
Figure 1. Overview of Study of Derivation of Protein Risk Score, Polygenic Risk Scores, and the Comparative Analysis.
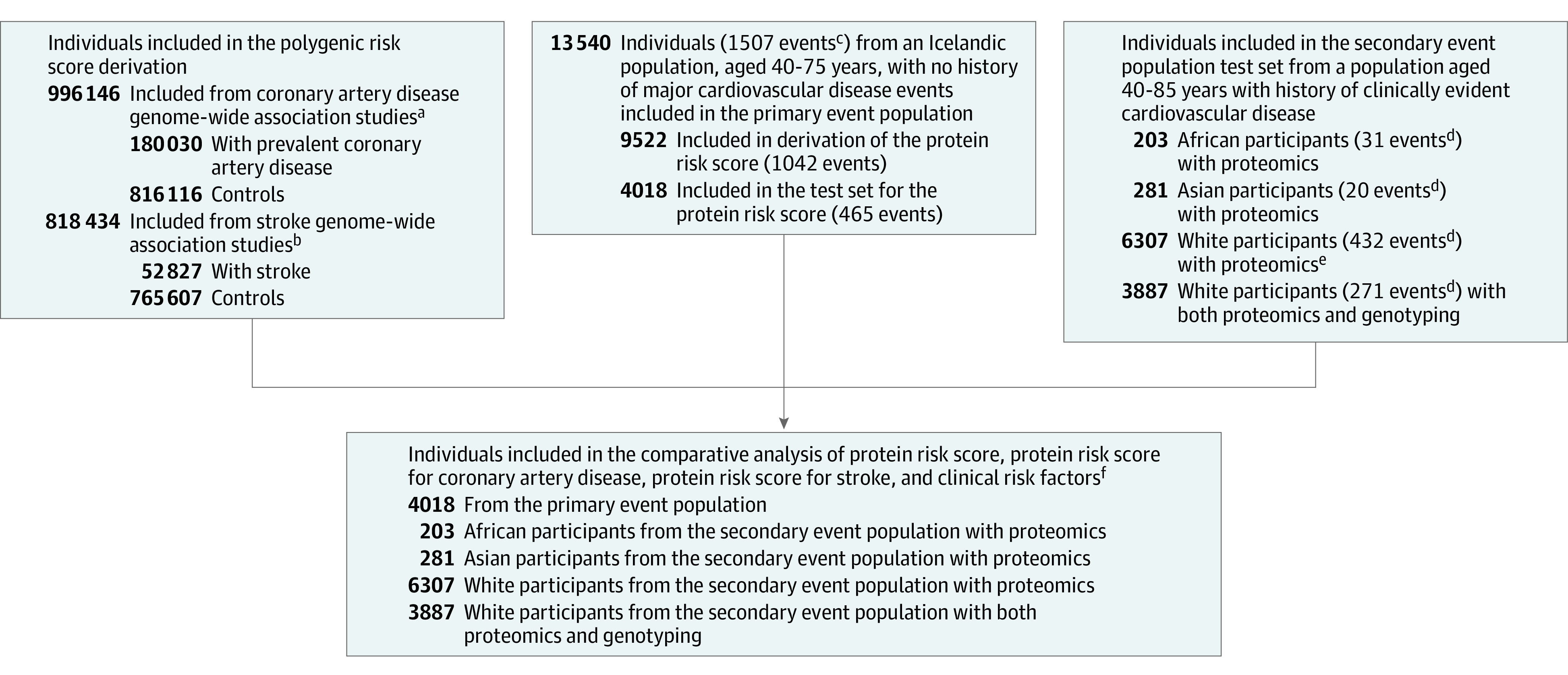
The diagram gives an overview of the populations used and how the study is divided into derivation and testing data sets. Some boxes do not show total individuals because subcategories are not mutually exclusive.
aPopulation sources: UK Biobank, FinnGen, Copenhagen Hospital Biobank (part of the Genetics of Cardiovascular Disease Study), Danish Blood Donor Study, and CARDIoGRAMplusC4D.
bPopulation sources: UK Biobank, Finngen, and Megastroke.
cComposite end point of first myocardial infarction, first stroke, or coronary heart disease death.
dIndicates the composite end point of myocardial infarction, stroke, or cardiovascular disease death.
eThe counts for the proteomics set include those with both proteomics and genotyping (ie, the sets are not mutually exclusive).
fTest data for this analysis were separate from derivation of polygenic and protein risk scores.