
Figure 3. Transcript quantification on spike-in data shows improvement with varying novel discovery rates.
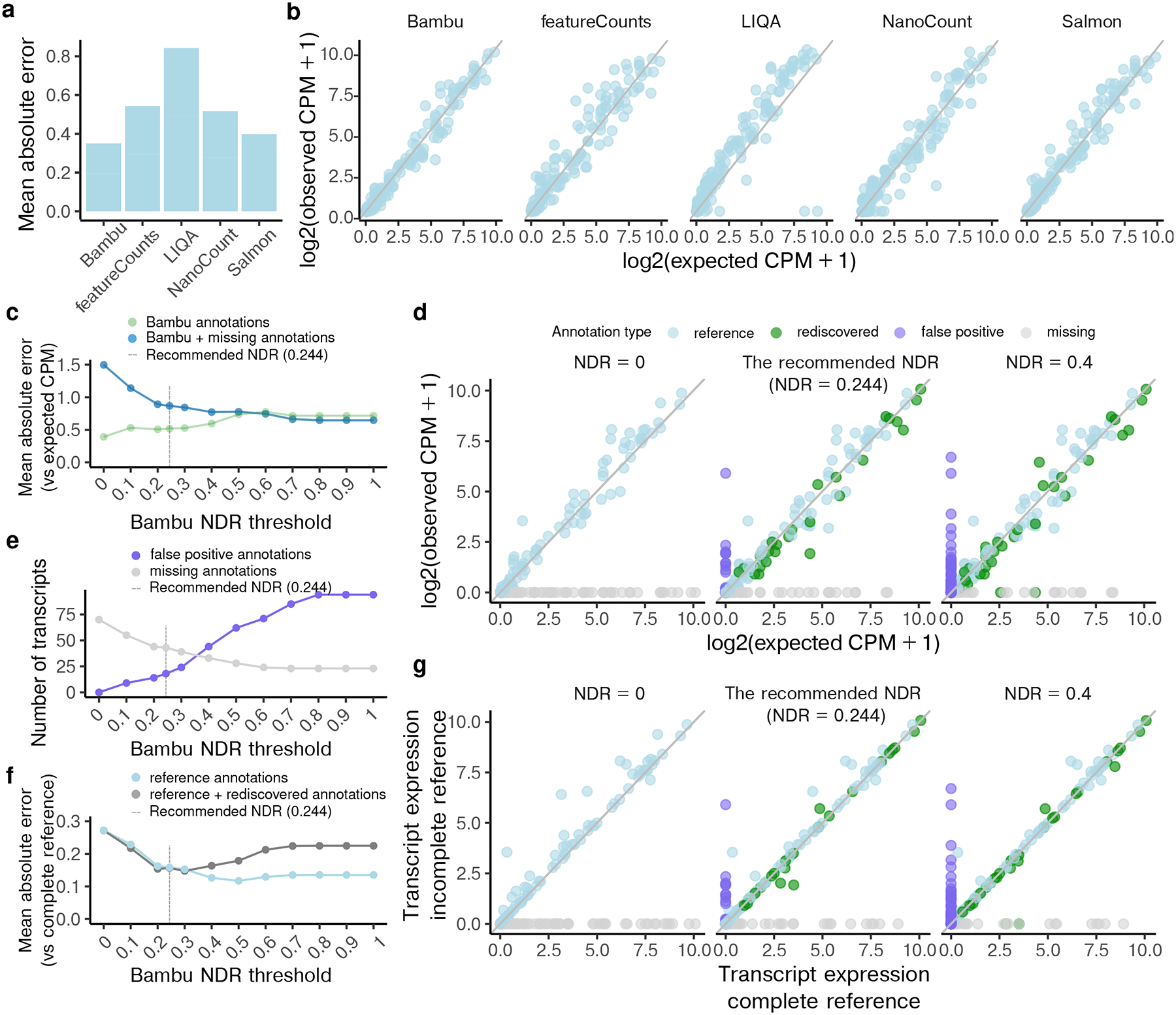
(a) The mean absolute error (MAE) and (b) the scatterplots between log2 normalised transcript abundance estimates and expected spike-in abundance when applying Bambu, featureCounts, LIQA, NanoCount, and Salmon using full sequin annotations (c) The MAE between the log2 normalised transcript abundance estimates and expected spike-in abundance when applying Bambu using partial sequin annotation and with varying novel discovery rate (NDR) thresholds, for Bambu annotated transcripts, including annotations that are present in the reference (partial) sequin annotations, the annotations that have been artificially removed and rediscovered by Bambu, and also the false positive annotations discovered by Bambu (green), plus the annotations that are artificially removed from the partial annotation and remained missing after transcript discovery, i.e., missing annotations (blue) (d) The scatterplots between log2 normalised transcript abundance estimates and expected spike-in abundance when applying Bambu using partial annotations: without transcript discovery (NDR = 0), with default recommended NDR (0.244), and with a more sensitive NDR (0.4) (e) The number of missing (grey) and false positive (purple) transcripts when applying Bambu using partial sequin annotations with varying NDR thresholds (f) The MAE between log2 normalised spike-in transcript abundance estimates when applying Bambu using full sequin annotation and using partial sequin annotation with varying NDR thresholds, for transcripts that are present in reference (light blue), transcripts that are present in reference and those rediscovered annotations (dark grey) (g) The scatterplots between log2 normalised transcript abundance estimates when applying Bambu using full sequin annotation and applying Bambu using partial sequin annotations: without transcript discovery (NDR = 0), with default recommended NDR (0.244), and with a more sensitive NDR (0.4) For (d) and (g), light blue dots represent transcripts that are present in the partial sequin annotations, green dots represent transcripts that have been artificially removed from the reference and rediscovered by Bambu, purple dots represent false positive transcripts, grey dots represent transcripts that have been artificially removed from the reference and remained missing after Bambu discovery. For (c), (e), and (f), the grey dotted line indicates the recommended NDR by Bambu (0.244)