
Figure 1:
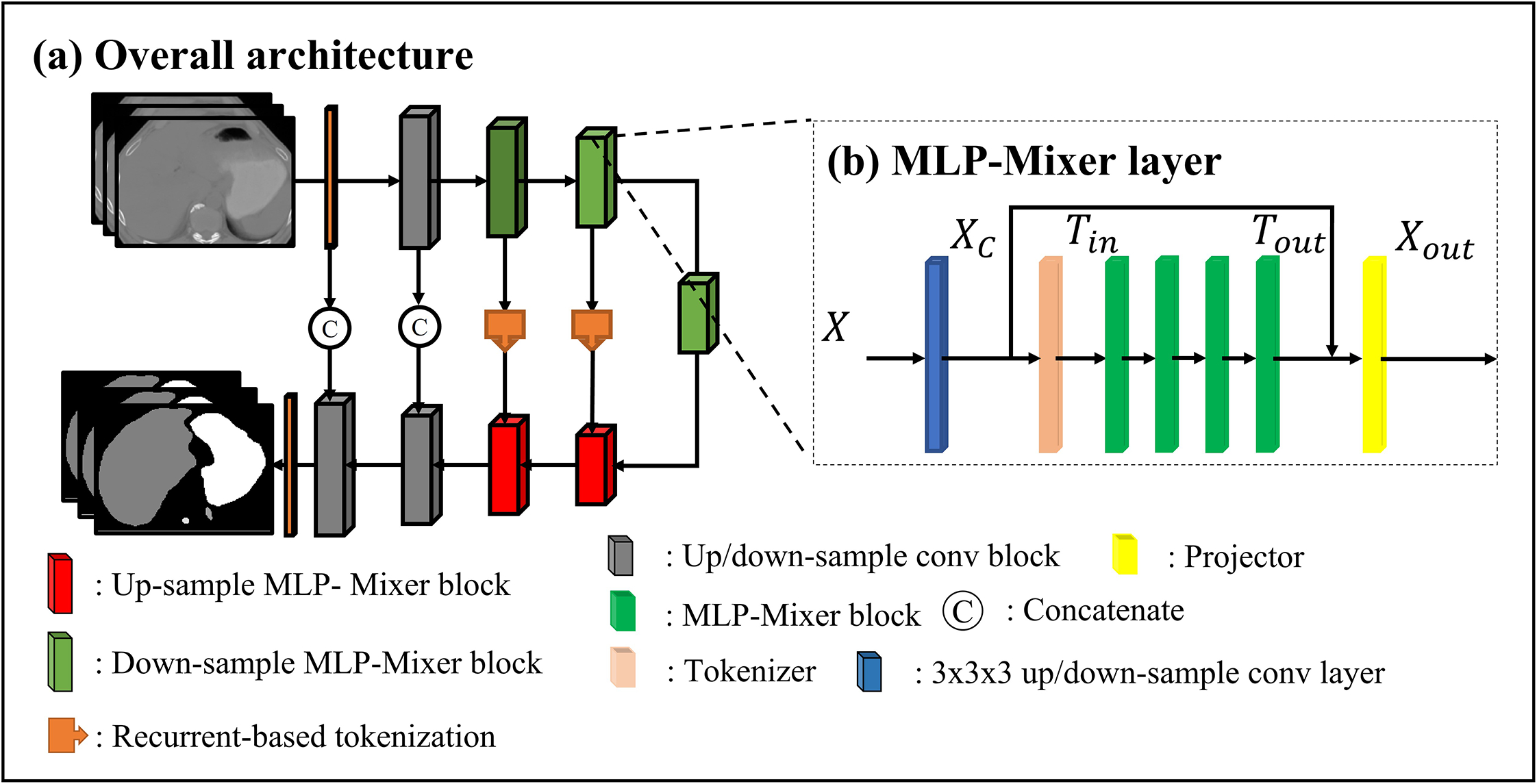
Network structure: A input scan is fed into an encoder (the first to the fifth layers) to learn features, then the features are forwarded to the decoder (the sixth to the tenth layers). (b)MLP-Mixer layers: each layer consists of a convolutional layer, a tokenizer, four MLP-Mixer layers, and a projector. The details of the residual convolutional layer, tokenizer, MLP-Mixer, and the projector refer to Fig. S-A1 in Appendix. A.