

Abstract
Self-training is an important class of unsupervised domain adaptation (UDA) approaches that are used to mitigate the problem of domain shift, when applying knowledge learned from a labeled source domain to unlabeled and heterogeneous target domains. While self-training-based UDA has shown considerable promise on discriminative tasks, including classification and segmentation, through reliable pseudo-label filtering based on the maximum softmax probability, there is a paucity of prior work on self-training-based UDA for generative tasks, including image modality translation. To fill this gap, in this work, we seek to develop a generative self-training (GST) framework for domain adaptive image translation with continuous value prediction and regression objectives. Specifically, we quantify both aleatoric and epistemic uncertainties within our GST using variational Bayes learning to measure the reliability of synthesized data. We also introduce a self-attention scheme that de-emphasizes the background region to prevent it from dominating the training process. The adaptation is then carried out by an alternating optimization scheme with target domain supervision that focuses attention on the regions with reliable pseudo-labels. We evaluated our framework on two cross-scanner/center, inter-subject translation tasks, including tagged-to-cine magnetic resonance (MR) image translation and T1-weighted MR-to-fractional anisotropy translation. Extensive validations with unpaired target domain data showed that our GST yielded superior synthesis performance in comparison to adversarial training UDA methods.
Keywords: Unsupervised Domain Adaptation, Deep Self-Training, Self-Attention, Uncertainty Measurement, Cross-modality Translation, Medical Image Synthesis
1. Introduction
Image modality translation (also known as image synthesis) has been an active area of research in medical image analysis (Kaji and Kida, 2019). It has been shown to be of great benefit in downstream image analysis tasks, by creating images that either were not acquired due to imaging costs or limitations in study plans or are corrupted by artifacts (Xie et al., 2022a). Although synthesis performance has improved with advances in deep generative networks (Xie et al., 2022a), the performance of deep learning models can be degraded if the samples from training and testing datasets are following different distributions (Goodfellow et al., 2016). However, the problem of distribution or domain shift (Wang and Deng, 2018; Xu et al., 2021) is ubiquitous in medical imaging, since, in many cases, training and testing datasets are acquired using different acquisition protocols or are acquired from different parameters, dose, scanners, or centers. In addition, acquiring sufficient paired data in the new target domain can be expensive and even infeasible (He et al., 2021).
Therefore, unsupervised domain adaptation (UDA) can be highly desired, which seeks to transfer knowledge from a labeled source domain to an unlabeled target domain that is different but related (Wang and Deng, 2018). There is rich literature on UDA across a range of methods and applications (Liu et al., 2022b). Though UDA has shown great success in discriminative tasks, e.g., classification and segmentation (Liu et al., 2022b), the UDA in image modality translation has not been extensively investigated. The recent work (He et al., 2021) proposes to fine-tune a source-domain trained model to an unseen target subject, while the source domain data are not utilized at the UDA stage. To our knowledge, our prior conference version (Liu et al., 2021d) is the first attempt to achieve UDA in medical image modality translation, by jointly optimizing with both paired source and unpaired target domain data. A block diagram of a generative UDA task using cross-scanner tagged-to-cine tongue magnetic resonance (MR) image translation is shown in Fig. 1.
Fig. 1.
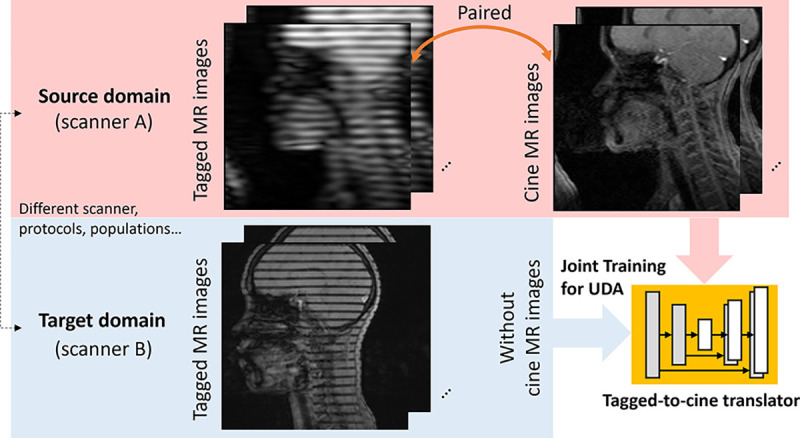
Illustration of a generative UDA task, specifically the cross-scanner tagged-to-cine translation of tongue MR images. The tagged-to-cine image translator is trained jointly with paired source domain and unpaired target domain data to achieve accurate inference in the target domain.
In recent years, self-training has been shown to be a powerful tool for UDA (Zou et al., 2019); in fact, it has outperformed adversarial UDA methods on several discriminative UDA benchmarks, including classification and segmentation as demonstrated in Wei et al. (2021); Mei et al. (2020); Shin et al. (2020); Liu et al. (2020). Deep discriminative self-training UDA works by first creating a set of one-hot (or smoothed) pseudo-labels in the target domain in an iterative manner. The network is then retrained using these pseudo-labeled target domain samples, as described in (Zou et al., 2019). Self-training UDA for generative tasks, however, has not been extensively studied, and adapting a discriminative self-training UDA model for generative tasks is not a straightforward process. Due to the noisy nature of the outputs of previous iterations in self-training, it is critical to only select the high confidence predictions as reliable pseudo-labels (Zou et al., 2019). However, calibrating the uncertainty of generative self-training UDA tasks remains an important yet challenging problem. Defining confidence as the maximum softmax probability is a natural choice in the case of discriminative self-training with a softmax output unit and a cross-entropy loss (Zou et al., 2019). However, the continuous prediction in regression does not inherently possess confidence or reliability confidence or reliability. In addition, in self-training UDA, both epistemic and aleatoric uncertainties (Kendall and Gal, 2017) arise, due to an insufficient amount of data samples in the target domain and unreliable pseudo-labels.
To tackle the above issues, we introduce a generative self-training (GST) framework for UDA medical image synthesis that employs continuous value prediction and regression objectives. A practical variational Bayes learning scheme is proposed to gauge the epistemic and aleatoric uncertainties in self-training UDA in a unified manner. The supervision of pseudo-labels on target domain data is explicitly regularized by a reliability mask, which is a learnable variable and is determined by the quantified uncertainty. An optimization strategy is then used to alternate between pseudo-label refinement and reliability mask generation, while also retraining the reliability regularized translator network for adaptation. In our prior conference version (Liu et al., 2021d), we constructed a binary reliability mask, by thresholding the uncertainty map to filter out unreliable pseudo-labels. Although the binary uncertainty selection scheme has been widely used in discriminative self-training and can be adapted to GST (Liu et al., 2021d), it can lead to sub-optimal performance, due to the following two difficulties: 1) the relatively rough pseudo-label selection scheme does not fully utilize the well-quantified uncertainty; and 2) the background region in medical images (e.g., the black boundary in MR images) often has high confidence and dominates the training loss. Of note, the performance on the region of interest is particularly important for medical image synthesis tasks, compared with nature image synthesis tasks.
To address the aforementioned difficulties, in the present work, we build on our prior conference version (Liu et al., 2021d) in the following ways. First, we propose a proper mapping from uncertainty to continuous reliability measurement to achieve fine-grained pseudo-label control and make more efficient use of the well-quantified uncertainty. Second, we incorporate a self-attention scheme into our continuous reliability mask to de-emphasize the background region in our loss calculation. Third, we present an interpretation of our GST framework in the context of recent works (He et al., 2021; Zuo et al., 2021; Yarram et al., 2022). Finally, we extend our evaluation framework beyond the tagged-to-cine MR translation task to include a cross-scanner T1-weighted MRI-to-fractional anisotropy (FA) translation task. To validate and demonstrate the superiority of our proposed GST framework, we compared it with recent UDA methods across all tasks.
The main contributions are summarized as follows:
To our knowledge, this is the first attempt to jointly utilize both paired source domain data and unpaired target domain data for deep UDA in medical image modality translation scenarios (Liu et al., 2021d).
