplementary Figure 7). For training on video data, we use discrete temporal filters and convolutions with . Finally, while unconstrained spatial kernels converge to characteristic center-surround shapes under optimization of (2) (Figure 1C), for computational efficiency and stability, we parameterized these filters using a radially-symmetric difference of Gaussians
| (8) |
where measures the spatial distance to the center of the RF, and the parameters that determine the center location and spatial kernel shape are potentially different for each RGC . The result of optimizing (2) using these forms is a set of spatial and temporal kernels (Figure 1D–E) that replicate experimentally-observed shapes and spatial RF tiling.
3. Efficient coding as a function of channel capacity: linear theory
Before presenting results from our numerical experiments optimizing the model (2, 3), we begin by deriving intuitions about its behavior by studing the case of linear filters analytically. That is, we assume a single gain for all cells, no bias , and a linear transfer function . As we will see, this linear analysis correctly predicts the same types of mosaic formation and filling observed in the full nonlinear model. Here, we sketch the main results, deferring full details to Appendix A.
3.1. Linear model in the infinite retina limit
For analytical simplicity, we begin by assuming an infinite retina on which RFs form mosaics described by a regular lattice. Under these conditions, we can write the log determinants in (2) as integrals and optimize over the unnormalized filter subject to a power constraint:
| (9) |
where is the Fourier transform of the stationary image covariance , the integral is over all frequencies unique up to aliasing caused by the spatial regularity of the mosaic, and the sums over account for aliased frequencies (Appendix A.1). In [8], the range is used for the integral, corresponding to a one-dimensional lattice and units of mosaic spacing .
Now, solving the optimization in (9) results in a spatial kernel with the spectral form (Appendix A.2)
| (10) |
where and is chosen to enforce the constraint on total power. This is exactly the solution found in [8], linking it (in the linear case) to the model of [10, 11]. Note, however, that (10) is only nonzero within , since RF spacing sets an upper limit on the passband of the resulting filters.
The generalization of this formulation to the spacetime case is straightforward. Given a spacetime stationary image spectrum and radially-symmetric, causal filter , the same infinite retina limit as above requires calculating determinants across both neurons and time points of matrices with entries of the form
| (11) |
Again, such matrices can be diagonalized in the Fourier basis, with the result that the optimal spacetime filter once again takes the form (10) with the substitutions (Appendix A.3). Figure 2A depicts the frequency response of this filter in spatial dimensions, with corresponding spatial and temporal sections plotted in Figures 2 B–C.
