

Abstract
Despite the known benefits of data‐driven approaches, the lack of approaches for identifying functional neuroimaging patterns that capture both individual variations and inter‐subject correspondence limits the clinical utility of rsfMRI and its application to single‐subject analyses. Here, using rsfMRI data from over 100k individuals across private and public datasets, we identify replicable multi‐spatial‐scale canonical intrinsic connectivity network (ICN) templates via the use of multi‐model‐order independent component analysis (ICA). We also study the feasibility of estimating subject‐specific ICNs via spatially constrained ICA. The results show that the subject‐level ICN estimations vary as a function of the ICN itself, the data length, and the spatial resolution. In general, large‐scale ICNs require less data to achieve specific levels of (within‐ and between‐subject) spatial similarity with their templates. Importantly, increasing data length can reduce an ICN's subject‐level specificity, suggesting longer scans may not always be desirable. We also find a positive linear relationship between data length and spatial smoothness (possibly due to averaging over intrinsic dynamics), suggesting studies examining optimized data length should consider spatial smoothness. Finally, consistency in spatial similarity between ICNs estimated using the full data and subsets across different data lengths suggests lower within‐subject spatial similarity in shorter data is not wholly defined by lower reliability in ICN estimates, but may be an indication of meaningful brain dynamics which average out as data length increases.
Keywords: functional connectivity (FC), functional templates, independent component analysis (ICA), intrinsic connectivity networks (ICNs)
Multi‐spatial‐scale intrinsic connectivity networks (ICNs) obtained using rsfMRI data from over 100k individuals across private and public datasets.

1. INTRODUCTION
1.1. Resting‐state functional MRI
Resting‐state functional MRI (rsfMRI) studies have significantly advanced our knowledge of both typical and disordered brain functional organization by evaluating the functional interactions across the brain using the blood‐oxygenation‐level‐dependent (BOLD) signal. While rsfMRI has several advantages that make its application in a wide range of clinical and research settings more feasible than task‐based fMRI paradigms, its clinical utility and application in single‐subject analyses have been limited.
Clinical applications and statistical inferences are generally built upon identifying and evaluating common patterns/features. In structural MRI analysis, we investigate unambiguous brain structures where changes in the properties of a given structure can be assessed as an indication of abnormality. The task‐based fMRI analysis captures the brain's response to well‐defined external tasks to identify and evaluate the task‐related features across individuals. However, because the ground truth of the functional entities within a given brain is unknown, the identification of the corresponding functional patterns across individuals is not straightforward for rsfMRI. The limitation of existing approaches to obtain comparable functional patterns across individuals and brain states in a way that accurately and precisely captures both individual variation and inter‐subject correspondence is one primary factor limiting rsfMRI applications.
Focusing on functional connectivity, the most common category of approaches uses anatomically fixed regions (i.e., existing atlases) and evaluates the functional connectivity (typically temporal correlation) between these regions. By using anatomically fixed regions, this category implicitly assumes the functional (connectivity) profile within each anatomically fixed region does not vary over time and is the same across individuals. However, many static and dynamic rsfMRI studies have challenged this strong assumption by identifying meaningful and replicable differences in the spatial patterns of functional entities both across subjects and within subjects over time (Boukhdhir et al., 2021; Erhardt et al., 2011; Iraji, Deramus, et al., 2019; Iraji, Fu, et al., 2019; Luo et al., 2021; Wang et al., 2015). The presence of within‐ and between‐subject spatial differences is further supported by task‐based fMRI findings showing that functional connectivity maps and spatial patterns of brain responses vary across individuals for a given task as well as within‐subject across mental states dictated by tasks (Calhoun et al., 2008; Krienen et al., 2014; Salehi et al., 2020; Sui et al., 2009; Wu et al., 2021). As a result, data‐driven approaches are gaining interest because they identify functional entities from the rsfMRI data itself and therefore incorporate spatial variabilities in calculating corresponding functional connectivity patterns.
1.2. Data‐driven approach for analyzing rsfMRI data
There are two main categories of data‐driven approaches. They either (1) estimate functional entities for each sample (e.g., subject) and then match them across samples or (2) obtain group‐level functional entities using entire samples (e.g., group‐level brain networks) and then use them as a reference to estimate corresponding functional entities for each sample. Early data‐driven approaches belong to the first category, including those that apply independent component analysis (ICA) to each subject's data to extract intrinsic connectivity networks (ICNs; as estimations of functional entities) and then perform a matching step (e.g., clustering) to identify the ICN correspondence across individuals. While this category of approaches has remained a matter of great interest with significant potential (Calhoun, Adali, McGinty, et al., 2001; Durieux & Wilderjans, 2019; Esposito et al., 2005; Gordon, Laumann, et al., 2017; Salehi et al., 2020), ambiguity and uncertainty that the matched functional entities represent the best corresponding functional patterns across individuals continued to be their major drawback. Studies have shown that a slight change in the seed location can result in significant differences in functional connectivity patterns (Yeo et al., 2011), indicating that finding the best‐matched patterns across individuals requires an extensive search across all possibilities. In the case of using functional parcellations as functional entities, this means searching for different sizes and locations across all individuals. In addition, extending the application to new unseen data, which is necessary for clinical application, requires special solutions as accessibility to the initial dataset and rerunning the process is not only practically unfeasible but importantly can lead to different functional patterns than the original analysis. Differences in data acquisition, such as different spatial and temporal resolutions, can also impact functional pattern identification. Finally, the signal‐to‐noise ratio (SNR) of rsfMRI adds yet another challenge, reducing the likelihood of finding the same functional entities across individuals. Finding corresponding functional entities is even more challenging when considering the dynamic nature of the brain and the fact that functional entities continuously evolve and have different spatial profiles (Iraji et al., 2020).
The second category of data‐driven approaches, also known as group‐informed approaches, has been deployed to overcome these limitations and enhance the identification of corresponding functional patterns across individuals (Calhoun, Adali, Pearlson, et al., 2001). These approaches utilize a template obtained from multiple subjects to guide the estimation of corresponding functional patterns for each individual. Leveraging a large number of subjects helps to compute a more reliable and generalizable estimation of functional entities, and using the common template for sample estimation of functional entities improves the identification of corresponding patterns across individuals. As a result, this category can be more beneficial for widespread clinical adoption as it enhances the possibility of comparing the same functional patterns (and their dynamic states) across individuals. Group ICA + back‐reconstruction is the most commonly used example of this category, which uses group‐level ICNs estimates to obtain corresponding subject‐level ICNs (Erhardt et al., 2011). Yet, two aspects must be improved to fully leverage this category's potential.
First, we need to obtain a reliable template (e.g., group‐level ICNs) that best represents all individuals. A key factor in achieving this goal is to recruit the largest possible dataset. As we increase the size of a dataset, the group‐level estimations get closer to the central tendency, and therefore, better represent all (seen and unseen) individuals. Second, we need to use well‐designed, group‐informed (e.g., reference‐guided or back‐reconstruction) network estimation techniques to identify corresponding subject‐specific functional patterns accurately and precisely. This step is important to prevent loss of subject‐specificity and meaningful inter‐ (and intra‐) individual differences. Multiple studies have shown that existing techniques capture individual‐level variations well (Allen et al., 2012; Erhardt et al., 2011), yet developing more advanced network estimation techniques (in addition to accurate estimation of a template) is a key element to bringing group‐informed approaches to perfection and transitioning to clinical applications of rsfMRI.
1.3. Toward perfecting group‐informed data‐driven approaches
Our main objective is to develop a standardized framework that leverages a very large dataset to obtain a reliable general template of functional entities and uses techniques that allow accurate subject‐specific estimation of these functional entities. This can lead to the systematic characterization of common and distinct alterations in functional patterns across cohorts (including among clinically overlapping disorders) and identifications of subject‐specific irregularities. This standardized framework makes identifying corresponding functional patterns for new subjects and comparing findings among datasets and across studies straightforward, which is of great need in the field. Moreover, because the estimation for each subject is independent of other subjects in the study, it becomes an ideal solution for both clinical applications as well as prediction analysis, which require complete separation of the training and testing data.