We propose a novel GST framework which extends the self-training to a generative UDA task, i.e., image modality translation. It is based on adaptive control of the reliability of pseudo-label with a practical Bayesian reliability mask. Furthermore, we systematically study both the aleatoric and epistemic uncertainties in GST UDA.
We introduce a self-attention continuous reliability mask that achieves fine-grained pseudo-label control with well-quantified uncertainty, guided by self-learned attention.
Our proposed GST framework is applied to cross-scanner/center and inter-subject tagged-to-cine tongue MR UDA translation, as well as T1-to-FA brain MR UDA translation tasks. These tasks have significant potential to reduce the acquisition time and costs of extra cine/diffusion MR scans.
Our framework is evaluated using both quantitative and qualitative measures, and the results demonstrate its validity and superiority over conventional adversarial UDA approaches.
2. Related Work
2.1. Medical Image Modality Translation/Synthesis
Image modality translation is a critical pre-processing step in medical image analysis for filling in incomplete modalities or reducing scanning costs (Kaji and Kida, 2019). For example, tagged-to-cine MR image translation has the potential to alleviate the extra cine MR image acquisition time and costs (Liu et al., 2021c). Tagged MR images with horizontal or vertical tag patterns are typically acquired, while the internal organ is in motion, but due to their lower spatial resolution, they may not effectively separate the organ of interest. Therefore, another set of paired cine MR images with higher resolution is usually required as a matching pair, which can double the scanning time and costs (Xing et al., 2016). Multi-modal neuroimaging is another area, where image modality translation is widely used to overcome the missing modality issue caused by motion during the acquisition process (Chartsias et al., 2017; Gu et al., 2019; Armanious et al., 2020; Zhou et al., 2020; Zhan et al., 2021). Despite the potential applications of medical image translation for UDA in a range of clinical settings, it has not been extensively studied.
2.2. Cross Domain Medical Image Translation
There are three main categories of related approaches that have been explored to address domain shift in medical image synthesis (Liu et al., 2022b). The first category involves using labels in both domains within a multi-task learning framework (Zuo et al., 2021). However, this approach requires the acquisition of sufficient paired data in each new domain, which can be costly. The second category proposes to adapt a pre-trained source model to the target data without access to source data at the adaptation stage (He et al., 2021). The performance of these approaches is generally worse than those with access to source data (Liu et al., 2022b). The third category is UDA, which jointly trains a model on paired source domain and unlabeled heterogeneous target domain data at the adaptation stage to achieve good testing performance in the target domain (Liu et al., 2021d). In contrast to the first category that relies on costly paired data acquisition in each new domain, and the second category that may have worse performance without source data at the adaptation stage, UDA fully utilizes both paired source domain and unpaired target domain data. In this work, we focus on UDA for medical image synthesis tasks.
2.3. Unsupervised Domain Adaptation
Early attempts at UDA focused on minimizing a prescribed discrepancy measurement—e.g., maximum mean discrepancy (MMD) (Long et al., 2015) or batch normalization statistics (Liu et al., 2021b)—between domains. More recent UDA approaches (Tzeng et al., 2017; Liu et al., 2021a) incorporated an adversarially learned domain discriminator as a discrepancy measurement. Both early and recent works have primarily focused on discriminative tasks such as classification and segmentation (Wilson and Cook, 2020; Liu et al., 2022b). In medical image segmentation, UDA has achieved a series of superior performances in various applications including vestibular schwannoma and cochlea (Dorent et al., 2023), cardiac structures (Li et al., 2020; Zhao et al., 2022), and abdominal organs (Zhao et al., 2022).
The recent work (He et al., 2021) has shown that the adversarial UDA methods can be adapted to generative tasks, by changing the source domain cross-entropy loss into a regression loss via mean square error (MSE). In addition, adversarial UDA has been used for super-resolution image reconstruction (Wang et al., 2021). While aligning latent feature representations can be applied to both discriminative and generative tasks, choosing or learning a proper divergence measure has remained a long-standing problem (Gulrajani et al., 2017; Wilson and Cook, 2020). In addition, adversarial methods tend to be difficult to train and have been shown to sometimes introduce “hallucination” content (Goodfellow et al., 2016), which is problematic in medical image synthesis applications, where precise and accurate results are crucial.
2.4. Self-training for UDA
Self-training was originally developed for semi-supervised learning (Zhu, 2007; Triguero et al., 2015) and has evolved to include deep embedding learning and classifier adaptation for UDA (Zou et al., 2018). In recent years, self-training-based UDA has emerged as a powerful method to address unknown labels in the target domain (Zou et al., 2019), outperforming adversarial learning-based methods in several discriminative UDA benchmarks (Wei et al., 2021; Mei et al., 2020; Shin et al., 2020). It does not rely on adversarial training, which is difficult to stabilize (Goodfellow et al., 2016). Additionally, while self-training UDA has proven effective for classification and segmentation tasks through the use of reliable pseudo-label selection based on the softmax discrete histogram (Xie et al., 2022b; Cheng et al., 2023; Kong et al., 2022), the application of the same approach to generative tasks such as image synthesis has not been extensively explored.
2.5. Uncertainty Estimation
Quantifying model uncertainty is crucial in medical image analysis (Begoli et al., 2019). There are two main categories of uncertainty in deep learning models (Kendall and Gal, 2017). First, aleatoric uncertainty accounts for label noise inherent in the dataset and can be modeled by introducing a prior distribution over the model weights to capture the degree of variability of these weights given some data. Second, epistemic uncertainty captures the freedom of the model parameters and can be minimized with sufficient data during training. Bayesian deep learning has advanced uncertainty estimation in recent years (Abdar et al., 2021), but a systematic analysis of aleatoric and epistemic uncertainties in self-training based UDA settings is lacking. Notably, the uncertainty of the previous round’s prediction plays a critical role in measuring the reliability of pseudo-labels in self-training.
3. Methodology
In a UDA image translation task, we are given a source domain and a heterogeneous target domain . From the source domain, we have the paired samples , where and , indexed by , are slices with paired/aligned input and output modalities. and are the height and width of a slice. For example, in the tagged-to-cine MR translation task, is a tagged MR slice and is the corresponding cine MR slice. In addition, are unpaired target domain samples indexed by . The corresponding target domain labels are not accessible for training in our UDA task. We aim to learn a translator , parameterized by , for synthesizing an output modality image that can be generalized well in the target domain. UDA methods are expected to gradually update for target domain image translation, by utilizing both and .
3.1. Generative Self-training UDA
To fill in the missing target domain label , self-training UDA approaches first generate the pseudo-label of in an iterative manner. Then, reliable pseudo-labels are selected as the “ground-truth” labels for target domain samples, following supervised training protocols. Specifically, traditional self-training approaches typically treat the pseudo-label as a learnable latent variable represented by a categorical histogram. This histogram can be either a one-hot distribution (Zou et al., 2018) or a smoothed histogram distribution (Zou et al., 2019; Liu et al., 2020). The pseudo-label is typically derived from the predictions in previous iterations, by selecting the maximum probability category to construct the one-hot label. However, the previous predictions are inherently noisy, which poses a significant challenge for self-training UDA.
The de-facto solution to discriminative self-training is to define a binary selection threshold to progressively select confident pseudo-labels (Zhu, 2007; Zou et al., 2018, 2019). For classification or segmentation models with categorical softmax output units for an image or pixel, the maximum value of the softmax distribution is commonly used to approximate the confidence of the model’s prediction (Zou et al., 2019). The prediction with a maximum softmax output histogram probability higher than a threshold is considered a confident prediction and is used as a pseudo-label for supervised training. On the other hand, if the maximum softmax output histogram probability of a prediction is lower than a threshold, it is considered an uncertain prediction and is set to the all-zero vector 0. Therefore, only the selected confident pseudo-label will contribute to the model update. In the case of continuous output values from a translation model, setting unreliable pseudo-labels to zeros does not remove them from evaluation or prevent their use in the regression loss. This can lead to poor model performance and unreliable synthesis results.