Figure 2:
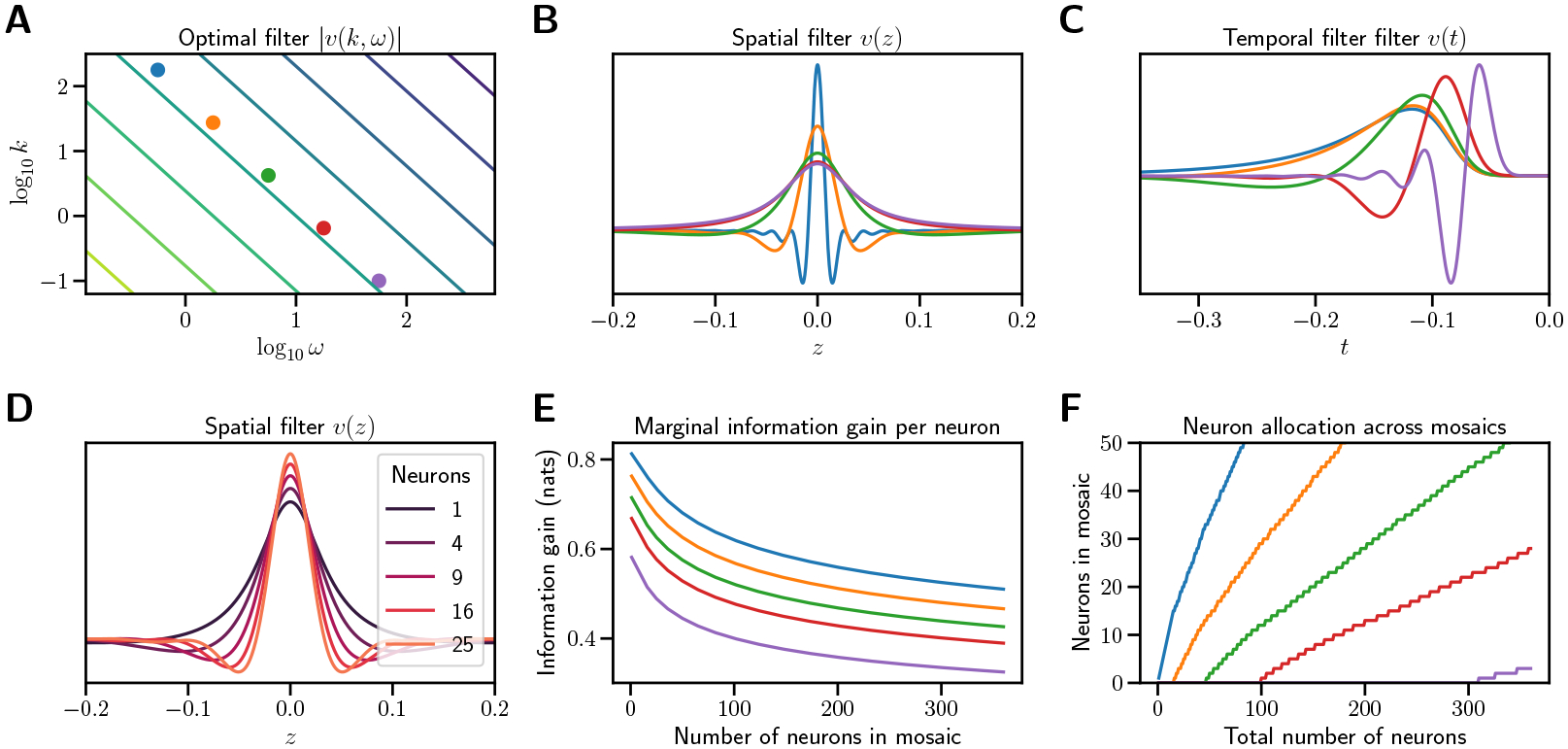
Optimal filters in the linear spacetime case. (A) Spectrum of the optimal linear spacetime filter in spatial dimension. Contour lines indicate constant (log) power. (B) Spatial filters at representative temporal frequencies. Each filter represents a vertical section at the correspondingly colored dot in A. (C) Temporal filters at representative spatial frequencies. Each filter represents a horizontal section at the correspondingly colored dot in A. (D) Spatial filters at for increasing numbers of RGCs . The spatial extent of the center narrows with more RGCs added to the mosaic. (E) Gain in information per RGC added to each mosaic as a function of current RGC number . New cell types begin when the marginal benefit of adding an RGC to an existing mosaic equals the benefit of adding the first RGC of a new cell type. Color indicates , the temporal frequency of the narrow-band filter. (F) Total number of RGCs in each mosaic as a function of total RGCs across all mosaics. As new cell types arise and form mosaics, new RGCs are allocated to existing mosaics at a decreasing rate. For both plots, , and . Details of calculations in Appendix A.5.
3.2. Multiple cell types and the effects of channel capacity
Up to this point, we have only considered a single type of filter , corresponding to a single cell type. However, multiple cell types might increase the coding efficiency of the entire retina if they specialize, devoting their limited energy budget to non-overlapping regions of frequency space. Indeed, optimal encoding in the multi-cell-type case selects filters and that satisfy , corresponding encoding independent visual information (Appendix A.4).
This result naturally raises two questions: First, how many filter types are optimal? And second, how should a given budget of RGCs be allocated across multiple filter types? As detailed in Appendix A.5, we can proceed by analyzing the case of a finite retina in the Fourier domain, approximating the information encoded by a mosaic of RGCs with spatial filters given by (10) and nonoverlapping bandpass temporal filters that divide the available spectrum (e.g., Figure 2 B, C). Following [21], we approximate the correlation spectrum of images by the factorized power law with and find that in this case, the optimal filter response exhibits two regimes as a function of spatial frequency (Supplementary Figure 1A): First, below , the optimal filter is separable and log-linear, and the filtered image spectrum is white:
where , the Lagrange multiplier in (9) that enforces the power constraint, scales as for small values of maximal power and for larger values (Supplementary Figure 1D). Second, for , the filter response decreases as until reaching its upper cutoff at , with the filtered image spectrum falling off at the same rate (Supplementary Figure 1B).