1.3.1. Using multi‐model‐order spatial ICA to obtain multi‐spatial‐scale canonical ICN templates
We apply multi‐model‐order spatial ICA (msICA; Iraji et al., 2022) to a large dataset (over 100k subjects) to generate a set of reliable ICNs that exist across different spatial scales (Iraji et al., 2022), from large‐scale spatially distributed ICNs (Damoiseaux et al., 2008; Iraji et al., 2016) to more spatially granular ICNs (Allen et al., 2011; Iraji, Faghiri, et al., 2019). The model order of ICA effectively sets the spatial scale of ICNs without imposing a direct spatial constraint (Iraji et al., 2022). This is a great advantage as the complexity varies across brain systems, and there is no reason to expect distinct regions (e.g., temporal lobe vs. the frontal lobe) or systems (e.g., the visual vs. the cognitive control) to have the same spatial scale across the brain functional hierarchy.
The second advantage of using msICA is its superior ability to estimate more reliable ICNs across different datasets. Briefly, the amount of variance that can be explained by a given IC relative to other ICs can vary across datasets, which impacts the principal components (PCs) retrieved by group‐level principal component analysis (PCA), and therefore the input for ICA decomposition. In other words, subject variability influences the data reduction steps prior to ICA decomposition, and hence the output of ICA. Variability in ICA estimations, such as statistical errors and several equally good local minima solutions, also impact the output of ICA decompositions, which we commonly minimize by running ICA several times and identifying the best run (Ma et al., 2011). Nonetheless, these sources of variability together lead to a better estimation of a given ICN at different model orders across different datasets. In layman's terms, a given ICN can be best identified either in one specific model order across datasets or in different model orders. Thus, by using ICA with multiple model orders, we can improve the identification of ICNs across datasets.
It should be noted that compared to previous similar attempts to obtain ICN templates (Du et al., 2020), our work uses a much larger sample size, obtains ICNs across multiple spatial scales, provides more reliable and replicable ICNs, and does not restrict to typical control cohorts. We chose to use all data available to us (including clinical cohorts) to ensure the obtained ICN template reflects the diversity and heterogeneity of the brain and can be broadly representative of different groups.
1.3.2. Group‐informed network estimation techniques to estimate subject‐specific ICNs
While the first part of this framework aims to leverage a universal template that can best represent all individuals, estimating subject‐specific networks through group‐informed techniques is crucial for precise ICN estimation from a given fMRI time series. As such, there is a significant effort to develop robust, reliable methods with a high level of sensitivity and specificity to accurately identify corresponding ICNs for a given sample data while capturing sample‐specific (e.g., subject‐specific) fine information (Du & Fan, 2013; Lin et al., 2010; Mejia et al., 2020). While we emphasize the necessity of developing new, more advanced methods, we leave this effort to future endeavors and use multivariate‐objective optimization ICA with reference (MOO‐ICAR) to estimate subject‐specific ICNs because it performs well in capturing subject‐specific information and removing artifacts (Du et al., 2016; Du & Fan, 2013).
In addition, accurately estimating subject‐specific ICNs involves various factors, as highlighted in Box 1. Applying group‐informed approaches to a dataset does not ensure the successful identification of corresponding ICNs. Thus, there is a significant need to evaluate factors influencing sample‐specific estimates and provide tools to evaluate the estimated ICNs. Our study takes the first step in this crucial research area.
BOX 1. Factors affecting the accurate estimation of subject‐specific intrinsic connectivity networks.
Several factors play roles in estimating corresponding intrinsic connectivity networks (ICNs) at the subject level, including fMRI data characteristics, ICNs themselves, and group‐informed network estimation techniques. The data characteristics, such as the amount (i.e., number of time points) of subject‐level data and spatial as well as the temporal resolutions of data, define the limits of ICNs estimation. In other words, a given ICN cannot be estimated if enough information is not present in the data, regardless of group‐informed network estimation techniques. The properties of each ICN (e.g., its spatial distribution, the amount of data variance it explains, and how densely its main cores are temporally coupled) determine how easily they can be extracted. In other words, the spatial and temporal information required to identify each ICN varies. Some ICNs can be estimated using fewer time points and coarse spatial and temporal data, while others may require fine‐grained spatial and temporal information. Together, these factors highlight that merely using an ICN template and a group‐informed network estimation technique does not guarantee proper estimation of subject‐level ICNs, and therefore underscores the need for criteria to evaluate the success of the ICN estimations.
1.4. On smoothing and reliability analysis
Spatial smoothness induced by sample size is an understudied research area. For instance, the group ICA results, similar to averaging and any group‐level analysis, are smoother than the single‐subject ICA results, as sample‐specific spatial variation is gradually smoothed out as more data are included. This phenomenon can also be observed when calculating the functional connectivity map of a given seed and averaging it across individuals. This smoothing effect can also be seen when increasing the sample size (number of time points in this case) for estimating the subject‐level functional connectivity (FC) patterns. The more time points that are included, the smoother the FC patterns/ICNs become.
This smoothness associated with data length directly impacts the results of downstream assessments (e.g., reliability assessment) that use spatial similarity to evaluate a system's performance, since more spatially smoothed estimations in general result in higher spatial similarity. Therefore, the impact of this smoothing effect should be factored in for reliability analyses and similarity evaluations, especially when comparing results from data with different data lengths. Otherwise, the results are always biased toward longer data lengths and therefore support the notion of using longer data lengths. A fair comparison between the results of different data lengths may need to control for the induced spatial smoothness due to this averaging effect. One straightforward solution is to match the smoothness of ICNs across different data lengths, for instance, by applying different levels of spatial smoothing for different data lengths to achieve a similar level of overall smoothing across data lengths.
At the same time, one should take caution about the extent to which the spatial variations are driven by sample variability and error of estimation, or to what extent they reflect a true underlying pattern. While higher spatial similarity among a given ICN estimate (such as similarity to its reference and its within‐subject and between‐subject similarity) is an appealing feature for many analyses, for example, when using spatial similarity as reliability or replicability criteria, it could potentially come at the cost of reducing subject differences, fine spatial information, and dynamic properties. Thus, applying spatial smoothing (to match smoothness across analyses) in studies could also include an assessment of its impact not only on reliability and replicability analysis but also its impact on other analyses such as prediction and association.
2. MATERIALS AND METHODS
2.1. Datasets and data preparation
2.1.1. Dataset
We utilized rsfMRI data from 100,517 subjects available in more than 20 private and public datasets. The full list of datasets and resources for obtaining further details on each can be found in Supporting Information S1. Datasets are from cohorts with different male‐to‐female ratios, age distributions, handedness, and diagnoses, collected by different scanners with varying imaging protocols such as different spatial and temporal resolutions. In this initial work, we leveraged as much data as possible to identify an ICN template, and the influence of various demographic factors will be evaluated in future studies, given the demographic distribution availability. Here, we focused on data quality control (QC) criteria to screen and select data without further exclusion criteria. The QC criteria include (a) a minimum of 120 time points (volumes) in the rsfMRI time series, (b) mean framewise displacement less than 0.25, (c) head motion transition less than 3° rotation and 3 mm translation in any direction, (d) high‐quality registration to an echo‐planar imaging template, and (e) whole‐brain (and the top 10 and the bottom 10 slices) spatial overlap between the individual mask and group mask above 80%. We chose these QC criteria as they are both reasonable and achievable across different datasets. This resulted in 57,709 (57.4%) individuals who passed the QC criteria, which we called the QC‐passed dataset, in contrast to the QC‐failed dataset defining the remaining 42,808 (42.6%) individuals who did not pass the QC criteria. We used the QC‐passed dataset to extract the ICN template and evaluated the replicability and presence of selected ICNs by separately analyzing the QC‐failed dataset.