Inspired by discriminative self-training methods (Zou et al., 2019; Wei et al., 2021; Liu et al., 2020), we propose a novel GST framework, where the predictions are pixel-wise continuous values and the contributions of pseudo-labels are controlled with a learnable reliability mask , where indexes the pixel in the images. To train this model, the sum of two loss functions is minimized as
| (1) |
where in our implementations. Here, represents the n-th pixel of the t-th target domain input image , and and denote the predicted source and target images, respectively. Notably, we have a ground truth label of source domain data in the UDA setting, which has a constant reliability of 1. We indicate the regression losses (in the empirical form of MSE) of the source and target domain data as and , respectively. Of note, there is only one translator , parameterized by , which is updated with both and .
Instead of setting the uncertain pseudo-labels to zero as in , we use the reliability mask as a learnable variable with respect to uncertainty to control the contribution of pseudo-labels in model training. The pseudo-labels are simply the previous continuous predictions without post-processing. The core issue in our generative self-training method is to properly associate the continuous prediction uncertainty with to ensure reliable pseudo-label selection.
3.2. Bayesian Uncertainty in Self-training UDA
After obtaining the learnable reliability mask , the next step is to determine the value of the mask for unpaired target sample pixels to reflect the uncertainty of the pseudo-label. While uncertainty estimation has been extensively explored in computer vision and machine learning (Kendall and Gal, 2017; Carvalho et al., 2020; Shen et al., 2021), its application to generative UDA in medical image analysis remains largely unexplored.
In learning-based tasks, two types of uncertainty are commonly considered: aleatoric uncertainty and epistemic uncertainty (Der Kiureghian and Ditlevsen, 2009; Kendall and Gal, 2017; Hu et al., 2019). Aleatoric uncertainty captures the inherent randomness and variability in the observations, while epistemic uncertainty arises from the lack of information or knowledge about the model parameters. In the case of self-training, the generated pseudo-labels are inherently noisy, and therefore characterized by aleatoric uncertainty. Moreover, limited iterations of model training and insufficient training samples can lead to epistemic uncertainty with respect to the model parameters.
In what follows, we take both uncertainties into consideration to provide a holistic uncertainty calibration. Specifically, epistemic uncertainty is measured via Monte Carlo dropout, and aleatoric uncertainty is included in the network output.
We can model the epistemic uncertainty via Bayesian network learning, which hinges on learning a posterior distribution over probabilistic network parameters in place of deterministic network parameters (Rasmussen, 2003). However, we cannot evaluate analytically, since the integration in the normalizing distribution is intractable. One common approach to address this issue is to use a variational approximation to substitute the underlying posterior distribution. Given an approximate distribution over the parameters of the network, the minimization of the Kullback-Leibler (KL) divergence between and , i.e., , can be enforced to learn the approximation. In practice, to approximate , dropout variational inference can be applied, by adopting a Bernoulli distribution (Gal and Ghahramani, 2015); for example, Monte Carlo (MC) dropout can be used by times predictions with independent dropout sampling. In this work, we use the MSE to measure the epistemic uncertainty as in (Rasmussen, 2003), which assesses a one-dimensional regression model similar to Fruehwirt et al. (2018). Then, times MC dropout predictions are used to estimate the epistemic uncertainty as
| (2) |
where indexes the MC dropouts, and is the predictive mean of all MC dropout predictions .
In addition, it is necessary to model the heteroscedastic aleatoric uncertainty for each sample (Nix and Weigend, 1994; Le et al., 2005). To this end, we split the decoder part of to predict both and a variance map which has element as the predicted variance of the n-th pixel (Le et al., 2005; Kendall and Gal, 2017). Notably, the “aleatoric uncertainty labels” are not available for supervised training. Instead, we are able to learn the variance map implicitly from a regularized regression loss function (Le et al., 2005; Kendall and Gal, 2017). Specifically, the target domain loss can be formulated as
| (3) |
where the first term is the variance normalized MSE loss with reliability mask control, and the second term is an uncertainty regularization term, , which prevents the network from predicting infinite uncertainty for any given sample. Following Le et al. (2005); Kendall and Gal (2017), the averaged aleatoric uncertainty of MC dropout predictions is quantified as
| (4) |
Since the loss in Eq. (3) is to be minimized, it can be interpreted as the Lagrangian (where is a Lagrange multiplier) of the following constrained minimization problem:
| (5) |
| (6) |
where indicates the strength of the applied constraint1. Then, the term can be interpreted as the measurement of image-level aleatoric uncertainty. As such, the constraint term in Eq. (6) can effectively constrain the target domain’s predictive aleatoric uncertainty, which is particularly useful for adaptation training (Han et al., 2019). Taken together, the pixel-wise uncertainty estimated in our GST UDA can be formulated as a combination of the two uncertainties (Kendall and Gal, 2017):
| (7) |
3.3. Binary Reliability Mask for GST
It is possible to use uncertainty measurements in discriminative self-training methods, by either keeping or filtering out the confident or uncertain pseudo-labels, respectively (Triguero et al., 2015; Zou et al., 2019). Specifically, these methods propose to construct a binary reliability mask as shown in Eq. (1) by:
| (8) |
where the value of the reliability mask is selected by the measured uncertainty with a critical threshold . Since the pseudo-labels are gradually refined along with the adaptation training, ideally should be adaptively updated to control pseudo-label learning and selection. Therefore, is typically defined by a meta portion parameter , indicating the portion of reliable pseudo-labels. Then, in each iteration, we determine by sorting in increasing order so that is the minimum of the top percentile rank (Zou et al., 2019; Liu et al., 2020). This is akin to self-paced learning (Kumar et al., 2010; Tang et al., 2012; Zou et al., 2019), where weights are learned following an easy-to-hard strategy.
With the binary reliability mask definition above, we can now turn to the task of optimizing our self-training objective in Eq. (1). Since direct optimization of the self-training objective in Eq.(1) is difficult, we leverage the deterministic annealing expectation maximization (EM) algorithm defined in Grandvalet and Bengio (2006) instead. Specifically, we can solve our GST UDA framework using an alternating optimization scheme consisting of the following two steps:
Pseudo-label and reliability mask generation. With the current , apply MC dropout times for each and measure . Then, calculate the binary reliability mask , given the current threshold . The pseudo-label of the selected pixel in this round is set as , which is the average value of MC dropout predictions.
Translator retraining. Fix and update by solving:
| (9) |

We define a round of self-training as the sequential execution of steps 1) and 2). Intuitively, step 1) is equivalent to performing simultaneous pseudo-label generation and reliability-based selection. To solve step 2), we use a conventional gradient descent algorithm. Additionally, we linearly increase the meta portion parameter from to 80% during training to gradually select more pseudo-labels, following the approach proposed in Zou et al. (2019); Liu et al. (2020).
3.4. Continuous Reliability Mask
In the previous section, we described the binary uncertainty selection scheme, which is widely used in discriminative self-training (Zou et al., 2019; Wei et al., 2021; Liu et al., 2020). The primary reason for choosing a binary pseudo-label in discriminative self-training is that the softmax prediction itself is not a good measure of uncertainty or confidence (Goodfellow et al., 2016), which makes it unreliable to use for controlling uncertainty (Zou et al., 2019; Liu et al., 2020). However, when a well-quantified uncertainty measure, such as our , is available, we should not have to binarize it for use in the framework described above. The challenge, however, is how to use it in a continuous manner.
We propose constructing a continuous reliability mask for the pseudo label , by appropriately mapping the value of . Although the reciprocal term is a possible candidate for mapping to , it can be numerically unstable for . Moreover, the background region in many medical images often contains numerous pixels with zero , making this approach unsuitable. We note that translation of the background region is straightforward via an identical mapping, and the network is always highly confident about its prediction in this region. Based on the observations above, we propose a practical solution with a self-attention guided continuous reliability mask. In particular, we propose to add a heuristic non-linear normalization unit to the calculated element in the uncertainty map to generate the element of the reliability mask:
| (10) |
With the continuous reliability mask, we are able to achieve fine-grained control over the binary setting to efficiently utilize the well-quantified uncertainty. Specifically, we can view the binary mask as a simplified special case of the continuous mask obtained by applying a threshold.
