
Fig. 1.
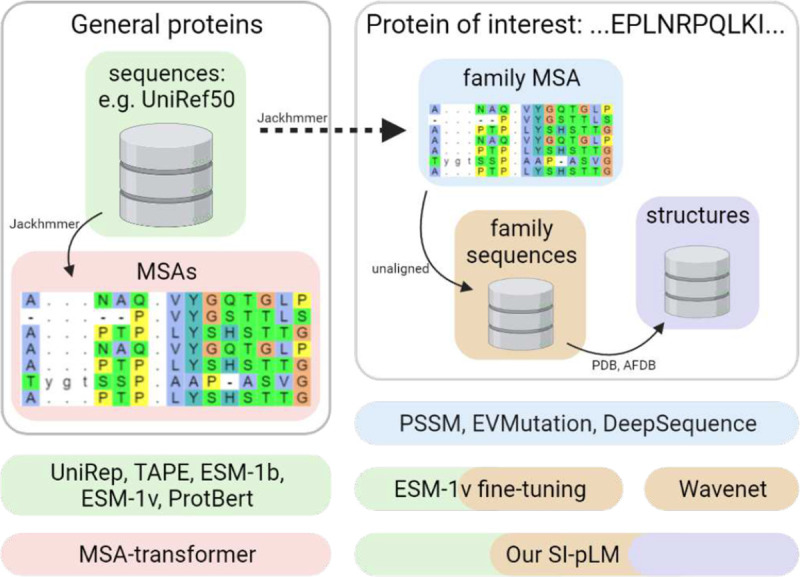
Conceptual differences among competing methods and our structure-informed protein language models (SI-pLMs) from the data perspective. Whereas many family-specific models are trained over aligned (blue) or unaligned sequences (orange) in a protein family, pLMs are often pre-trained over unaligned (green) or aligned sequences (red) in the protein universe and some of them can be fine-tuned over family sequences. In contrast, our SI-pLMs after pretraining are finetuned with both family datasets of sequences and structures.