But what do these regimes have to do with mosaic formation? The link between the two is given by the fact that, for a finite retina with regularly spaced RFs, adding RGCs decreases the distance between RF centers and so increases the resolving power of the mosaic. That is, the maximal value of grows roughly as in , such that larger numbers of RGCs capture more information at increasingly higher spatial frequencies (Supplementary Figure 1A). However, while information gain is roughly uniform in the whitening regime, it falls off sharply for (Supplementary Figure 1C), suggesting the interpretation that the regime is a “mosaic filling” phase in which information accumulates almost linearly as RFs capture new locations in visual space, while the regime constitutes a “compression phase” in which information gains are slower as RFs shrink to accommodate higher numbers (Figure 2D). Indeed, one can derive the scaling of total information as a function of :
| (12) |
where is the power budget per RGC and is the RGC number corresponding to . Thus, mosaic filling exhibits diminishing marginal returns (Figure 2E), such that new cell types are favored when the marginal gain for growing mosaics with lower temporal frequency drops below the gain from initiating a new cell type specialized for higher temporal frequencies. Moreover, the difference between these gain curves implies that new RFs are not added to all mosaics at equal rates, but in proportion to their marginal information (Figure 2F). As we demonstrate in the next section, these features of cell type and mosaic formation continue to hold in the full nonlinear model in simulation.
4. Experiments
We analyzed the characteristics of the optimal spatiotemporal RFs obtained from the model (2, 3) trained on videos from the Chicago Motion Database [22]. Model parameters for spatial kernels, temporal kernels, and the nonlinearities were jointly optimized using Adam [23] to maximize (2) subject to the mean firing rate constraint (3) using the augmented Lagrangian method with the quadratic penalty [24]. Further technical details of model training are in Appendix E. All model code and reproducible examples are available at https://github.com/pearsonlab/efficientcoding.
As previously noted, the power spectral density of natural videos can be well approximated by a product of spatial and temporal power-law densities, implying an anticorrelation between high spatial and temporal frequency content [21]. Supplementary Figure 5 shows the data spectrum of the videos in our experiments is also well-approximated by separable power-law fits. To examine the effect of these statistics on the learned RFs, we divided the dataset into four progressively smaller subsets by the proportion of their temporal spectral content below 3 Hz, their spectral attenuation. Using values of 70%, 80%, and 90% then yielded a progression of datasets ranging from most videos to only the slowest videos (Figure 3A, B). Indeed, when the model was trained on these progressively slower data subsets, it produced only temporal smoothing filters, whereas the same model trained on all videos produced a variety of “fast” temporal filter types (Figure 3C). We also note that these experiments used unconstrained spatial kernels in place of (8), yet still converged on spatial RFs with typical center-surround structure as in [10, 15, 14]. Thus, these preliminary experiments suggest that the optimal encoding strategy—in particular, the number of distinct cell types found—depends critically on the statistics of the video distribution to be encoded.
Figure 3:
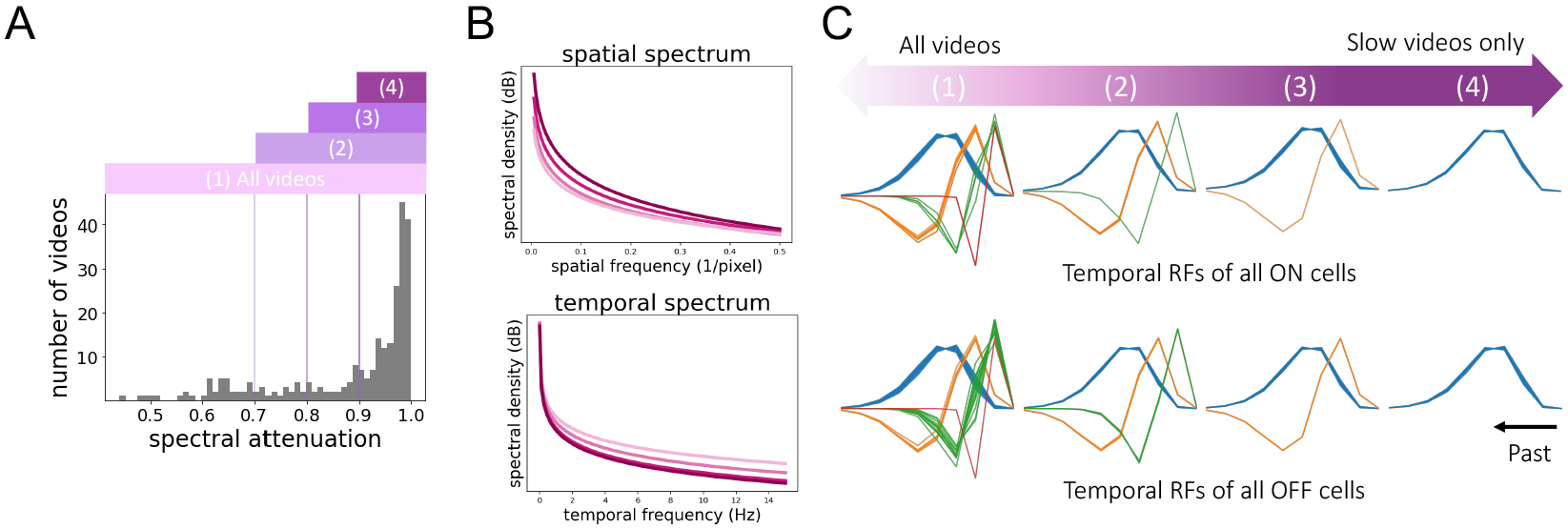
Statistics of natural videos affect learned RFs. (A) Histogram of spectral attenuation (fraction of power < 3 Hz) for each video clip from the Chicago Motion Database. A significant portion of the dataset exhibits predominaly low-frequency spectral content in time. Videos with spectral attenuation above 0.9, 0.8, and 0.7, are denoted (4), (3), and (2), respectively, while (1) refers to all videos in the dataset. (B) Spatial (top) and temporal (bottom) spectral density of the four subsets. (C) Temporal filters learned by training on each of the four subsets. Training on slow videos produced only smoothing kernels, while training on all videos produced a variety of temporal filters.
