
Table 1. Imperfectly interoperable (IIO) data sets.
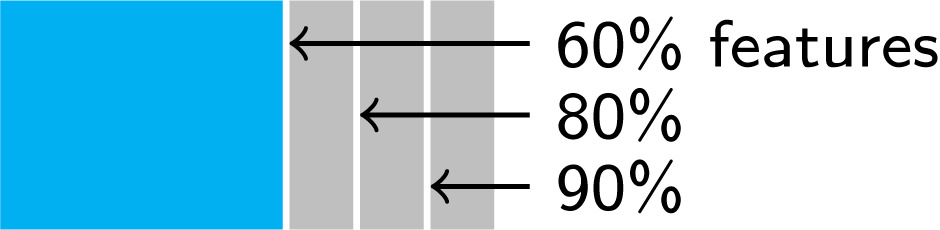
From the 3,192-patient CDSS-derived data set, we create two training sets with three levels of imperfect feature overlap (60, 80 and 90%) compared with perfect interoperability (100%). In our experiments, the owner of a small ‘target’ data set (fewer patients) wants to benefit from a larger ‘source’ data set without having access to this data. The ‘source’ may lack several features that are available in the ‘target’, yielding several levels of ‘imperfect interoperability’. We construct validation sets with and without these missing features, as well as a held-out test set. The F1 scores we report in this paper are averages over five randomized folds of this data-splitting procedure.
| Split | Partition | Patients | Interoperable | Imperfectly interoperable |
|---|---|---|---|---|
| Train | Source (A) | 2 068 |

|
|
| Target (B) | 516 |

|

|
|
| Validation | Source | 288 |

|

|
| Target | 288 |

|

|
|
| Test | Source | 288 |

|

|