
Figure 1:
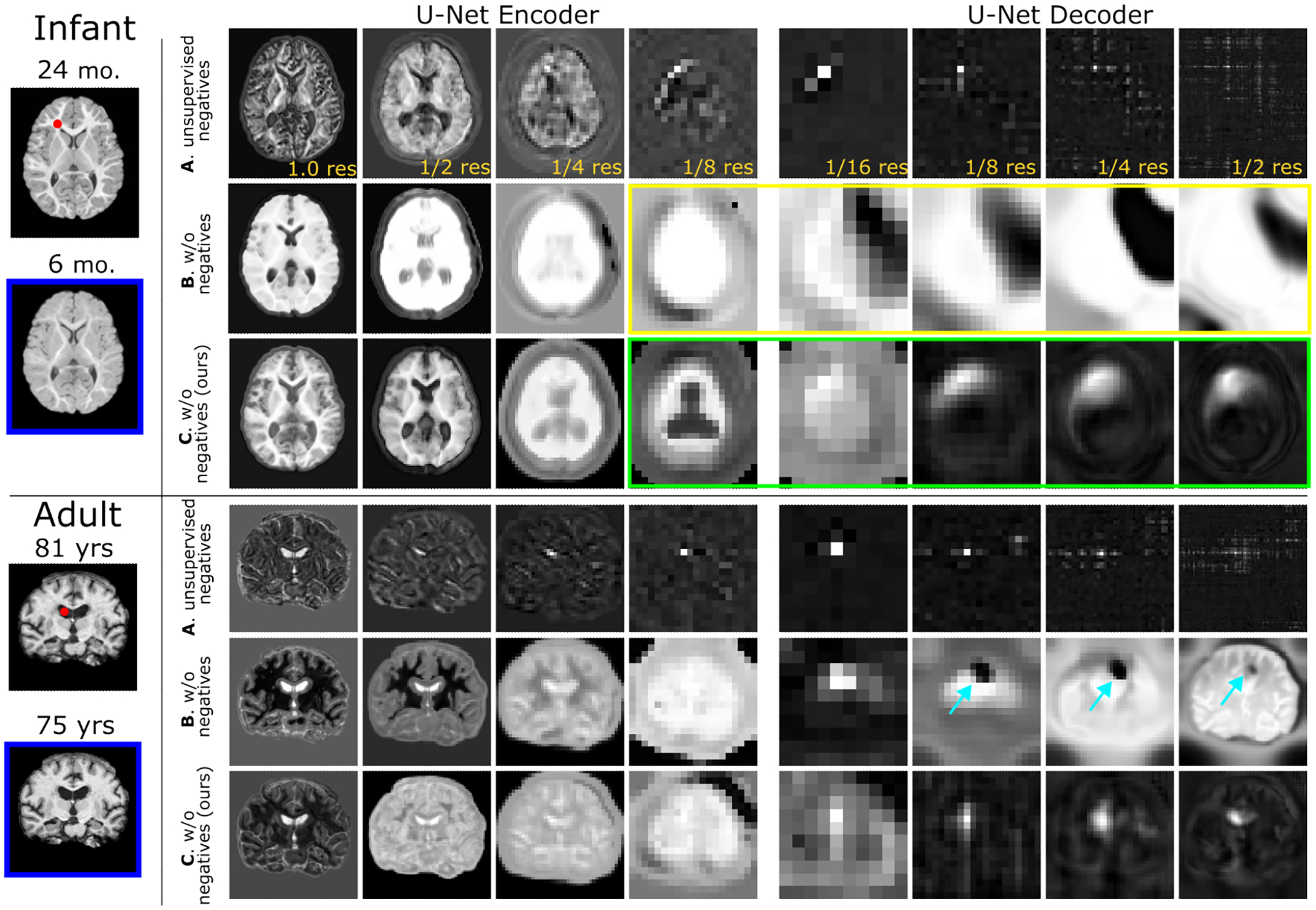
On pretraining an image-to-image network with per-layer spatiotemporal self-supervision, we visualize the intra-subject multi-scale feature similarity between a query channel-wise feature and all spatial positions within the key feature at a different age. A: Contrastive pretraining with unsupervised negatives [44] yields only positionally-dependent representations. B: Pretraining w/o negatives [11] by using corresponding intra-subject patch locations as positives leads to semanticallyimplausible representations with low-diversity (e.g., see yellow box) and artifacts (see arrows) in deeper layers. C: Our method attains both positionally and anatomically-relevant representations via proper regularization (e.g., see green box). Additional structures are visualized in Suppl. Figure 5.