
Fig. 7: Qualitative registration results.
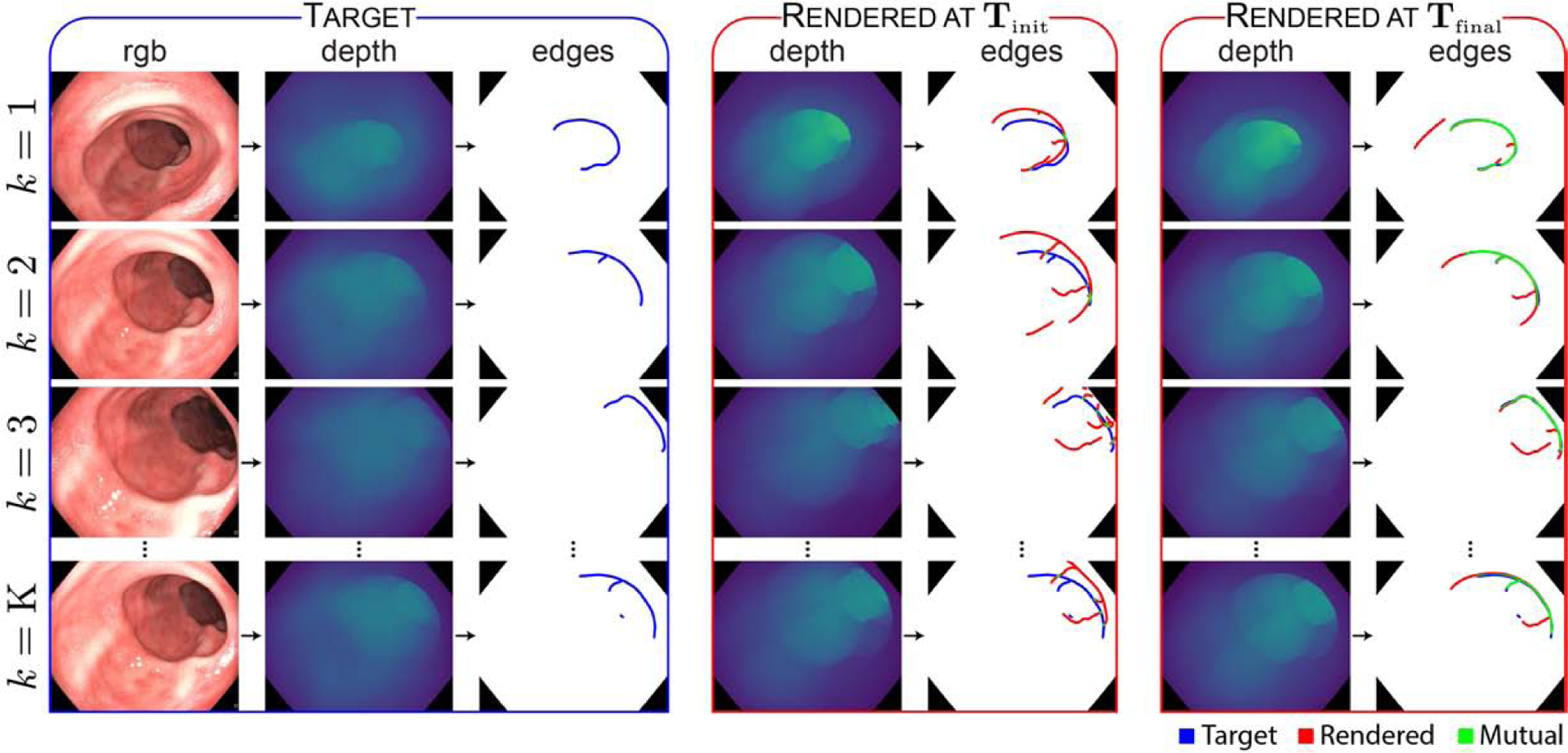
RGB video frames are transformed to the depth domain by a generative model, and target edge features are extracted. Edge features from rendered depth frames are compared with the target edge features to compute an alignment loss, and the predicted model transform is iteratively updated until alignment is achieved. Blurred edge features are binarized in this figure for visibility. See Supplementary Video I for a visual depiction of the improvement in registration as the optimization progresses.