2.1.2. Preprocessing
If the preprocessed data were available for a given dataset, we used the preprocessed data; otherwise, we performed preprocessing steps, including rigid body motion correction, slice timing correction, and distortion correction, using a combination of FMRIB Software Library (FSL v6.0, https://fsl.fmrib.ox.ac.uk/fsl/fslwiki/) and the statistical parametric mapping (SPM12, http://www.fil.ion.ucl.ac.uk/spm/) toolboxes under the MATLAB environment. Distortion correction, to adjust for warps due to susceptibility‐induced distortions based on multiple scans collected with slightly different acquisition parameters, was performed using the top‐up toolbox in FSL with the default parameters. In terms of the correction of physiological noise and motion effects, we did not apply any voxel‐level regression‐based correction. Instead, we relied on the inherent capability of ICA to separate out these variables as noise‐related components (Du et al., 2016; Griffanti et al., 2017). Next, preprocessed subject data were warped into a Montreal Neurological Institute (MNI) space using an echo‐planar imaging (EPI) template, as it has been shown to outperform structural templates (Calhoun et al., 2017) when distortion correction is unavailable or unfeasible, as was the case for this study. Finally, subject data were resampled to 3 mm3 isotropic voxels and spatially smoothed using a Gaussian kernel with a 6 mm full width at half‐maximum (FWHM).
2.2. ICNs template estimation
The analysis pipeline is displayed in Figure 1. Using our QC‐passed dataset, we applied group‐level multi‐model‐order spatial ICA (gr‐msICA; see Section 2.2.1.) to obtain a multi‐model‐order ICN template. For this purpose, we first randomly half‐split the QC‐passed data and applied gr‐msICA on each half independently. We used model orders of 25, 50, 75, 100, 125, 150, 175, and 200, totaling 900 independent components (ICs) for each data split. We repeated this process 50 times, generating 100 sets of 900 ICs. Next, we applied a greedy search and selected the 900 ICs with the highest average pairwise spatial similarity (calculated by Pearson correlation) across 100 sets. After manually labeling the ICs, we selected 105 ICNs that were most distinct from each other (spatial similarity <0.8) to serve as the final ICN template (see Section 2.2.2).
FIGURE 1.
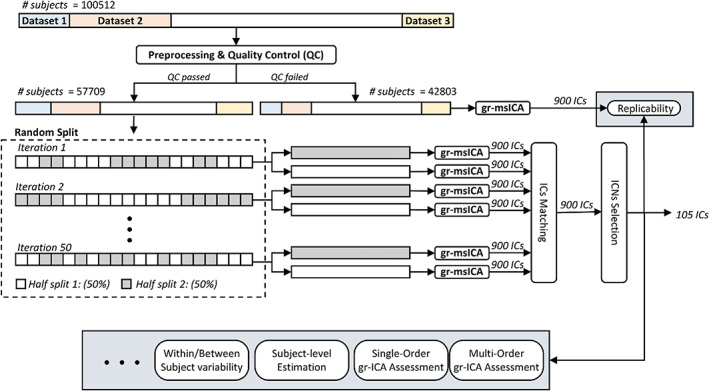
Analysis pipeline. Data of 100,512 subjects went through preprocessing and quality control (QC). In total, 57,709 subjects passed the QC and were used to generate the template. The QC‐passed dataset was randomly split in half, and group‐level multi‐spatial‐scale independent component analysis (gr‐msICA) was applied on each half‐split to generate 900 independent components (ICs). This process was repeated independently 50 times, which resulted in 100 sets of 900 ICs. Next, the 900 most stable ICs were identified and labeled as non‐ICNs or ICNs, and the 105 most distinct (spatial similarity <0.8) were selected as the ICN template. Finally, several group‐level and subject‐level analyses were performed.
2.2.1. Group‐level multi‐model‐order spatial independent component analysis
ICA analysis was performed using the Group ICA of FMRI Toolbox (GIFT) v4.0c package (https://trendscenter.org/software/gift/; Iraji et al., 2021). Spatial ICA is a multivariate blind source separation technique that simultaneously considers the relationships among all voxels (as opposed to pairwise Pearson correlations) to estimate temporally coherent spatial patterns that are maximally independent for a selected model order. The group ICA analysis steps are as follows. We first applied variance normalization (z‐score) on voxel time courses and computed subject spatial PCA to retain the PCs with maximum subject‐level variance (greater than 95%). Next, group spatial PCA was applied to stacked subject PCs to obtain subject commonalities and subspace with the maximum variation across the whole dataset. Group PCs were computed using a memory‐efficient subsampled time PCA (STP) approach (Rachakonda et al., 2016). We used STP because the conventional group spatial PCA is intractable considering the data size used in this study. STP estimates the group PC subspace by incremental updating based on a different sub‐stack of subject PCs. In other words, first‐level group PCA was applied to different subsets of subject PCs, and then the final group PC subspace was estimated by incrementally updating and incorporating first‐level group PCs (Rachakonda et al., 2016). Next, we ran gr‐msICA using the Infomax ICA algorithm (Bell & Sejnowski, 1995) with model orders of 25, 50, 75, 100, 125, 150, 175, and 200. We ran Infomax 20 times for each model order to obtain the most stable run for each model order (Du et al., 2014).
2.2.2. ICN selection
We applied msICA on 50 random half‐splits of QC‐passed data and obtained 100 sets of 900 ICs. Next, we identified the most stable ICs across the 100 runs. ICASSO is the most commonly used tool to find stable ICs and its extension for multi‐model‐order ICA applications is straightforward. However, the computational complexity of ICASSO rapidly increases with the number of ICs and ICA runs, making it impractical for our study (900 × 100 IC samples). As such, we applied a procedure that selects ICs based on the best pairwise matching of ICs between runs. The steps of the procedure are as follows. First, for each IC of each run, we found its best‐matched component from all the other 99 runs. A best‐matched component was defined as the component with maximum spatial Pearson correlation. We calculated the average of the 99 correlation values of best‐matched components as the stability coefficient for that given component. We obtained this stability coefficient for all components across all runs resulting in a 900 × 100 stability matrix. Next, we identified the component with maximum stability value across all 900 × 100 components as the first selected component, and the selected component along with its best‐matched component in each run was removed from search space (i.e., for each run, the component with maximum similarity with the selected component will be identified and omitted for the next iteration). We repeated the whole procedure for the remaining 899 × 100 components and continued this procedure until we selected 900 components along with their corresponding components across all runs. This procedure ensures all ICs across different iterations were treated equally and reduces the risk of bias toward a single IC sample. Next, four authors (V. C., Z. F., A. F., and A. I.) manually labeled the 900 selected components as ICNs or non‐ICNs. This was done based on commonly accepted ICN criteria, including (a) peak values in gray matter, (b) low spatial overlap with vascular and ventricular structures, and (c) low spatial similarity with motion and other known artifacts.
Note that some ICNs might have high spatial similarities with each other, and thus we chose a subset of ICNs (N = 105) with spatial similarity less than 0.8 as the ICN template (Supporting Information S2). All 900 components and their stability values can be found in Supporting Information S3 to allow researchers to select criteria that best match their objectives.
2.3. Subject‐level estimation of ICNs
We evaluated the identification of the corresponding subject‐specific ICNs using MOO‐ICAR (Du & Fan, 2013) and proposed two minimal criteria to systemically evaluate the successful identification of subject‐specific ICNs for a given dataset.
The first criterion evaluates whether the spatial similarity between a given ICNs template and its subject‐level estimates in a given dataset is significantly higher than the spatial similarity between the ICN's template and components estimated from null data with the same data length and level of spatial smoothing. This criterion basically determines whether an ICN is estimated significantly beyond just using predefined anatomical information determined by its template. Otherwise, the estimations reduce to using predefined spatially fixed weighted nodes/seeds (i.e., become equivalent to atlas‐based approaches). The second criterion evaluates if an estimated ICN has significantly higher spatial similarity to its own template compared to its similarity to templates from other ICNs. Data specifications (e.g., resolutions and length) and group‐informed network estimation techniques determine the ability to differentiate between ICNs (See Box 1 for more details).