3.5. Self-attentive Continuous GST
In addition to our use of a continuous mask, we propose to emphasize anatomical structures rather than the background region in MR data. Notably, the zero or small values in the background region correspond to the high reliability weights, and are therefore likely to dominate the training loss . In practice, the confidence of pixels in the background region is usually top-ranked to have , when using either binary reliability mask in Eq. (8) or continuous reliability mask . These easy samples may dominate the training of the deep network. Therefore, we introduce a self-trained attention network such that each slice is processed with to yield the refined corresponding attention map , where . The attention map is then multiplied by the generated reliability mask to obtain the attention reliability mask
| (11) |
In this way, the background region is not emphasized during training. We adopt a conventional 2D encoder-decoder structure for , and it is jointly optimized with in a collaborative manner, by minimizing the same loss. As a result, our proposed method encourages to adaptively learn and retain the essential information required for optimal translation performance in a self-training manner. Importantly, our approach does not require an additional attention label for training . The two-step optimization of a continuous reliability mask with an adaptively learned attention module can be formulated as follows:
Pseudo-label and attentive reliability mask generation. With the current , we apply MC dropout times for each to measure . We then use to generate the attention map , and use a heuristically non-linear normalization unit to calculate the continuous reliability mask . We do not need to set a threshold or a proportion parameter for pseudo-label selection. The pseudo-label of the selected pixel in this round is set to , which is the average value of MC dropout predictions.
Translator and attention module retraining. Fix , and update , by solving:
| (12) |
The overall training protocol is outlined in Algorithm 1. During testing, only the trained translator is used for inference. The continuous reliability measurement not only provides fine-grained control, but also allows us to integrate the attention module to de-emphasize the background regions.
4. Experiments and Results
To demonstrate the effectiveness of our framework, we evaluated it on two translation tasks, including cross-scanner/center tagged-to-cine tongue MR image UDA translation and T1-to-FA brain MR image UDA translation. We followed the test time UDA setting as in Karani et al. (2021); He et al. (2021); Liu et al. (2021d), which only uses one unpaired target subject in UDA training and testing. Our framework was implemented on an NVIDIA V100 GPU using the PyTorch deep learning toolbox. For GST training, we used the Adam optimizer with a momentum of 0.5 and a fixed learning rate of 1 × 10−3 throughout all experiments. In each iteration, the batch size was set to 16 slices in both the source and target domains.
We denote our proposed framework as AC:GST, which uses the self-attention continuous reliability mask, and BM:GST, which uses the binary reliability mask as in (Liu et al., 2021d). For our ablation studies, we evaluated AC:GST without the attention scheme (denoted as AC:GST-) and without the continuous reliability mask (denoted as AC:GST-C). Additionally, we carried out experiments, where the epistemic or aleatoric uncertainty is ignored in our uncertainty quantification, which are denoted as -E or -A, respectively. We report the results as mean±SD over three evaluations.
Similar to He et al. (2021); Liu et al. (2021d), we compared our framework with several widely used discriminative adversarial UDA methods, including ADDA (Tzeng et al., 2017), GAUDA (Cui et al., 2020), and JGLA (Yarram et al., 2022). To adapt these methods to our task, we replaced their output unit and used the MSE loss. Additionally, we evaluated our framework against ASS (He et al., 2021), which fine-tunes a source-domain trained model to an unseen target subject without utilizing the source domain data during the adaptation stage.
For a fair comparison, we used the UNet-based translator in Pix2Pix (Isola et al., 2017) as the backbone of our GST and the compared methods. We initialized with pre-training in the source domain (Liu et al., 2021c). Note that the last three layers in the decoder were duplicated for variance prediction. We trained from scratch with random initialization, using the same backbone as .
4.1. UMB cross-scanner tagged-to-cine MR translation
Tagged MR images have been widely used to quantify tissue deformation in moving organs, including the heart (Osman et al., 2000) and the tongue (Xing et al., 2013; Parthasarathy et al., 2007). In this work, we applied our framework to tongue motion data acquired during speech. While internal motion of the tongue can be reconstructed from these tagged images, it is difficult to reconstruct the tongue surface due to the relatively low resolution of the images. Therefore, a set of cine MR images is typically acquired in the same scanning session to provide higher resolution images of the tongue surface during the same speech phrases. If tagged-to-cine MR translation could be performed, then it would not be necessary to acquire the cine MR images, reducing extra acquisition time and ensuring accurate registration between the two sets of image sequences (Liu et al., 2021c). Fig. 3 shows a visual illustration of the appearance difference. The target domain 1 refers to tagged MR images collected from the University of Maryland, Baltimore (UMB) with a different scanner, while the target domain 2 refers to tagged MR images collected from MGH with a different scanner. We used tagged MR images with horizontal tag patterns for our evaluation.
Fig. 3.

Comparison of the collected tagged MR images in different domains.
As the source domain, we acquired a total of 1,768 paired tagged and cine tongue MR slices from a cohort of 10 healthy subjects at UMB. The data was acquired using a segmented gradient-echo sequence on a Siemens 3.0T TIM Trio system with a 12-channel head coil and a 4-channel neck coil (Xing et al., 2016). The imaging parameters were as follows: a field of view of 240×240 mm, an in-plane resolution of 1.88×1.88 mm, and a slice thickness of 6 mm. The image sequence was obtained at a rate of 26 fps, synchronized to the subject’s verbal response. Both cine and tagged MR images were acquired in the same spatiotemporal coordinate space.
For the target domain, i.e., cross-scanner target domain 1, we collected a total of 1,014 paired tagged and cine tongue MR slices from a cohort of 5 different healthy subjects at UMB. We used a Siemens 3.0T Prisma scanner with a 64-channel head and neck coil, and acquired the images using the same sequence as in the source domain (Xing et al., 2016). Due to the use of different scanners, there were appearance discrepancies between the datasets acquired from the two scanners. The imaging parameters were as follows: a field of view of 240×240 mm, an in-plane resolution of 1.88×1.88 mm, and a slice thickness of 6 mm. The image sequence was obtained at the rate of 26 fps, synchronized with the subject’s verbal response. Both cine and tagged MR images were in the same spatiotemporal coordinate space. We performed five-fold cross-validation on the 5 subjects in the target domain. In each round, we used one subject for testing, while the other four were used for training and validation. Notably, we followed the test-time adaptation protocol, where the source domain could be considered as an auxiliary set with independent subjects for target training/validation/testing.
In Fig. 4, we show a qualitative comparison of the synthesis results using the proposed AC:GST and the other comparison methods, including source domain Pix2Pix (Isola et al., 2017) without UDA training, vanilla adversarial UDA (ADDA) (Tzeng et al., 2017), and gradually adversarial UDA (GAUDA) (Cui et al., 2020). It is worth noting that the domain-wise distribution alignment loss in adversarial UDA methods often leads to the presence of hallucinated content, resulting in significant differences in the shape and texture of the tongue between the real cine MR images. In contrast, the proposed GST UDA does not rely on adversarial training, leading to the synthesis of visually pleasing slices with more consistent anatomical structure, as demonstrated in Fig. 4. Such consistent anatomical structure is essential for subsequent analyses (Xing et al., 2016).
Fig. 4.

Comparisons with the adversarial UDA (Cui et al., 2020; Yarram et al., 2022) and Pix2Pix (Isola et al., 2017) w/o adaptation for the within UMB cross-scanner tongue tagged-to-cine MR image translation. The red rectangle indicates the tongue region used for tongue motion analysis.
In the ablation study, the results in Fig. 5 demonstrate that AC:GST with the self-attention continuous reliability mask outperforms AC:GST-, AC:GST-C, and BM:GST. Additionally, the comparison between BM:GST-E, BM:GST-A, and BM:GST demonstrates the advantage of considering both aleatoric and epistemic uncertainties for the mask.
Fig. 5.

Ablation studies of our proposed AC:GST, BM:GST, BM:GST-A, and BM:GST-E for within UMB cross-scanner tagged-to-cine tongue MR image translation. The red rectangle indicates the tongue region used for tongue motion analysis.