4.1. Mosaics fill in order of temporal frequency
As the number of RGCs available to the model increased, we observed the formation of new cell types with new spectral properties (Figure 4). We characterized the learned filters for each RGC in terms of their spectral centroid, defined as the center of mass of the Fourier (spatial) or Discrete Cosine (temporal) transform. Despite the fact that each model RGC was given its own spatial and temporal filter parameters (8, 6), the learned filter shapes strongly clustered, forming mosaics with nearly uniform response properties (Figure 4A–C). Critically, the emergence of new cell types shifted the spectral responses of previously established ones, with new cell types compressing the spectral windows of one another as they further specialized. Moreover, mosaic density increased with increasing RGC number, shifting the centroids of early mosaics toward increasingly higher spatial frequencies. This is also apparent in the forms of the typical learned filters and their power spectra: new filters selected for increasingly high-frequency content in the temporal domain (Figure 4D).
Figure 4:
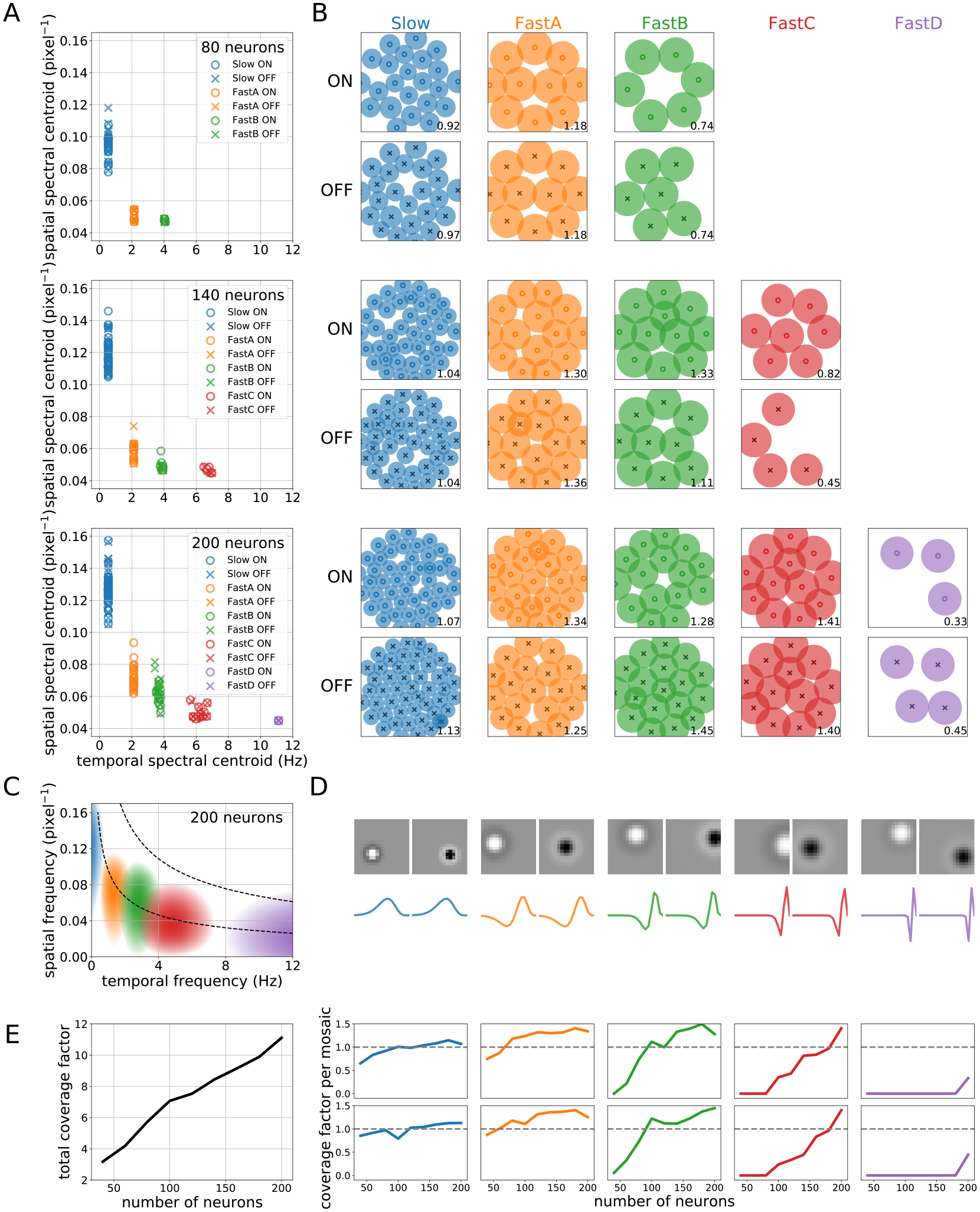
Emergence of new RF types with increasing RGC number. (A) Distribution of spatial and temporal spectral centroids for RGCs. ON and OFF RFs form distinct clusters corresponding to different learned filter types. (B) ON and OFF mosaics corresponding to each cell type. The number in the lower right of each plot is the coverage factor for the mosaic. (C) Power spectral density of a typical kernel in each mosaic for . As predicted, learned kernels filter over roughly nonoverlapping regions of spatiotemporal frequency. Contour lines represent isopower lines of the signal correlation . (D) Learned shapes of example spatial ON and OFF filters (top) and corresponding temporal filters (bottom) from each RF type for the case. (E) Total (left) and per-mosaic (right) coverage factors as the number of RGCs increases from 40 to 200. New mosaics increase coverage linearly with the number of RFs, while nearly full mosaics see diminishing returns in coverage from density increases. See Supplementary Figures 8–9 for similar plots for all RGC numbers.
We likewise analyzed the coverage factors of both individual mosaics and the entire collection, defined as the proportion of visual space covered by the learned RFs. More specifically, we defined the spatial radius of an RF as the distance from its center at which intensity dropped to 20% of its peak and used this area to compute a coverage factor, the ratio of total RF area to total visual space ( of the square’s area due to circular masking). Since coverage factors depend not simply on RGC number