We evaluated the success of estimating ICNs at subject‐level using the two introduced criteria for the Functional Imaging Biomedical Informatics Research Network (FBIRN; Keator et al., 2016) and Human Connectome Project (HCP; van Essen et al., 2013) datasets with different specifications (including inherent spatial resolution). The FBIRN dataset contains 109 subjects that passed QC with 162 time points, a repetition time (TR) of 2 s, and an original voxel size of 3.4375 × 3.4375 × 4 mm3. The HCP dataset consists of 706 subjects that passed QC and have four complete rsfMRI scan sessions. Each session has 1200 time points, a TR = 0.72 s, and an original voxel size of 2.0 mm isotropic. We also investigated ICN estimation in the context of (a) similarity to template ICNs, (b) within‐subject similarity, and (c) between‐subject similarity for different data lengths and sampling rates. We focused on the HCP dataset for data length and temporal resolution assessments. We discarded the first 50 time points and partitioned the data from each session into incrementally longer segments, beginning at 25 time points with an increment of 25 time points (i.e., 25, 50, 75, …, 1150). We performed this process for data with different temporal resolutions of 1–5 TR (0.72, 1.44, …, 3.6 s). We applied MOO‐ICAR separately to each data length and temporal resolution to estimate the corresponding 105 ICNs.
We also conducted some baseline analyses to demonstrate the general impact of spatial smoothing on subject‐level ICN evaluations and left a rigorous analysis of the effects of spatial smoothing equalization across different data lengths for future studies. For this purpose, we applied post hoc smoothing using a Gaussian kernel with a fixed FWHM to the subject‐level ICNs estimated across all data lengths, that is, the same level of smoothing (FWHM = 4.9 mm) was applied to all ICNs, regardless of the data length used for estimation. The FWHM value was selected as the value that gave the highest average spatial similarity to the template ICNs across all data lengths in independent external data. We evaluated how smoothing affects the results of our analyses, such as the similarity between subject‐level ICNs and their template, as well as both within‐subject and between‐subject similarities.
3. RESULTS
3.1. Reliable ICNs template
Figure 2a displays the composite views of the 105 selected ICNs and their average functional connectivity. Supporting Information S4 contains the axial view of each ICN. The stability coefficient (average spatial similarity across runs) for all ICNs is well above 0.8. Figure 2b shows the spatial similarity between ICNs and best‐matched components across 100 runs of gr‐msICA on 50% of the QC‐passed dataset. We additionally ran gr‐msICA on the QC‐failed dataset, which was not used in ICNs estimation (unseen dataset), and successfully (spatial similarity >0.8) identified all 105 ICNs.
FIGURE 2.
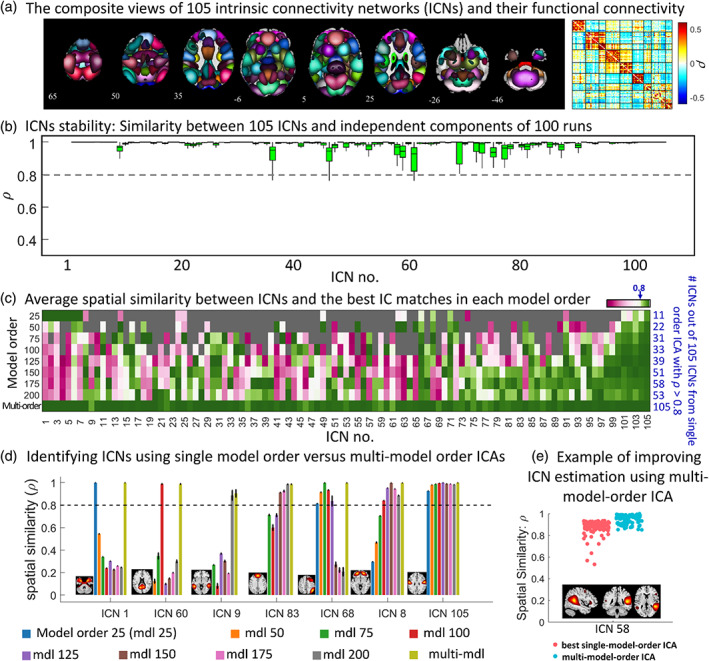
Group‐level multi‐spatial‐scale independent component analysis (gr‐msICA) results. (a) The composite views of the 105 selected intrinsic connectivity networks (ICNs) and averaged whole‐brain functional connectivity. Each ICN spatial map was first z‐scored and thresholded at z‐value = 1.96 (p‐value = .05). Whole brain functional connectivity was estimated by calculating the Pearson correlation between each pair of ICNs and averaged across the QC‐passed dataset. (b) Multi‐model order stability. The spatial similarity of ICNs with corresponding independent components (IC) across 100 gr‐msICA runs on different halves of the QC‐passed dataset. (c) single‐model‐order versus multi‐model‐order ICA. The average spatial similarity is computed between each ICN and the best IC matches across the 100 runs in each model order (and multi‐model‐order). The blue values on the right side indicate the number of ICNs identified by each model order using the similarity threshold of 0.8 (similar to stability coefficient = 0.8). (d) Different ICNs can be identified using different ranges of model orders. For example, ICN 105 was successfully identified by all model orders used in this study. (e) an example showing how using msICA improves the identification of the best corresponding ICN across different subsets of data, suggesting msICA improves the identification of ICNs across datasets.
Our results suggest that leveraging the msICA framework can improve ICN identification. Figure 2c shows the average spatial similarity between each ICN and the best IC matches across 100 runs in each model order as well as the number of ICNs identified by each model order using the similarity threshold of 0.8 (similar to stability coefficient = 0.8). This analysis shows that (1) no single model order ICA can estimate all of the 105 ICNs [e.g., only 11 out of 105 ICNs were identified using model order 25 and only about half (58) of the ICNs were identified using model order 175]; therefore, msICA provides a more complete view of brain functional patterns and (2) the ICNs represent different patterns across the various ICA model orders, meaning each can be identified from a different range of model orders. Examples of these differences can also be seen in Figure 2d. For example, ICN 105 was successfully identified across all model orders, while ICNs 1, 9, and 60 were only identified in one model order. We also observed that some ICNs were successfully identified (ρ ≥ 0.8) across multiple model orders, with one model order exhibiting the highest stability value (e.g., ICN 8 and 68).
Figure 2e provides an example of a single ICN where the best‐matched components across runs (which contain different data) come from different model orders. In this example, we can obtain ICN 58 using a single‐model‐order ICA with a stability coefficient above 0.8; however, because the best‐matched components can come from different model orders, we achieved higher stability and improved the identification of ICNs across datasets by leveraging multi‐model‐order ICA, which is the second above‐mentioned advantage of multi‐model‐order ICA. Our analysis shows that 28 of the 105 ICNs came from different model orders (2–4 different model orders) across 100 half‐split runs. In addition, we examined this advantage of multi‐model‐order ICA in the QC‐failed dataset. Our analysis revealed that 53 ICNs were identified using different model orders than those ICNs found in all QC‐passed runs.
3.2. Subject‐level analysis
The subject‐level analysis suggests that we can identify subject‐specific ICNs corresponding to our template using existing data acquisition paradigms and back‐reconstruction methods. MOO‐ICAR estimated all ICNs above null for all HCP data lengths (i.e., 25, 50, 75, …, 1150 time points); however, it could not effectively extract ICN‐specific information for 6, 5, and 2 ICNs for the shortest data lengths of 25, 50, and 75 time points, respectively, meaning the MOO‐ICAR solutions for these ICNs were not statistically (p‐value > .05) more spatially similar to their templates compared to that of other templates.
Indeed, the results of subject‐level estimations can vary based on both back‐reconstruction and data characteristics. For instance, for the FBIRN dataset with 157 time points and a larger original voxel size of 3.4375 × 3.4375 × 4 mm (i.e., higher inherent spatial smoothness), MOO‐ICAR estimation of 12 ICNs did not show statistically higher similarity to their reference than other references. In comparison, for the HCP dataset with data length equal to or larger than 100 time points, MOO‐ICAR successfully estimated all 105 ICNs.
In Figure 3a, the top row shows an example of subject‐level ICN estimation from both the HCP and FBIRN datasets. Subject‐specific estimations have less spatial smoothness than the ICN template obtained from the group‐level analysis. Subject‐specific smoothness gradually increases as more time points are used for MOO‐ICAR estimations (Figure 3b). In other words, we illustrated the expected increase phenomena (see Section 1.4) in spatial smoothness (computed as one minus average gradient magnitude across the whole brain) as a function of data length for an exemplar ICN. We also employed the post hoc subject‐level spatial smoothing (see Section 1.4) and observed that this smoothing indeed increased the similarity between subject‐level ICNs and templates obtained from group‐level analysis (the bottom row of Figure 3a provides a visual illustration).