We expect that the synthesized images would have realistic and structurally consistent textures as compared with their corresponding ground truth images. To quantitatively assess our framework, we adopted well-known evaluation metrics including structural similarity index measure (SSIM), peak signal-to-noise ratio (PSNR), mean L1 error, and inception score (IS) (Liu et al., 2021c). Table 1 lists numerical comparisons using a total of five testing subjects in the target domain. When compared with He et al. (2021), UDA methods that leveraged source domain data during the adaptation stage (Tzeng et al., 2017; Cui et al., 2020; Yarram et al., 2022) achieved marked improvements in the measures listed above. Our GST surpassed GAUDA (Cui et al., 2020), and ADDA (Tzeng et al., 2017) in terms of SSIM, PSNR, L1 error, and IS by a large margin. The averaged results of the target domain supervised model are also provided, which can be regarded as an “upper-bound”. To show statistical significance, we performed a one-tailed paired t-test for each of the L1, SSIM, PSNR, and IS metrics, comparing improvements over BM:GST with AC:GST, yielding p-values of 0.026, 0.0085, 0.0042, and 0.0014, respectively. When comparing AC:GST with JGLA, we obtained p-values of L1, SSIM, PSNR, and IS metrics of 0.013, 0.0037, 2.63 × 10−4, and 4.70 × 10−6, respectively.
Table 1.
Numerical comparisons and ablation studies of the UMB cross-scanner tongue tagged-to-cine MR translation task.
| Methods | L1 ↓ | SSIM ↑ | PSNR ↑ | IS ↑ |
|---|---|---|---|---|
|
| ||||
| w/o UDA (Isola et al., 2017) | 176.4±0.1 | 0.8325±0.0012 | 26.31±0.05 | 8.73±0.12 |
|
| ||||
| ASS (He et al., 2021) | 170.5±0.3 | 0.8525±0.0011 | 30.12±0.06 | 9.95±0.13 |
|
| ||||
| ADDA (Tzeng et al., 2017) | 168.2±0.2 | 0.8784±0.0013 | 33.15±0.04 | 10.38±0.11 |
| GAUDA (Cui et al., 2020) | 161.7±0.1 | 0.8813±0.0012 | 33.27±0.06 | 10.62±0.13 |
| JGLA (Yarram et al., 2022) | 160.4±0.4 | 0.8815±0.0012 | 33.24±0.05 | 10.67±0.10 |
|
| ||||
| AC:GST | 157.1±0.3 | 0.9217±0.0012 | 35.92±0.05 | 13.70±0.12 |
| AC:GST- | 157.8±0.2 | 0.9151±0.0015 | 35.40±0.07 | 13.19±0.13 |
| AC:GST-C | 158.0±0.2 | 0.9183±0.0010 | 35.65±0.03 | 13.28±0.11 |
| BM:GST (Liu et al., 2021d) | 158.6±0.2 | 0.9078±0.0011 | 34.48±0.05 | 12.63±0.12 |
| BM:GST-A | 159.5±0.3 | 0.8997±0.0011 | 34.03±0.04 | 12.03±0.12 |
| BM:GST-E | 159.8±0.1 | 0.9026±0.0013 | 34.05±0.05 | 11.95±0.11 |
|
| ||||
| Target Supervised | 148.2±0.2 | 0.9516±0.0012 | 37.42±0.05 | 15.37±0.13 |
We empirically set weights and based on validation to balance the absolute value of each loss. While a larger can help approximate the true uncertainty better, the computing cost increases linearly with . Therefore, it is necessary to find a reasonable value of that balances between uncertainty estimation and computation efficiency.
The multiplier was used to balance between and . Typically, networks are not sensitive to the Lagrangian multiplier within a large range. To investigate the effect of on the performance of AC:GST in the cross-scanner tagged-to-cine UDA task, we carried out a sensitivity analysis, as shown in Fig. 6. The results demonstrate that the performance of AC:GST is stable for . The number of MC dropouts can affect the epistemic uncertainty estimation. Larger values of can help in approximating the true uncertainty, but it will lead to an increase in computation cost linearly. Therefore, it is necessary to find a suitable value for to balance uncertainty estimation and computation efficiency. In Table 6, we provide a detailed sensitivity analysis of for AC:GST in the cross-scanner tagged-to-cine UDA task. It can be observed that the performance is relatively stable for . In BM:GST, the meta portion parameter is gradually increased from 30% to 80% over the training to select more pseudo-labels, as in (Zou et al., 2019; Liu et al., 2020). However, in AC:GST, we do not rely on for binary selection.
Fig. 6.

Sensitivity analysis of in AC:GST with respect to L1 error for UMB cross-scanner tagged-to-cine MR translation.
As shown in Fig. 7, the uncertainty gradually decreases as the training progresses. In the early stages, e.g., the 5th epoch, our uncertainty map focuses on the ROI, after which it concentrates on refining the shape boundary. Of note, the model is also constrained by attention maps. In our tongue and brain MR image translation tasks, the ROI is the anatomical part, while the remaining blank region should follow an easy identical mapping. Therefore, even in the initial epochs, the uncertainty will focus on the ROI region and will not be high in everywhere. For the more fine-grained uncertainty control, our method can also avoid the impact of large uncertainty in a wide region. Specifically, the binary mask uses to select the top-ranked confident pixel. Therefore, our mask is only related to the relative uncertainty with the ranking protocol, not the absolute uncertainty value. For the attentive continuous mask, we have another attention module to constrain the model to focus on ROI, and the e-index function in Eq. (10) can also eliminate small uncertainty values.
Fig. 7.

Qualitative example of uncertainty measurement during training epochs for the UMB cross-scanner tagged-to-cine MR translation task.
4.2. UMB-MGH tagged-to-cine MR translation
To further demonstrate the generality of our framework in handling larger domain gaps, we collected 120 tagged 2D MR slices from one subject at Massachusetts General Hospital (MGH) as the cross-center target domain. The MRI scanning was performed using a Siemens Skyra 3T scanner with a 64-channel head and neck coil, employing a gradient recalled echo sequence. The MRI acquisition parameters included a 128×128 field of view, 12 slices of 6 mm thickness acquired at 10 equally spaced time points, 86 ms apart, synchronized to the subject’s verbal response. The in-plane resolution was 2 mm×2 mm, and the tag spacing was 12 mm. Due to differences in soft tissue contrast, as well as imaging parameters such as tag spacing and field of view, there were notable discrepancies between the data collected at MGH and UMB. As there were no paired cine MR images available as ground truth in the target domain, we set and , following the settings used for the cross-scanner translation task.
In Fig. 8, we provide quantification results of aleatoric and epistemic uncertainties alongside qualitative comparisons between GAUDA and the ablation study of the self-attention continuous reliability mask. We show that the anatomic structure of the tongue is better synthesized using the AC:GST framework, compared with the other comparison methods. Because of the large domain gaps in the datasets between the two sites, the image quality of the UMB-MGH cross-center translation setting was inferior to that of the within UMB cross-scanner translation setting, as visually assessed.
Fig. 8.

Comparison of various UDA methods on the UMB-MGH cross-center tagged-to-cine MR image translation task, including our proposed AC:GST, BM:GST, BM:GST-A, and BM:GST-E, as well as adversarial UDA (Cui et al., 2020) and Pix2Pix (Isola et al., 2017) without adaptation. The red rectangle indicates the tongue region.
Of note, in the MGH dataset, we do not have paired ground truth data. Therefore, we provide quantitative comparisons using the inception score (IS), which does not require paired labels (Liu et al., 2021c). As shown in Table 2, our proposed GST outperforms the adversarial UDA approaches, i.e., GAUDA and ADDA (Cui et al., 2020; Tzeng et al., 2017), in a consistent manner, indicating the effectiveness of self-training for this generative image translation UDA task.
Table 2.