but on RF density, they provide an alternative measure of the effective number of distinct cell types learned by the model. As Figure 4E shows, coverage increases nearly linearly with RGC number, while coverage for newly formed mosaics increases linearly before leveling off. In other words, new cell types initially increase coverage of visual space by adding new RFs, but marginal gains in coverage diminish as density increases. In all cases, the model dynamically adjusts the number of learned cell types and the proportion of RGCs assigned to them as channel capacity increases.
4.2. Phase changes in mosaic arrangement
In addition to retinal organization at the level of mosaics, a pair of recent papers reported both experimental [15] and theoretical [14] evidence for an additional degree of freedom in optimizing information encoding: the relative arrangement of ON and OFF mosaics. Jun et al. studied this for the case of natural images in [14], demonstrating that the optimal configuration of ON and OFF mosaics is alignment (RFs co-located) at low output noise levels and anti-alignment (OFF RFs between ON RFs and vice-versa) under higher levels of retinal output noise. Moreover, this transition is abrupt, constituting a phase change in optimal mosaic arrangement.
We thus asked whether learned mosaics exhibited a similar phase transition for natural video encoding. To do so, following [14], we repeatedly optimized a small model (, 7 ON, 7 OFF) for multiple learned filter types while systematically varying levels of input and output noise. In each case, one ON-OFF pair was fixed at the center of the space, while the locations of the others were allowed to vary. We used RF size pixels for Slow and for FastA and FastB cell types to allow the size of spatial kernels to be similar to those of the previous experiments, and we imposed the additional constraint that the shape parameters , and in (8) be shared across RGCs.
Under these conditions, the six free pairs of RFs converged to either aligned (overlapping) or anti-aligned (alternating) positions along the edges of the circular visual space, allowing for a straightforward examination of the effect of input and output noises on mosaic arrangement. Figure 5A–C shows that the phase transition boundaries closely follow the pattern observed in [14]: increasing output noise shifts the optimal configuration from alignment to anti-alignment. Moreover, for each of the tested filters, increasing input noise discourages this transition. This effect also follows from the analysis presented in [14], since higher input noise increases coactivation of nearby pairs of RFs, requiring larger thresholds to render ON-OFF pairs approximately indpendent (Appendix B).