FIGURE 3.
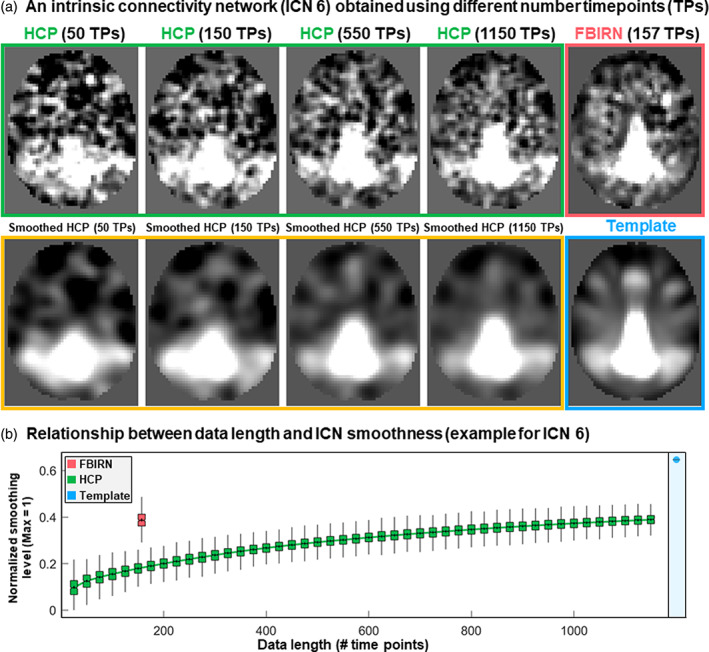
Subject‐level estimation and the effect of smoothness. (a) Estimation of intrinsic connectivity network 6 (ICN 6) for a single subject from the Human Connectome Project (HCP) dataset using different data lengths and one subject from the Functional Imaging Biomedical Informatics Research Network (FBIRN). The subject‐level estimation is less smooth than the template obtained using group‐level analysis. The subject‐level estimate depends on several factors, including data characteristics such as length of data and original voxel size. (b) The smoothness of ICN 6 estimated as a function of data lengths for the HCP dataset is shown in green. The red color represents the same measure for the FBIRN dataset with 157 time points. Blue shows the smoothness level for the template of ICN 6. Y‐axis shows the normalized smoothness level with a maximum value of 1, which corresponds to a constant image (when all voxels have the same value, the normalized smoothness level is equal to one). Normalized smoothness equals one minus average gradient magnitude across the whole brain.
The results of the spatial similarity analysis between the subject‐specific ICNs and the template are summarized in Figure 4. The left column shows the results for the original ICN estimations, and the right column represents assessments after applying the post hoc spatial smoothing (i.e., applying the same spatial smoothing with FWHM = 4.9 mm to all ICNs and data lengths). The first row (Figure 4a) shows the average similarity of 105 ICNs with the template, where the green shaded area represents its standard deviations across individuals, and Figure 4b shows an example of the spatial similarity for ICN 38. The pattern of spatial similarity with the template varies across ICNs. Figure 4c shows differences in the similarity of selected ICNs with the template, indicating different ICNs need different data lengths (i.e., numbers of samples) to achieve a specific spatial similarity to the template and spatial smoothing increases the similarity across all ICNs.
FIGURE 4.
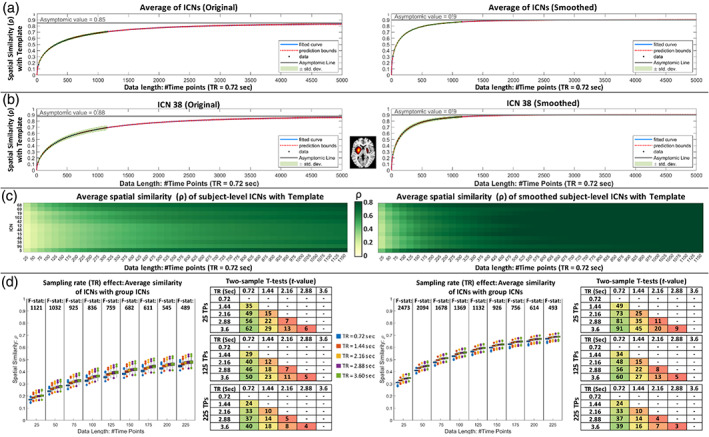
Assessment of subject‐level intrinsic connectivity networks (ICNs) estimated using multivariate‐objective optimization ICA with reference (MOO‐ICAR). The left and right columns are the results of original ICNs estimations and after applying post hoc spatial smoothing. (a) The average spatial similarity between subject‐level estimations and the template using different data lengths (from 25 to 1150 time points). The green shaded area represents its standard deviations, and the blue and red dot lines represent the fitted curve and its extrapolation. (b) The same plot as (a) but for one ICN as an example. (c) While the spatial similarity between single‐subject estimations and templates increases as the length of data increases, different ICNs show different patterns. Here, we show an average similarity as a function of time for a few randomly selected ICNs with and without spatial smoothing. (d) The sampling rate (TR) effect on the spatial similarity between template and subject‐level estimations. A high resolution of the figure can be found in Supporting Information S5.
We also evaluated the effect of the sampling rate (Figure 4d). For the same number of time points (i.e., the same number of samples or the same data length), lower sampling rates (i.e., a longer amount of time between samples) result in slightly (but statistically significant) higher spatial similarities with the template. The effect of sampling rate is more significant in smaller data lengths. For example, the F‐statistic between data with TR = 0.72, 1.44, 2.16, and 3.6 s was 1121 for the data length of 25 time points compared to 489 for the data length of 250 time points. Furthermore, for the evaluated TR values, the two‐sample t‐test indicates that the impact of sampling rate reduces as sampling rate (TR) increases. For example, for the original estimation with 25 points, the t‐value between the sampling rates of 0.72 and 1.44 s is 35, while this value is 22 for the sampling rates of 1.44 and 2.88 s. However, the increase in spatial similarity as a function of sampling rate seems trivial, especially considering we can (1) collect more data for the same amount of time using shorter TR and (2) better assess the changes in functional patterns over time.
Within‐subject and between‐subject analyses were consistent with the results of the similarity analysis with the template. For instance, we calculated the within‐subject spatial similarity between different sessions of the HCP data and observed an increase in the within‐subject spatial similarity as a function of data length (Figure 5a). Furthermore, post hoc spatial smoothing enhanced within‐subject and between‐subject spatial similarities (Figure 5b).
FIGURE 5.
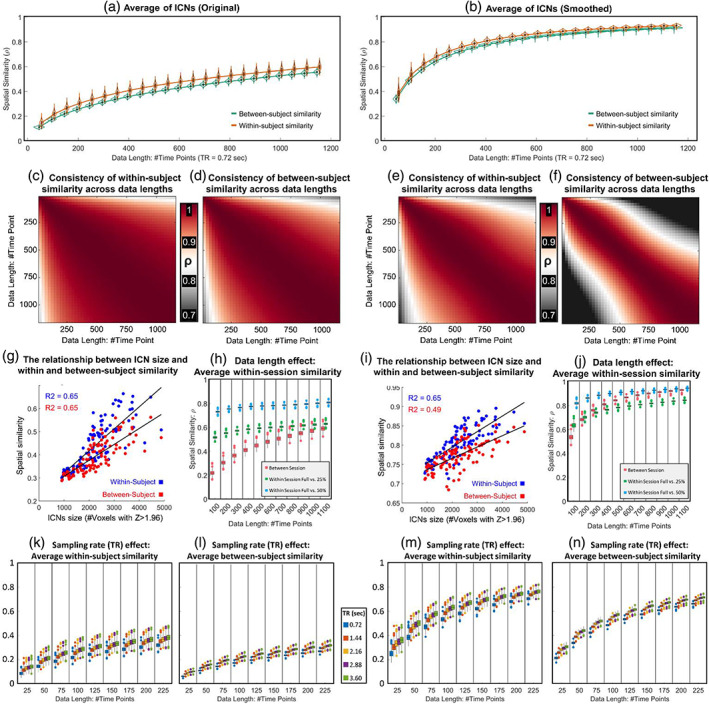
Assessment of within‐ and between‐subject similarities. The left and right columns show the results of original ICNs estimations and after applying spatial smoothing. (a, b) The average within‐ and between‐subject spatial similarity using different data lengths (from 25 to 1150 time points). Panels (c) and (e) show the similarity of the ICNs' within‐subject spatial similarity across different data lengths for original and post hoc smoothed ICNs. Panels (d) and (f) show similar results for between‐subject spatial similarity. These results suggest that while within‐ and between‐subject similarity is positively correlated with the data lengths (i.e., higher similarity with longer data lengths), the pattern of similarity across ICNs is consistent for different data lengths. Panels (g) and (I) show a strong positive correlation between ICNs size and within‐ as well as between‐subject similarity. Panels (h) and (j) show the impact of data length on the similarity of ICNs obtained using full data lengths with those obtained using a portion (25% or 50%) of data. While the within‐session similarity increases as a function of data length, this increase is not substantial, particularly compared to between‐session similarity. Panels (k)–(n) demonstrate the impact of sampling rate on within‐ and between‐subject similarities for original analysis as well as post hoc smoothed ICNs. A high resolution of the figure can be found in Supporting Information S6.
