
Table 3.
Comparisons for fitness predictors. Results were adopted from TopFit [20]. Performance was reported by average Spearman correlation over 34 DMS datasets and 20 repeats. Supervised model use ensemble regression from 18 regression models [20]
| Zero-shot predictors | ||||
| Model name | training set size | |||
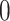
|
||||
| ESM-1b PLL [23, 33] | 0.435 | |||
| eUniRep PLL [127] | 0.411 | |||
| EVE [40] | 0.497 | |||
| Tranception [15] | 0.478 | |||
| DeepSequence [22] | 0.504 | |||
| Supervised models | ||||
| Embedding name | training set size | |||
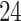
|
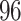
|
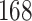
|
|
|
| Persistent homology [20] | 0.263 | 0.432 | 0.496 | 0.534 |
| Persistent Laplacian [20] | 0.280 | 0.457 | 0.525 | 0.564 |
| ESM-1b [23] | 0.219 | 0.421 | 0.494 | 0.537 |
| eUniRep [43] | 0.259 | 0.432 | 0.485 | 0.515 |
| Georgiev [127] | 0.169 | 0.326 | 0.402 | 0.446 |
| UniRep [21] | 0.183 | 0.347 | 0.420 | 0.462 |
| Onehot | 0.132 | 0.317 | 0.400 | 0.450 |
| Bepler [42] | 0.139 | 0.287 | 0.353 | 0.396 |
| TAPE LSTM [41] | 0.259 | 0.436 | 0.492 | 0.522 |
| TAPE ResNet [41] | 0.080 | 0.216 | 0.305 | 0.358 |
| TAPE transformer [41] | 0.146 | 0.304 | 0.371 | 0.418 |