Numerical comparisons and ablation studies of the UMB-MGH cross-center tongue tagged-to-cine MR translation task
| Compared Methods | IS ↑ | Proposed Methods | IS ↑ |
|---|---|---|---|
|
| |||
| w/o UDA (Isola et al., 2017) | 5.32±0.11 | AC:GST | 9.86±0.13 |
|
|
|||
| ASS (He et al., 2021) | 6.94±0.12 | AC:GST- | 9.82±0.12 |
|
|
|||
| ADDA (Tzeng et al., 2017) | 8.69±0.10 | BM:GST (Liu et al., 2021d) | 9.76±0.11 |
| GAUDA (Cui et al., 2020) | 8.83±0.14 | BM:GST-E | 9.54±0.13 |
| JGLA (Yarram et al., 2022) | 8.75±0.12 | BM:GST-A | 9.58±0.12 |
4.3. WUMinn-MGH cross-center T1-to-FA MR translation
Diffusion MRI is a non-invasive imaging method that enables the measurement of water molecule diffusion in tissue, allowing for the quantification of microstructural tissue properties. Scalar measures of diffusion computed from diffusion MRI, such as fractional anisotropy (FA) and mean diffusivity, have become widely used. However, collecting high-quality diffusion MRI data can be challenging and time-consuming. Moreover, diffusion MRI can be affected by various artifacts, such as motion and susceptibility artifacts, which can hinder subsequent analyses (Gu et al., 2019). Therefore, synthesizing scalar diffusion quantities from structural MR scans, which are easier to acquire than diffusion MRI, would be useful (Gu et al., 2019).
As the source domain data, we used data from a total of five adolescents (14–15 years old) from the WUMinn HCP database2, which was acquired using a 3T scanner with a maximum gradient strength of 70–100mT/m for diffusion MRI. As the target domain, we used data from a total of ten adult subjects (20–59 years old) from the MGH HCP database3 acquired using the customized MGH Siemens 3T Connectome scanner, which has a maximum gradient strength of 300mT/m. Prior to synthesis, each T1-weighted MRI was affinely registered to its corresponding b0 image using the cross-correlation similarity metric with the ANTs toolkit (Avants et al., 2011). Each subject in the WUMinn and MGH HCP databases has a total of 93 and 96 paired slices, respectively. The diffusion tensor was reconstructed using the DIPY library (Garyfallidis et al., 2014) with the tensor model (Basser et al., 1994), and then FA volumes were computed. For evaluation, we adopted a five-fold cross-validation strategy for the ten subjects in the target domain, using two subjects for testing in each round, while using the remaining eight subjects for training and validation.
We provide qualitative comparisons against the adversarial UDA methods GAUDA (Cui et al., 2020) and ADDA (Tzeng et al., 2017) in Fig. 9. We carried out one-tailed paired t-tests for each of the L1, SSIM, PSNR, and IS metrics to compare improvements over BM:GST with AC:GST. The resulting p-values were 0.014, 0.012, 0.0076, and 6.09 × 10−4, respectively, indicating statistical significance. When comparing AC:GST with JGLA, we obtained p-values of 0.0037, 0.0016, 2.65×10−4, and 5.49 × 10−5 for the L1, SSIM, PSNR, and IS metrics, respectively, also indicating statistical significance. The ablation study results are shown in Fig. 10. In addition, the corresponding quantitative results are given in Table 3. In contrast to the tagged-to-cine MR translation task, our AC:GST framework outperformed the Pix2Pix baseline and adversarial UDA methods by a large margin. Of note, we empirically set weight and , and provide the sensitivity analysis in Fig. 11. The results indicate that the performance of our model is relatively consistent for and .
Fig. 9.

Comparison of our framework with the adversarial UDA (Cui et al., 2020; Yarram et al., 2022) and Pix2Pix (Isola et al., 2017) without adaptation for the WUMinn-MGH cross-center T1-to-FA brain MR image translation. The red rectangle highlights the region with noticeable artifacts.
Fig. 10.

Ablation studies of our proposed AC:GST, BM:GST, BM:GST-A, and BM:GST-E for WUMinn-MGH cross-center T1-to-FA brain MR image translation. The red rectangle highlights the region with noticeable artifacts.
Table 3.
Numerical comparisons and ablation studies of the WUMinn-MGH cross-center brain T1-to-FA MR translation task
| Methods | L1 ↓ | SSIM ↑ | PSNR ↑ | IS ↑ |
|---|---|---|---|---|
|
| ||||
| w/o UDA (Isola et al., 2017) | 158.5±0.4 | 0.8264±0.0017 | 25.49±0.06 | 9.27±0.14 |
|
| ||||
| ASS (He et al., 2021) | 132.8±0.3 | 0.8847±0.0014 | 31.63±0.04 | 11.54±0.10 |
|
| ||||
| ADDA (Tzeng et al., 2017) | 129.2±0.4 | 0.9131±0.0016 | 34.85±0.05 | 13.28±0.12 |
| GAUDA (Cui et al., 2020) | 129.0±0.5 | 0.9174±0.0015 | 35.24±0.06 | 13.46±0.13 |
| JGLA (Yarram et al., 2022) | 128.6±0.2 | 0.9205±0.0016 | 35.22±0.03 | 13.50±0.12 |
|
| ||||
| AC:GST | 121.2±0.3 | 0.9692±0.0014 | 38.65±0.04 | 16.42±0.14 |
| AC:GST- | 122.0±0.3 | 0.9637±0.0014 | 37.94±0.04 | 16.05±0.12 |
| AC:GST-C | 121.7±0.3 | 0.9641±0.0014 | 38.26±0.06 | 15.97±0.13 |
| BM:GST (Liu et al., 2021d) | 122.8±0.3 | 0.9563±0.0014 | 37.65±0.04 | 15.12±0.12 |
| BM:GST-A | 123.5±0.4 | 0.9488±0.0016 | 37.30±0.06 | 14.61±0.11 |
| BM:GST-E | 122.9±0.2 | 0.9532±0.0015 | 37.16±0.04 | 14.69±0.13 |
|
| ||||
| Target Supervised | 114.6±0.3 | 0.9815±0.0013 | 42.27±0.06 | 18.83±0.10 |
Fig. 11.

Sensitivity analysis of in AC:GST with respect to L1 error for WUMinn-MGH cross-center T1-to-FA MR image translation.
5. Discussion and Conclusion
In this work, we proposed a novel generative self-training framework with adaptively learned attention for two unsupervised domain adaptive medical image translation tasks. By equipping the self-training framework with a unified uncertainty quantification scheme for both epistemic and aleatoric uncertainties in a UDA setting, we were able to adaptively control the generative pseudo-label supervision according to the reliability of the pseudo-labels. This was the first attempt at achieving the UDA of tagged-to-cine and structure-to-diffusion (e.g., T1-to-FA) image translation. Our experimental results clearly showed that, when quantitatively and qualitatively assessed, our framework yielded superior translation performance over popular adversarial UDA methods. The synthesized cine MR or FA images with test time UDA could be utilized to delineate the tongue and to observe surface motion or quantify micro-structural tissue properties, without the need for additional acquisition costs and time (Gu et al., 2019).
This work aimed to achieve adaptation with limited unpaired target data and fast convergence in the test-time UDA setting (Karani et al., 2021). We were able to improve synthesis performance for an unseen subject, by retraining with its input slices. Many UDA methods use both paired source domain data and unpaired target domain data for joint training at the adaptation stage. In comparison, our AC:GST and BM:GST training took approximately 50 and 30 minutes, respectively, for within UMB cross-scanner tagged-to-cine UDA, whereas GAUDA (Cui et al., 2020) took 2 hours to train. Furthermore, synthesizing one slice in testing took only about 0.1 seconds. We note that Zuo et al. (2021) is not applicable for test-time UDA evaluation since it requires target domain sample labels. Additionally, the performance of source-free test-time adaptation (He et al., 2021; Liu et al., 2021b; Karani et al., 2021) may degrade without the supervision of source domain data in adaptation.