While increasing data length increases within‐ and between‐subject spatial similarities, this pattern of within‐ (and between‐) subject similarity across ICNs remains fairly consistent across data lengths, with a higher consistency for within‐subject analysis. In Figure 5c, we calculated the average within‐subject spatial similarity for all 105 ICNs at each data length. Then, we measured the Pearson correlation between 105 similarity values for each pair of data lengths. Figure 5d shows the same analysis for between‐subject analysis, and Figure 5e,f illustrates the same analyses for post hoc spatially smoothed data. We also observed that within‐ and between‐subject similarities are positively correlated with the size of ICNs, meaning within‐ and between‐subject similarities seem to be higher for larger‐scale ICNs than spatially more granular ICNs. Figure 5g,i illustrate the relationship between the number of voxels with Z > 1.96 (p‐value < .05) and within‐ and between‐subject spatial similarities.
We also evaluated the impact of data lengths and smoothing in within‐session similarities relative to between‐session similarities (Figure 5h,j). For this purpose, we calculated the spatial similarity of the ICNs estimated using the given data length with those estimated using a portion (25% and 50%) of that data length. For example, for the data length of 100 time points, we calculated the similarity between ICNs estimated using 100 time points with ones estimated using the initial 25 and 50 time points. Within‐session similarities are more similar across data lengths, compared to between‐session analysis, particularly for original estimations (Figure 5h). For instance, the Pearson correlation between full‐length and 50% remains around 0.8 across different data lengths. Moreover, post hoc spatial smoothing has a larger impact on between‐session similarities than within‐session similarities. Our analysis shows the increase in spatial similarity as the result of spatial smoothing is more prominent in between‐session similarities compared to within‐session similarities.
The effect of the sampling rate within and between‐subject similarity (Figure 5k–n) is also similar to what we observed in the context of similarity to the template. For the same number of samples, lower sampling rates (i.e., a longer amount of time between samples) result in overall higher within‐ and between‐subject spatial similarities. However, the ability to collect more data for the same amount of time favors using higher sampling rates.
For the last analysis, we evaluated subject‐specificity by comparing within‐ and between‐subject similarities through pairwise statistics, where a higher value of t‐statistic indicates higher subject‐specificity (i.e., large within‐subject similarity compared to between‐subject similarity). The within‐subject similarity was obtained by calculating the spatial similarity between estimates of each subject across different sessions. We observed that ICNs show different patterns and levels of subject specificity. For example, Figure 6a shows a few ICNs with different maximum t values and different relationships between data length and ICN's subject specificity power. The maximum t‐value is an indication of a given ICNs ability to differentiate between individuals, and we observed, for example, that this value is much higher for ICN 68 (commonly known to belong to the frontoparietal domain) than ICN 5, which is a large‐scale ICN in the cerebellum. Moreover, the t‐value of within‐ and between‐subject similarity gradually increases as a function of data length for ICN 68 in explored data length, while the value reaches the maximum in mid‐range data lengths for ICN 5. Figure 6b shows that the pattern of ICNs' subject‐specificity remains fairly similar across different data lengths, particularly when the data length is above 500 time points. Subject‐specificity is positively correlated with the ICN spatial extent for all data lengths (minimum–maximum = 0.59–0.7; average ± SD = 0.68 ± 0.02). This means larger scale ICNs estimated using MOO‐ICAR carry more subject‐specificity power relative to spatially finer scale ICNs. Figure 6c shows the average result across different data lengths. Further investigation shows that subject‐specificity variability was nonuniformly distributed across systems. ICNs associated with frontoparietal and default mode show higher within‐versus‐between subject t values, while ICNs associated with the subcortical and cerebellum have the lowest subject‐specificity power, and this pattern is similar for the original as well as post hoc smoothing (Figure 6d).
FIGURE 6.
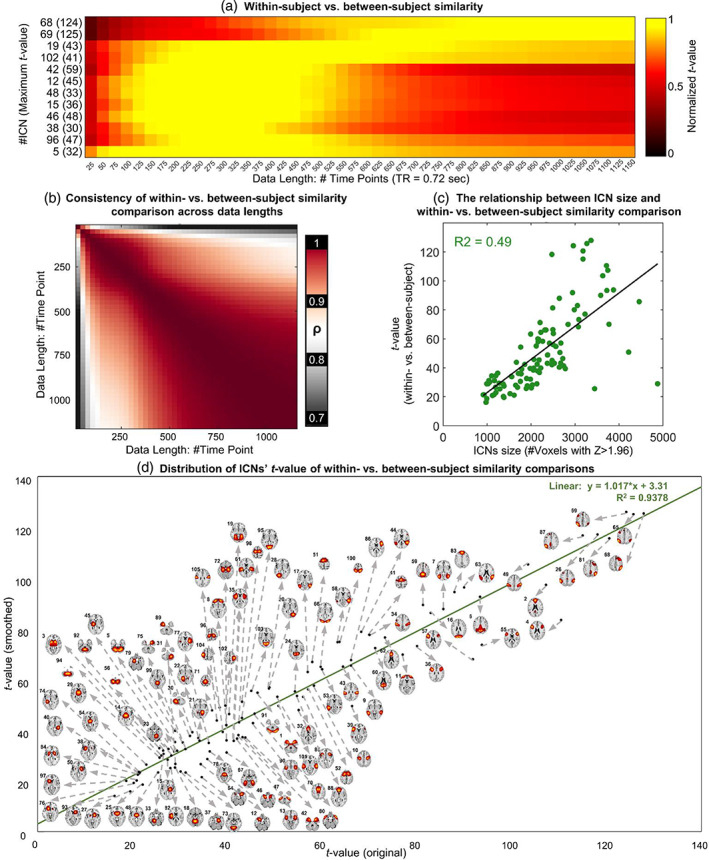
Within‐subject versus between‐subject comparison. Panel (a) shows examples of this comparison for selected ICNs and different data lengths. Panel (b) illustrates similarity in ICNs' t values across different data lengths. (c) The relationship between the t‐value of within‐ versus between‐subject comparison and the size of the ICNs. Panel (d) demonstrates that the subject‐specificity pattern is similar for original estimations and smoothed ones and the distribution of ICNs' subject‐specificity power.
4. DISCUSSION
rsfMRI is a noninvasive brain imaging method with arguably the best existing spatial and temporal resolution trade‐off and minimal demand from individuals during data acquisition. These properties make rsfMRI a promising tool for studying brain function and for use in clinical applications. Among different features acquired from rsfMRI, functional connectivity, which assesses the interactions across the brain, has shown associations with various mental and cognitive measures, as well as characteristic alterations in certain brain disorders. However, the limitations of existing methods and datasets prevent us from fully leveraging the potential of rsfMRI to study FC and transition it into a well‐established, valid clinical tool.