Figure 5:
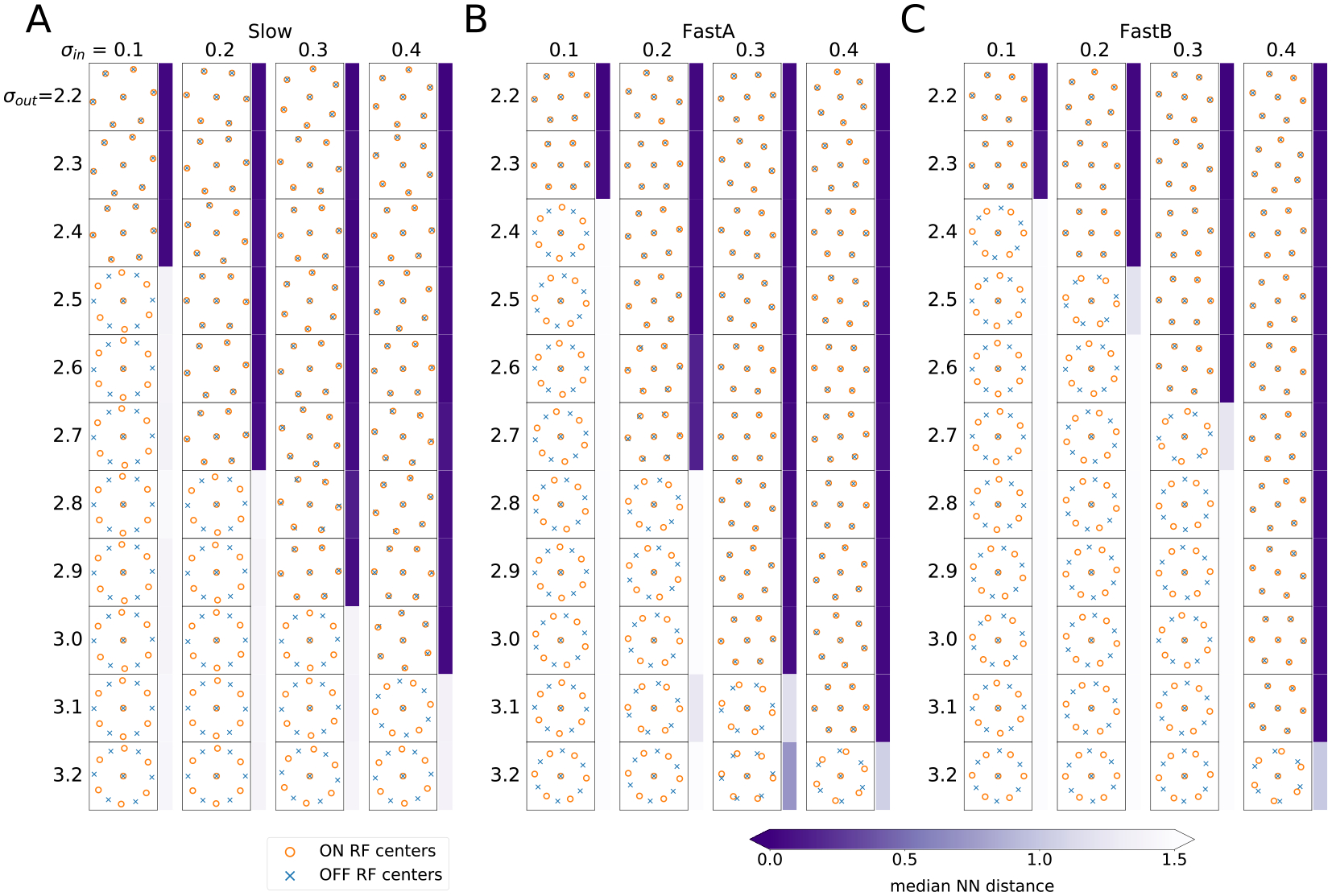
Learned mosaics exhibit a phase transition as a function of input and output noise. (A-C) Spatial kernel centers for Slow (A), FastA (B), and FastB (C) as a function of and . In all three cases, the optimal configuration changes from aligned to anti-aligned when output noise increases or input noise decreases. Blue bars denote alignment as measured by median distance to the nearest RF center of the opposite type.