Our framework has notable features as follows. First, instead of setting pseudo-labels as a variable with one-hot or all zero vectors as in conventional self-training methods (Zou et al., 2019; Wei et al., 2021; Liu et al., 2020), our GST framework leverages the reliability mask as a learned variable to help control pseudo-label selection. In this way, we can flexibly adjust the contribution of each pseudo-labeled pixel for the image translation tasks. Second, we incorporate both aleatoric and epistemic uncertainties in our generative self-training UDA using a Bayesian reliability mask in a principled manner. Specifically, both types of uncertainty are utilized to compensate for the inherently noisy pseudo-labels during self-training. The results of our ablation studies in Tables 1–3 show that taking both of them into consideration can contribute to improved performance. Figures 5, 8, and 10 illustrate that when aleatoric uncertainty resulting from inaccurate labels is not accounted for, BM:GST-A produces results with slight distortions in shape and boundary. On the other hand, when epistemic uncertainty is not considered, BM:GST-E tends to generate noisier outputs compared with BM:GST. An advanced uncertainty measurement can potentially be added to achieve either more accurate quantification or faster inference. A third notable feature in our GST framework is that the correlation between the quantified uncertainty of pseudo-labels and the reliability mask is flexibly defined. Although the binary reliability mask with threshold-based pseudo-label selection in Eq. (8) can be a straightforward solution to convert the quantified uncertainty as a reliability measurement of pseudo-labels, it can be too rough to be applied to our well-quantified uncertainty. The fine-grained continuous reliability mask that we propose contributes to the better performance of AC:GST- over BM:GST, as shown in Tables 1–3. A fourth notable feature in our framework is that self-attention was added to adaptively emphasize the regions of interest. Medical imaging data, particularly MR imaging data, often have homogeneous background areas. As a result, in synthesis tasks, pixels in the background region usually undergo a simple identity mapping, which is easy to learn and has low uncertainty, resulting in high reliability predictions in the early epochs. This dominance of easily learned pixels could result in their overrepresentation in the GST, without compensation. Our results, as shown in Tables 1–3, consistently demonstrated that our AC:GST, which includes an adaptive emphasis on regions of interest, outperformed AC:GST-.
A few important components have not been fully investigated in the present work. First, although we applied our framework to MR image translation tasks, the idea of the variable reliability mask and the continuous reliability mask may also be helpful for discriminative self-training UDA with more accurate uncertainty measurement than the maximum softmax probability. Second, it is worth noting that our investigation only focused on the scenario, where the source and target domain models share the same backbone, which is a common approach in UDA. However, different backbones in the source and target domain can also be used, by initializing the target model with knowledge distillation (Liu et al., 2022a). Third, since our framework has shown superior performance for the challenging test-time UDA task, our framework is likely to yield better performance, when taking more unpaired target domain subjects in training. We will investigate different input data and UDA scenarios to confirm the full potential and utility of the proposed framework in our future work.
Fig. 2.

Illustration of the proposed generative self-training UDA with a self-attentive continuous reliability mask (AC:GST) for tagged-to-cine tongue MR image translation. Our framework involves two steps in each iteration, alternating updates of the networks and the pseudo-labels with their reliability masks.
Acknowledgments
We gratefully acknowledge funding support from NIH R01DC014717, R01DC018511, R01CA133015, and P41EB022544.
Footnotes
It can be rewritten as . Since , , an upper bound on can be obtained as .
Link to WUMinn HCP database
Link to MGH HCP database
References
- Abdar M., Pourpanah F., Hussain S., Rezazadegan D., Liu L., Ghavamzadeh M., Fieguth P., Cao X., Khosravi A., Acharya U.R., et al. , 2021. A review of uncertainty quantification in deep learning: Techniques, applications and challenges. Information Fusion 76, 243–297. [Google Scholar]
- Armanious K., Jiang C., Fischer M., Küstner T., Hepp T., Nikolaou K., Gatidis S., Yang B., 2020. Medgan: Medical image translation using gans. Computerized Medical Imaging and Graphics 79, 101684. [DOI] [PubMed] [Google Scholar]
- Avants B.B., Tustison N.J., Song G., Cook P.A., Klein A., Gee J.C., 2011. A reproducible evaluation of ants similarity metric performance in brain image registration. Neuroimage 54, 2033–2044. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Basser P.J., Mattiello J., LeBihan D., 1994. Mr diffusion tensor spectroscopy and imaging. Biophysical journal . [DOI] [PMC free article] [PubMed] [Google Scholar]
- Begoli E., Bhattacharya T., Kusnezov D., 2019. The need for uncertainty quantification in machine-assisted medical decision making. Nature Machine Intelligence 1, 20–23. [Google Scholar]
- Carvalho E.D., Clark R., Nicastro A., Kelly P.H., 2020. Scalable uncertainty for computer vision with functional variational inference, in: CVPR, pp. 12003–12013. [Google Scholar]
- Chartsias A., Joyce T., Giuffrida M.V., Tsaftaris S.A., 2017. Multimodal mr synthesis via modality-invariant latent representation. IEEE transactions on medical imaging 37, 803–814. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cheng Y., Wei F., Bao J., Chen D., Zhang W., 2023. Adpl: Adaptive dual path learning for domain adaptation of semantic segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence . [DOI] [PubMed] [Google Scholar]
- Cui S., Wang S., Zhuo J., Su C., Huang Q., Tian Q., 2020. Gradually vanishing bridge for adversarial domain adaptation, in: CVPR. [Google Scholar]
- Der Kiureghian A., Ditlevsen O., 2009. Aleatory or epistemic? does it matter? Structural safety 31, 105–112. [Google Scholar]
- Dorent R., Kujawa A., Ivory M., Bakas S., Rieke N., Joutard S., Glocker B., Cardoso J., Modat M., Batmanghelich K., et al. , 2023. Crossmoda 2021 challenge: Benchmark of cross-modality domain adaptation techniques for vestibular schwannoma and cochlea segmentation. Medical Image Analysis 83, 102628. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fruehwirt W., Cobb A.D., Mairhofer M., Weydemann L., Garn H., Schmidt R., Benke T., Dal-Bianco P., Ransmayr G., Waser M., et al. , 2018. Bayesian deep neural networks for low-cost neurophysiological markers of alzheimer’s disease severity. arXiv:1812.04994. [Google Scholar]
- Gal Y., Ghahramani Z., 2015. Bayesian convolutional neural networks with bernoulli approximate variational inference. arXiv:1506.02158 . [Google Scholar]
- Garyfallidis E., Brett M., Amirbekian B., Rokem A., Van Der Walt S., Descoteaux M., Nimmo-Smith I., Contributors D., 2014. Dipy, a library for the analysis of diffusion mri data. Frontiers in neuroinfo . [DOI] [PMC free article] [PubMed] [Google Scholar]
- Goodfellow I., Bengio Y., Courville A., Bengio Y., 2016. Deep learning. volume 1. MIT Press. [Google Scholar]
- Grandvalet Y., Bengio Y., 2006. Entropy regularization.