A key step toward establishing rsfMRI as a prevalent clinical tool is the accurate estimation of corresponding functional patterns, that is, the identification of equivalent functional patterns across individuals and brain states in a way that captures both individual variations and inter‐subject correspondence. Accumulating evidence of spatial differences in functional patterns across individuals and even within individuals over time (Bhinge et al., 2019; Boukhdhir et al., 2021; Fan et al., 2021; Iraji, Deramus, et al., 2019; Iraji, Fu, et al., 2019; Iraji et al., 2020; Luo et al., 2021; Salehi et al., 2020; Wu et al., 2021) highlights the necessity of using data‐driven approaches instead of predefined (anatomical or functional) atlases in FC studies. However, several factors must be taken into account when using data‐driven approaches. First, the calculation of functional patterns for each subject should preferably be estimated independently from other subjects, particularly in the case of prediction and machine learning, which require the training and testing data to be completely separate. Data‐driven approaches that separately estimate functional patterns for each subject and then use a data‐driven matching technique to find the correspondence fail to adequately satisfy this criterion because the matching step requires comparing the functional patterns across all data (training and testing) and therefore results in data leakage. Second, differences in datasets across studies can influence results. For example, changes in datasets used in a study (e.g., adding new subject data) can impact the matching steps (and dataset‐specific group‐level estimates) and lead to different results. Furthermore, we often do not have access to all data used in previous studies, and even if we do, rerunning analyses by adding new data to the previous ones each time is impractical and can lead to different solutions. To address the abovementioned complications, a straightforward and practical solution is to use reliable templates and group‐informed data‐driven techniques to obtain corresponding functional patterns for each individual separately.
Here, we contribute to the solution above by identifying reliable group‐level multi‐spatial‐scale ICNs (as an estimation of a universal template) using data from over 100k subjects and gr‐msICA. We used ICA to obtain our templates because of several key factors. First, ICA is a widely used multivariate tool that divides the brain into temporally coherent patterns, known as ICNs, which are potentially spatially overlapping, yet functionally distinct patterns (Calhoun & Adali, 2012; Calhoun & de Lacy, 2017; Iraji et al., 2022), and therefore good estimates of intrinsic functional “sources” or entities (Iraji et al., 2020, 2022). Another appealing attribute of ICA is its ability to separate artifactual signals from ICNs in the mixed rsfMRI time series (Calhoun & de Lacy, 2017). As such, FNC estimations (both intra‐ and inter‐network FC) have been shown to be more robust to artifacts and less contaminated with erroneous signals compared to other FC measurements (Calhoun & de Lacy, 2017). Furthermore, an ICN's spatial map has a value at every voxel, indicating the contribution of each voxel to the ICN. Therefore, instead of splitting the brain into separate parcels, ICA appreciates the brain's functional heterogeneity and multifunctionality (Calhoun et al., 2009; Haak & Beckmann, 2020; Iraji et al., 2020). Another major advantage of ICA is its ability to capture ICNs across multiple spatial scales without imposing a hard constraint on the spatial extent of ICNs (Iraji et al., 2022). This is an important attribute because the spatial scale of functional systems in the brain does not necessarily change at the same rate. We used gr‐msICA (Iraji et al., 2022; Meng et al., 2021) to estimate ICNs across multiple spatial scales and to obtain a more complete view of brain function. Supporting Information S7 and S8 contain corresponding ICNs can be obtained from single low and high model orders (25 and 175) for those interested in using single‐scale analysis at only large spatial scale or fine‐grained one. It is also worth mentioning that the ICNs can be used to estimate a comprehensive subject‐specific (and group‐level; Joliot et al., 2015) canonical parcellation/atlas.
Previous studies argued the ability of group‐level ICA analysis to identify the same ICNs in new data is challenging and can impact its replicability, particularly when the datasets are independent and have different characteristics (Du et al., 2020). Our findings suggest that gr‐msICA can significantly improve the stability of ICA results and the identification of corresponding ICNs across datasets. Our results support the explanation in Section 1.3.1 that different datasets may require varying optimal model orders for a given ICN. Specifically, we found that 28 of the 105 ICNs had best‐matched components from different model orders across 100 half‐split subsets of the QC‐passed dataset. Additionally, our analysis of the hold‐out QC‐failed dataset, which had different characteristics, revealed that all 105 ICNs were successfully identified, with 53 ICNs obtained from different model orders than those found in all QC‐passed runs.
It should be noted that although our results demonstrate that ICNs can be identified across various ranges of ICA model orders (as depicted in examples shown in Figure 2d), we believe that all ICNs would appear across multiple model orders, with one model order exhibiting the highest stability value (similar to ICN 8 and 68) if we had utilized a larger range of model orders with smaller intervals (e.g., model order 2–500 with an incremental step of 1). Using more granular model order increments and including higher ICA model orders (Iraji, Faghiri, et al., 2019; Smith et al., 2013) is also advantageous to improve the reliability of ICN estimates and obtaining a more complete set of reliable ICNs across a broader range of spatial scales. However, due to computational limitations and the large number of ICA runs in our stability analysis pipeline, we only utilize a limited number of model orders with a step size of 25 (i.e., 25, 50, 75, 100, 125, 150, 175, and 200), so we only leverage this advantage of the multi‐model‐order framework as far as computational feasibility allows.
A prior study used 1005 and 823 control individuals from the HCP and the Genomics Superstruct Project (GSP) datasets and group‐level spatial ICA to obtain a template (Du et al., 2020). Our work is different and improves this initial template in several key aspects. In this study, we used a much larger dataset (over 57k individuals after quality control) from various demographics (not just controls) to extract our ICN template; as such, it provides a closer estimation of a global template. Another major difference is that, rather than using a single model order of 100, here we leverage gr‐msICA to improve the consistency of estimated ICNs and to obtain a more comprehensive template of ICNs across multiple spatial scales. Moreover, we use a much higher spatial correlation value as the threshold (0.8 vs. 0.4) for the reproducibility and stability of ICNs. If we were to use a threshold of 0.8, the data from Du et al. template shows only 16 replicable ICNs. In contrast, all 105 ICNs of our template have spatial similarity above 0.8 with an unseen independent QC‐failed dataset. The successful identification of ICNs in the QC‐failed dataset may indicate that less stringent quality control criteria can be employed compared to the prevailing practice in the field. This would allow for the utilization of more data, resulting in an increase in sample size and potentially uncovering more subtle effects or relationships. This can lead to more robust and meaningful conclusions. However, to make any recommendations or draw conclusions, further evaluations, particularly subject‐level analysis of those with lower data quality, are needed.
We also evaluated the presence of the Du et al. ICNs in our selected ICs. For the threshold of 0.4, we found correspondence for all 53 template ICNs among 900 ICs. However, only 45 out of 53 ICNs for Du et al., show spatial similarity above 0.4 with our 105 template ICNs; in other words, some of the ICNs in the initial template did not meet our criteria of being an ICN.
Focusing on sample‐specific (e.g., subject‐specific) estimation, we used group‐informed network estimation techniques where our template was used to guide subject‐specific solutions. We recommend using group‐informed network estimation techniques combined with our template for several reasons. First, group‐informed techniques more accurately estimate subject‐specific patterns, particularly for low SNR rsfMRI data with short data lengths, because the templates are utilized as a constraint to limit the search space. A recent study (Duda et al., 2023) suggests that this pipeline could potentially shorten clinical rsfMRI scans to just 2–4 min without significant loss in static group comparison. Group‐informed techniques also enhance the estimation of subject‐specific correspondence by optimizing the solution to be jointly spatially independent and close to a common template. In addition, these techniques only use the template and subject data itself to estimate subject‐specific ICNs, and therefore the estimation of each individual is independent of other samples in a given study. Using our template as a universal reference also facilitates the comparison of findings across existing and future studies as we retain the correspondence ICNs across all subjects that the pipeline is applied.
The first step toward using any subject‐level estimates is to evaluate whether or not network‐estimation and parcellation techniques successfully estimate subject‐level patterns for a given dataset. This has been mainly overlooked in previous studies. Here, we introduced two criteria for this purpose which assess whether the subject‐level estimates of each ICN in a given dataset provide (1) subject‐specific information beyond predefined spatially fixed nodes (weighted masks) and (2) unique information about the associated ICN compared to other ICNs. The second criterion is important for highly similar ICNs and evaluating if we can differentiate between them in subject‐level estimation in a given dataset. In this work, we assessed the ability of the existing MOO‐ICAR framework to obtain the subject‐level estimation of our template. But these two criteria can be used to evaluate other network‐estimation and parcellation techniques, and we also call for further investigation on this understudied but important area.
