
Fig. 6.
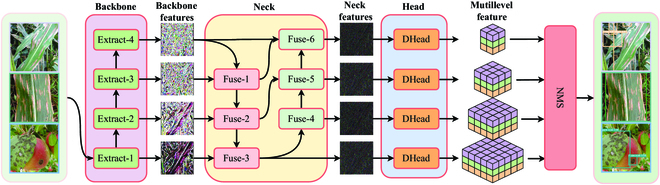
Architecture of the teacher model. The input image is converted to 4 backbone features with different semantic levels by 4 unique feature extraction stages of the backbone part, namely, extraction-1, extraction-2, extraction-3, and extraction-4, respectively. Then, the neck part uses the fusion modules to combine the backbone features to generate 4 neck features that encapsulate different levels of semantic information. Finally, the head part translates the neck features into multilevel features.