
Figure 16.
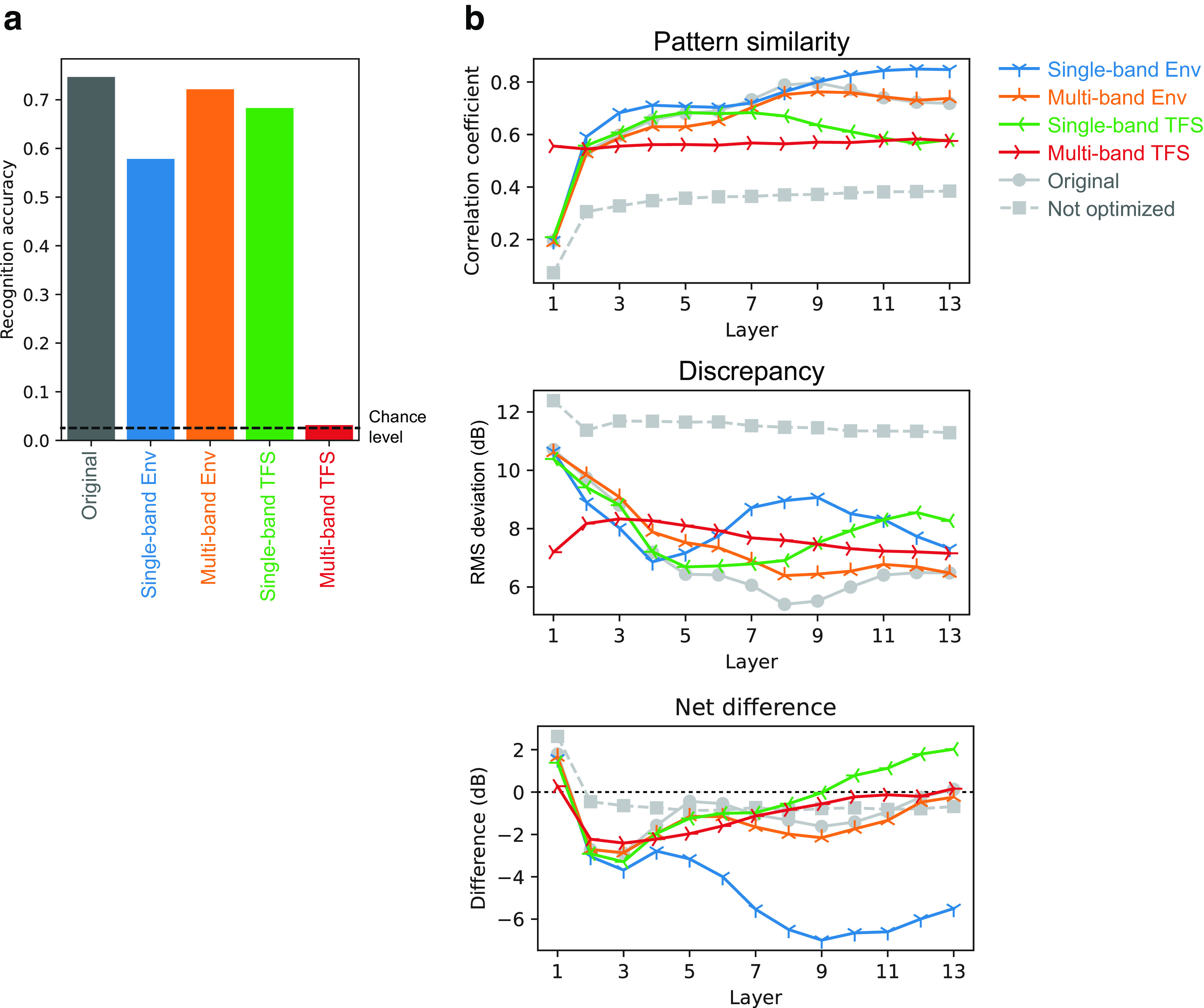
a, Recognition accuracy of the models optimized to degraded speech sounds. Left, The result for the model optimized to original speech sounds is also shown. Recognition accuracy dropped when the models were optimized to degraded sounds, but the drop was not catastrophic except in the multiband TFS model. b, Pattern similarity indices (top), discrepancy indices (middle), and net difference (bottom) between model TMTFs and human TMTFs. The results are consistent with those of the models optimized to everyday sounds.