5. Discussion
Related work:
As reviewed in the introduction, this study builds on a long line of work using efficient coding principles to understand retinal processing. In addition, it is related to work examining encoding of natural videos [25, 22, 16] and prediction in space-time. The most closely related work to this one is that of [13], which also considered efficient coding of natural videos and considered the tradeoffs involved in multiple cell types. Our treatment here differs from that work in several key ways: First, while [13] was concerned with demonstrating that multiple cell types could prove beneficial for encoding (in a framework focused on reconstruction error), that study predetermined the number of cell types and mosaic structure, only optimizing their relative spacing. By contrast, this work is focused on how the number of cell types is dynamically determined, and how the resulting mosaics arrange themselves, as a function of the number of units available for encoding (i.e., the channel capacity). Specifically, we follow previous efficient coding models [8, 9, 10, 11] in maximizing mutual information and do not assume an a priori mosaic arrangement, a particular cell spacing, or a particular number of cell types— all of these emerge via optimization in our formulation. Second, while the computational model of [13] optimized strides for a pair of rectangular arrays of RGCs, we individually optimize RF locations and shapes, allowing us to study changes in optimal RF size and density as new, partial mosaics begin to form. Third, while [13] used zero-padding of natural videos to bias learned temporal filters toward those of observed RGCs, we link the form of temporal RFs to biophysical limits on the filtering properties of bipolar cells, producing temporal filters with the delay properties observed in real data. Finally, while [13] only considered a single noise source in their model, we consider noise in both photoreceptor responses (input noise) and RGC responses (output noise), allowing us to investigate transitions in the optimal relative arrangement of mosaics [14, 15].
We have shown that efficient coding of natural videos produces multiple cell types with complementary RF properties. In addition, we have shown for the first time that the number and characteristics of these cell types depend crucially on the channel capacity: the number of available RGCs. As new simulated RGCs become available, they are initially concentrated into mosaics with more densely packed RFs, improving the spatial frequency bandwidth over which information is encoded. However, as this strategy produces diminishing returns, new cell types encoding higher-frequency temporal features emerge in the optimization process. These new cell types capture information over distinct spatiotemporal frequency bands, and their formation leads to upward shifts in the spatial frequency responses of previously formed cell types. Moreover, pairs of ON and OFF mosaics continue to exhibit the phase transition between alignment and anti-alignment revealed in a purely spatial optimization of efficient coding [14], suggesting that mosaic coordination is a general strategy for increasing coding efficiency. Furthermore, despite the assumptions of this model—linear filtering, separable filters, firing rates instead of spikes—our results are consistent with observed retinal data. For example, RGCs with small spatial RFs exhibit more prolonged temporal integration: they are also more low-pass in their temporal frequency tuning. Second, there is greater variability in the size and shape of spatial RFs at a given retinal location, but temporal RFs exhibit remarkably little variability in our simulations and in data [19]. Thus, these results further testify to the power of efficient coding principles in providing a conceptual framework for understanding the nervous system.
Supplementary Material
Acknowledgments and Disclosure of Funding
This work was supported by NIH/National Eye Institute Grant R01 EY031396.
Footnotes
36th Conference on Neural Information Processing Systems (NeurIPS 2022).
Contributor Information
Na Young Jun, Department of Neurobiology, Duke University, Durham, NC 27710.
