
Figure 4.
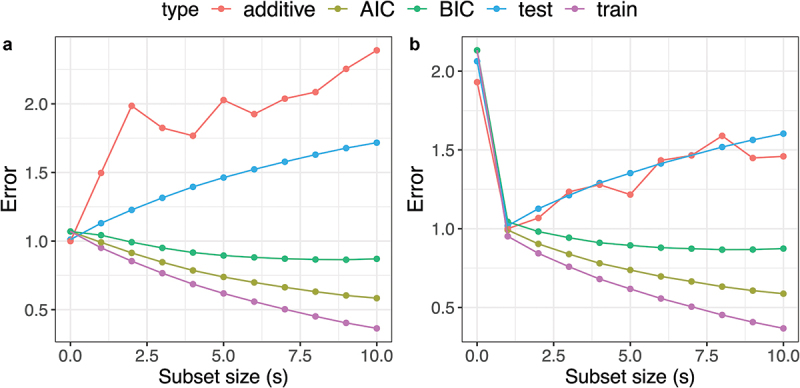
A comparison of error estimate from additive randomization (denoted as “additive”), AIC, BIC, the true prediction error (denoted as “test”), and training error (denoted as “train”) in example 2. Panels a and B shows the results for and respectively as we vary the subset size (. The prediction performance in this example is not able to be tracked by the training error, AIC or BIC.