- Gu X., Knutsson H., Nilsson M., Eklund A., 2019. Generating diffusion mri scalar maps from t1 weighted images using generative adversarial networks, in: SCIA. [Google Scholar]
- Gulrajani I., Ahmed F., Arjovsky M., Dumoulin V., Courville A.C., 2017. Improved training of wasserstein gans. NeurIPS 30. [Google Scholar]
- Han L., Zou Y., Gao R., Wang L., Metaxas D., 2019. Unsupervised domain adaptation via calibrating uncertainties, in: CVPR. [Google Scholar]
- He Y., Carass A., Zuo L., Dewey B.E., Prince J.L., 2021. Autoencoder based self-supervised test-time adaptation for medical image analysis. Medical image analysis 72, 102136. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hu S., Worrall D., Knegt S., Veeling B., Huisman H., Welling M., 2019. Supervised uncertainty quantification for segmentation with multiple annotations, in: MICCAI, Springer. pp. 137–145. [Google Scholar]
- Isola P., Zhu J.Y., Zhou T., Efros A.A., 2017. Image-to-image translation with conditional adversarial networks, in: CVPR, pp. 1125–1134. [Google Scholar]
- Kaji S., Kida S., 2019. Overview of image-to-image translation by use of deep neural networks: denoising, super-resolution, modality conversion, and reconstruction in medical imaging. Radiological physics and technology 12, 235–248. [DOI] [PubMed] [Google Scholar]
- Karani N., Erdil E., Chaitanya K., Konukoglu E., 2021. Test-time adaptable neural networks for robust medical image segmentation. Medical Image Analysis 68, 101907. [DOI] [PubMed] [Google Scholar]
- Kendall A., Gal Y., 2017. What uncertainties do we need in bayesian deep learning for computer vision? arXiv:1703.04977 . [Google Scholar]
- Kong L., Hu B., Liu X., Lu J., You J., Liu X., 2022. Constraining pseudo-label in self-training unsupervised domain adaptation with energy-based model. International Journal of Intelligent Systems 37, 8092–8112. [Google Scholar]
- Kumar M.P., Packer B., Koller D., 2010. Self-paced learning for latent variable models, in: NeurIPS, pp. 1189–1197. [Google Scholar]
- Le Q.V., Smola A.J., Canu S., 2005. Heteroscedastic gaussian process regression, in: ICML. [Google Scholar]
- Li K., Wang S., Yu L., Heng P.A., 2020. Dual-teacher++: Exploiting intra-domain and inter-domain knowledge with reliable transfer for cardiac segmentation. IEEE Transactions on Medical Imaging 40, 2771–2782. [DOI] [PubMed] [Google Scholar]
- Liu X., Guo Z., Li S., Xing F., You J., Kuo C.C.J., El Fakhri G., Woo J., 2021a. Adversarial unsupervised domain adaptation with conditional and label shift: Infer, align and iterate, in: ICCV. [Google Scholar]
- Liu X., Hu B., Liu X., Lu J., You J., Kong L., 2020. Energy-constrained self-training for unsupervised domain adaptation. ICPR . [Google Scholar]
- Liu X., Xing F., El Fakhri G., Woo J., 2021b. Adapting off-the-shelf source segmenter for target medical image segmentation, in: MICCAI. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liu X., Xing F., Prince J.L., Carass A., Stone M., El Fakhri G., Woo J., 2021c. Dual-cycle constrained bijective vae-gan for tagged-to-cine magnetic resonance image synthesis, in: ISBI. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liu X., Xing F., Stone M., Zhuo J., Reese T., Prince J.L., El Fakhri G., Woo J., 2021d. Generative self-training for cross-domain unsupervised tagged-to-cine mri synthesis, in: MICCAI, Springer. pp. 138–148. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liu X., Yoo C., Xing F., Kuo C.C.J., El Fakhri G., Kang J.W., Woo J., 2022a. Unsupervised black-box model domain adaptation for brain tumor segmentation, in: Frontiers in Neuroscience. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liu X., Yoo C., Xing F., Oh H., El Fakhri G., Kang J., Woo J., 2022b. Deep unsupervised domain adaptation: A review of recent advances and perspectives. APSIPA Trans . [Google Scholar]
- Long J., Shelhamer E., Darrell T., 2015. Fully convolutional networks for semantic segmentation, in: CVPR, pp. 3431–3440. [DOI] [PubMed] [Google Scholar]
- Mei K., Zhu C., Zou J., Zhang S., 2020. Instance adaptive self-training for unsupervised domain adaptation. ECCV . [Google Scholar]
- Nix D.A., Weigend A.S., 1994. Estimating the mean and variance of the target probability distribution, in: ICNN. [Google Scholar]
- Osman N.F., McVeigh E.R., Prince J.L., 2000. Imaging heart motion using harmonic phase mri. IEEE transactions on medical imaging 19, 186–202. [DOI] [PubMed] [Google Scholar]
- Parthasarathy V., Prince J.L., Stone M., Murano E.Z., NessAiver M., 2007. Measuring tongue motion from tagged cine-MRI using harmonic phase (HARP) processing. JASA 121. [DOI] [PubMed] [Google Scholar]
- Rasmussen C.E., 2003. Gaussian processes in machine learning, in: Summer school on machine learning, Springer. pp. 63–71. [Google Scholar]
- Shen Y., Zhang Z., Sabuncu M.R., Sun L., 2021. Real-time uncertainty estimation in computer vision via uncertainty-aware distribution distillation, in: WACV, pp. 707–716. [Google Scholar]
- Shin I., Woo S., Pan F., Kweon I.S., 2020. Two-phase pseudo label densification for self-training based domain adaptation, in: ECCV. [Google Scholar]
- Tang K., Ramanathan V., Fei-Fei L., Koller D., 2012. Shifting weights: Adapting object detectors from image to video, in: NIPS. [Google Scholar]
- Triguero I., García S., Herrera F., 2015. Self-labeled techniques for semi-supervised learning: taxonomy, software and empirical study. Knowledge and Information Systems 42, 245–284. [Google Scholar]
- Tzeng E., Hoffman J., Saenko K., Darrell T., 2017. Adversarial discriminative domain adaptation, in: CVPR. [Google Scholar]
- Wang M., Deng W., 2018. Deep visual domain adaptation: A survey. Neurocomputing 312, 135–153. [Google Scholar]
- Wang W., Zhang H., Yuan Z., Wang C., 2021. Unsupervised real-world super-resolution: A domain adaptation perspective, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4318–4327. [Google Scholar]
- Wei C., Shen K., Chen Y., Ma T., 2021. Theoretical analysis of self-training with deep networks on unlabeled data. arXiv:2010.03622 . [Google Scholar]
- Wilson G., Cook D.J., 2020. A survey of unsupervised deep domain adaptation. ACM TIST 11, 1–46. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Xie G., Wang J., Huang Y., Zheng Y., Zheng F., Jin Y., 2022a. A survey of cross-modality brain image synthesis. arXiv:2202.06997 . [Google Scholar]
- Xie Q., Li Y., He N., Ning M., Ma K., Wang G., Lian Y., Zheng Y., 2022b. Unsupervised domain adaptation for medical image segmentation by disentanglement learning and self-training. IEEE Transactions on Medical Imaging . [DOI] [PubMed] [Google Scholar]
- Xing F., Woo J., Lee J., Murano E.Z., Stone M., Prince J.L., 2016. Analysis of 3-D tongue motion from tagged and cine magnetic resonance images. JSLHR . [DOI] [PMC free article] [PubMed] [Google Scholar]
- Xing F., Woo J., Murano E.Z., Lee J., Stone M., Prince J.L., 2013. 3d tongue motion from tagged and cine mr images, in: MICCAI, Springer. pp. 41–48. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Xu G.X., Liu C., Liu J., Ding Z., Shi F., Guo M., Zhao W., Li X., Wei Y., Gao Y., et al. , 2021. Cross-site severity assessment of covid-19 from ct images via domain adaptation. TMI . [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yarram S., Yang M., Yuan J., Qiao C., 2022. Joint global-local alignment for domain adaptive semantic segmentation, in: ICASSP. [Google Scholar]
- Zhan B., Li D., Wu X., Zhou J., Wang Y., 2021. Multi-modal mri image synthesis via gan with multi-scale gate mergence. IEEE Journal of Biomedical and Health Informatics 26, 17–26. [DOI] [PubMed] [Google Scholar]
- Zhao Z., Zhou F., Xu K., Zeng Z., Guan C., Zhou S.K., 2022. Le-uda: Label-efficient unsupervised domain adaptation for medical image segmentation. IEEE Transactions on Medical Imaging . [DOI] [PubMed] [Google Scholar]
- Zhou T., Fu H., Chen G., Shen J., Shao L., 2020. Hi-net: hybrid-fusion network for multi-modal mr image synthesis. IEEE transactions on medical imaging 39, 2772–2781. [DOI] [PubMed] [Google Scholar]
- Zhu X., 2007. Semi-supervised learning tutorial, in: ICML tutorial. [Google Scholar]
- Zou Y., Yu Z., Liu X., Kumar B., Wang J., 2019. Confidence regularized self-training, in: ICCV, pp. 5982–5991. [Google Scholar]
- Zou Y., Yu Z., Vijaya Kumar B.V.K., Wang J., 2018. Unsupervised domain adaptation for semantic segmentation via class-balanced self-training, in: ECCV. [Google Scholar]
- Zuo L., Dewey B.E., Carass A., Liu Y., He Y., Calabresi P.A., Prince J.L., 2021. Information-based disentangled representation learning for unsupervised mr harmonization, in: IPMI, Springer. pp. 346–359. [Google Scholar]