Greg D. Field, Department of Neurobiology, Duke University, Durham, NC 27710
John M. Pearson, Department of Biostatistics & Bioinformatics, Department of Neurobiology, Department of Electrical and Computer Engineering, Duke University, Durham, NC 27710
References
- [1].Hoon Mrinalini, Okawa Haruhisa, Santina Luca Della, and Wong Rachel OL. Functional architecture of the retina: development and disease. Progress in retinal and eye research, 42:44–84, 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [2].Wässle H, Peichl L, and Boycott Brian Blundell. Morphology and topography of on-and off-alpha cells in the cat retina. Proceedings of the Royal Society of London. Series B. Biological Sciences, 212(1187):157–175, 1981. [DOI] [PubMed] [Google Scholar]
- [3].Devries Steven H and Baylor Denis A. Mosaic arrangement of ganglion cell receptive fields in rabbit retina. Journal of neurophysiology, 78(4):2048–2060, 1997. [DOI] [PubMed] [Google Scholar]
- [4].Field Greg D, Chichilnisky EJ, et al. Information processing in the primate retina: circuitry and coding. Annual review of neuroscience, 30(1):1–30, 2007. [DOI] [PubMed] [Google Scholar]
- [5].Sanes Joshua R and Masland Richard H. The types of retinal ganglion cells: current status and implications for neuronal classification. Annual review of neuroscience, 38:221–246, 2015. [DOI] [PubMed] [Google Scholar]
- [6].Attneave Fred. Some informational aspects of visual perception. Psychological review, 61(3):183, 1954. [DOI] [PubMed] [Google Scholar]
- [7].Barlow Horace B. Possible principles underlying the transformation of sensory messages. Sensory communication, 1:217–234, 1961. [Google Scholar]
- [8].Atick Joseph J and Redlich A Norman. Towards a theory of early visual processing. Neural computation, 2(3):308–320, 1990. [Google Scholar]
- [9].Atick Joseph J and Redlich A Norman. What does the retina know about natural scenes? Neural computation, 4(2):196–210, 1992. [Google Scholar]
- [10].Karklin Yan and Simoncelli Eero P. Efficient coding of natural images with a population of noisy linear-nonlinear neurons. In Advances in neural information processing systems, pages 999–1007, 2011. [PMC free article] [PubMed] [Google Scholar]
- [11].Doi Eizaburo, Gauthier Jeffrey L, Field Greg D, Shlens Jonathon, Sher Alexander, Greschner Martin, Machado Timothy A, Jepson Lauren H, Mathieson Keith, Gunning Deborah E, et al. Efficient coding of spatial information in the primate retina. Journal of Neuroscience, 32(46):16256–16264, 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [12].Pitkow Xaq and Meister Markus. Decorrelation and efficient coding by retinal ganglion cells. Nature neuroscience, 15(4):628–635, 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [13].Ocko Samuel, Lindsey Jack, Ganguli Surya, and Deny Stephane. The emergence of multiple retinal cell types through efficient coding of natural movies. In Advances in Neural Information Processing Systems, pages 9389–9400, 2018. [Google Scholar]
- [14].Jun Na Young, Field Greg D, and Pearson John. Scene statistics and noise determine the relative arrangement of receptive field mosaics. Proceedings of the National Academy of Sciences, 118(39), 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [15].Roy Suva, Jun Na Young, Davis Emily L, Pearson John, and Field Greg D. Inter-mosaic coordination of retinal receptive fields. Nature, 592(7854):409–413, 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [16].Sederberg Audrey J, MacLean Jason N, and Palmer Stephanie E. Learning to make external sensory stimulus predictions using internal correlations in populations of neurons. Proceedings of the National Academy of Sciences, 115(5):1105–1110, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [17].Chichilnisky EJ and Kalmar Rachel S. Functional asymmetries in on and off ganglion cells of primate retina. Journal of Neuroscience, 22(7):2737–2747, 2002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [18].Baden Tom, Berens Philipp, Franke Katrin, Rosón Miroslav Román, Bethge Matthias, and Euler Thomas. The functional diversity of retinal ganglion cells in the mouse. Nature, 529(7586):345–350, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [19].Ravi Sneha, Ahn Daniel, Greschner Martin, Chichilnisky EJ, and Field Greg D. Pathway-specific asymmetries between on and off visual signals. Journal of Neuroscience, 38(45):9728–9740, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [20].Bialek W and Owen WG. Temporal filtering in retinal bipolar cells. elements of an optimal computation? Biophysical Journal, 58(5):1227–1233, 1990. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [21].Dong Dawei W and Atick Joseph J. Statistics of natural time-varying images. Network: Computation in Neural Systems, 6(3):345, 1995. [Google Scholar]
- [22].Salisbury Jared M. and Palmer Stephanie E.. Optimal prediction in the retina and natural motion statistics. Journal of Statistical Physics, 162(5):1309–1323, January 2016. [Google Scholar]
- [23].Kingma Diederik P and Ba Jimmy. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014. [Google Scholar]
- [24].Nocedal Jorge and Wright Stephen. Numerical optimization. Springer Science, 35(67–68):7, 1999. [Google Scholar]
- [25].Palmer Stephanie E, Marre Olivier, Berry Michael J, and Bialek William. Predictive information in a sensory population. Proceedings of the National Academy of Sciences, 112(22):6908–6913, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [26].Oppenheim Alan V, Schafer Ronald W, Yoder Mark A, and Padgett Wayne T. Discrete-time signal processing. Pearson, Upper Saddle River, NJ, 3 edition, August 2009. [Google Scholar]
- [27].Lewicki Michael S. Efficient coding of natural sounds. Nature neuroscience, 5(4):356–363, 2002. [DOI] [PubMed] [Google Scholar]
- [28].Kuffler Stephen W. Discharge patterns and functional organization of mammalian retina. Journal of neurophysiology, 16(1):37–68, 1953. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.