We also evaluated the role of different parameters in estimating subject‐level ICNs. The results show that in addition to the data length, which has been the center of many reliability investigations (Birn et al., 2013; Duda et al., 2023; Gordon, Laumann, et al., 2017; Murphy et al., 2007), other data characteristics (particularly inherent spatial resolution) play key roles in successfully extracting subject‐level ICNs. For instance, MOO‐ICAR successfully estimated all 105 ICNs using 100 time points for the HCP dataset; however, 12 ICNs did not survive the second criterion for the FBIRN dataset, even using 157 time points. This might suggest the spatial resolution of data is an important factor in differentiating these highly spatially similar ICNs. These highly spatially similar ICNs (Supporting Information S9) that we observed at the group‐level analysis resemble the previously reported parallel interdigitated distributed networks observed at the subject level (Braga & Buckner, 2017).
In addition to data characteristics, the intrinsic properties of a given ICN are an important factor in calculating subject‐level estimates. In general, larger ICNs require less data to achieve a specific level of within‐subject (between‐subject and template) spatial similarity. Given that spatial similarity is commonly used as a reliability index, we could postulate large‐scale ICNs are more stable and require less data to be estimated reliably at the subject level. This result agrees with previous findings showing that lower model‐order ICA generates more consistent components than the higher model orders. Our findings also indicate that ICNs carry different levels of subject fingerprint information, with ICNs associated with the subcortical domain having the least subject‐specific information and those suggested to be involved in higher cognitive functions, particularly ICNs associated with frontoparietal domains showing the maximum within‐to‐between‐subject differences. A previous fingerprint study also identified the connectivity patterns of the frontoparietal network as the most distinguishing of individuals (Finn et al., 2015).
Interestingly, ICNs exhibit different patterns of within‐to‐between‐subject differences across data lengths, which can relate to the temporality aspect of functional fingerprinting (van de Ville et al., 2021), for example, the within‐to‐between‐subject difference peaks at different data lengths for different ICNs. Our analysis using the HCP dataset with TR = 0.72 s and a step size of 25 time points shows the peak varies between 125 and 875 time points (90–630 s). These findings may also imply (1) increasing data length is not always desirable even though it increases within‐subject similarity, which is commonly used in reliability analyses to support using longer data lengths (30 min and more) in analysis, (2) studies should take the length of the data into account in their analyses and interpreting the results, and (3) future work can analyze and leverage multi‐data‐length information. One related key factor that was not explored in this study is incorporating and assessing brain dynamics. The lower spatial similarity for smaller data lengths can be partially related to brain spatial dynamics and changes in the spatial patterns of ICNs over time (Iraji, Deramus, et al., 2019). These differences observed in findings across ICNs and data lengths (and probably other factors) highlight the challenge of within‐ and between‐subject variabilities in understanding brain functional organization and its changes across different conditions.
Notably, while there are observable differences in findings between data lengths, the findings across various data lengths still show a similar pattern across ICNs. For instance, while within‐subject and between‐subject similarities are different across data lengths (i.e., a systematic increase in spatial similarity as a function of data length), the pattern of spatial similarity across ICNs remains fairly similar across data lengths (e.g., Figure 5c,d), suggesting features that encode ICN properties relative to each other might be more robust to the data length and therefore possibly more generalizable indicators of brain function.
We also observe that differences in spatial smoothness across data lengths (also between datasets) can impact the results and outcome of analyses, and therefore may limit the comparison of findings across studies. We show how spatial smoothing can alter results, including improving within‐subject spatial similarity. As such, we highlight the necessity of correcting for differences in spatial smoothness, particularly those associated with data lengths, for any interpretation of results and comparing the findings across analyses. Furthermore, in addition to evaluating the impact of spatial smoothing on subject‐level estimation, it is crucial for future studies to evaluate the impact of spatial smoothing on the identification of group‐level independent components. As recent research suggests, the effect of spatial smoothing is complex, nontrivial, and difficult to predict (Triana et al., 2020).
The within‐session results (i.e., our analyses of different overlapping data within each session for different data lengths) may indicate that the lower spatial similarity in smaller data lengths may not be solely related to lower reliability in estimation but also associated with the dynamic nature of brain function. We observed that the within‐session similarity between ICNs estimated using the full‐length of data and subset of it (e.g., 50% and 25% data lengths) remains fairly similar for different full‐lengths of data (cf. blue and green curves are relatively flat in Figure 5h). For example, the spatial similarity between ICNs estimated using 100 time points and the first 50 time points is close to 0.8, as is the similarity between 1000 time points and the first 500 time points. We would expect a significantly lower spatial similarity between 100 and 50 time points if their ICNs estimates were unreliable compared to those from longer data lengths. We posit that the lower between‐session spatial similarity for lower data lengths might be because the two separated data carry different spatial dynamic information of ICNs, and as the data lengths increase, they are gradually getting closer to average (also known as static) estimates of ICNs, and therefore become more similar. Indeed, the larger increase in the spatial similarity of between‐session analysis relative to within‐session analysis may further support this posit.
Finally, it is important to mention that subject‐level statistics were examined on a subset of over 57k subjects used to estimate templates. While the contribution of any single subject to the obtained template is trivial given the large sample size, future studies are needed to validate our findings in an independent dataset.
5. CONCLUSION
In this work, we identified a reliable and replicable multi‐spatial‐scale ICNs template using gr‐msICA and around 58k subject data that meet the quality control criteria. The template was also replicated in data that did not pass the QC criteria. We aim to use this template to generalize and standardize functional connectivity analysis. This study builds on the recently proposed concept of Neuromark. NeuroMark is a comprehensive mapping of (unimodal or multimodal) coherent brain patterns that correspond among individuals by leveraging universal templates derived from prior data coupled with guided data‐driven approaches. Previously, NeuroMark_fMRI_1.0 template, including 53 ICNs, was obtained from two large rsfMRI datasets and single model order ICA (Du et al., 2020). Here, we augmented the previous effort by using a much larger dataset and gr‐msICA and introduced NeuroMark_fMRI_2.0 single‐ and multi‐model order templates, which are available for access at https://trendscenter.org/data/.
In addition to providing an enhanced ICN template, we also studied the feasibility of estimating the corresponding ICNs at the subject level. Previous work has demonstrated that the Neuromark framework is relatively stable across different spatial normalization pipelines (DeRamus et al., 2021). However, there is a significant gap in understanding the factors that influence the successful capture of subject‐specific information such as ICNs or functional parcellations. Here, we introduced two criteria to evaluate the successful identification of subject‐specific ICNs (or other functional parcellations) for a given dataset and a group‐informed estimation approach and studied the role of different factors in subject‐level ICN estimates. The results suggest that the intrinsic properties of the ICNs themselves, data length, and spatial resolution are some key factors in successfully estimating ICNs at the subject level. We illustrated an increase in spatial smoothness as a function of data length and the impact of spatial smoothing on findings. As such, we suggest future studies should control for the effect of spatial smoothness in their analysis to mitigate its impact on our ability to compare the findings across different studies. We also observed increasing data length can reduce an ICN's subject‐level specificity, suggesting longer scans might not always be desirable. Finally, the consistency in the spatial similarity between ICNs estimated using the full‐length of data and a subset of it across different data lengths may suggest that the lower within‐subject spatial similarity in shorter data lengths is not necessarily defined by only lower reliability in ICNs estimates and demands further investigations. Our future work will focus on incorporating the findings of this study in functional connectivity analysis and developing new group‐informed network estimation techniques to improve the estimation of corresponding subject‐specific ICNs. Future research can benefit from using higher model order ICAs and lower step sizes. Future work can explore using other multi‐model‐order ICA approaches (Du et al., 2021) and develop more advanced gr‐msICA to estimate ICNs across multiple spatial scales. We will also soon release Neuromark templates for other imaging modalities.
Supporting information
Data S1. Supporting Information.
Data S2. Supporting Information.
Data S3. Supporting Information.
Data S4. Supporting Information.
Data S5. Supporting Information.
Data S6. Supporting Information.
Data S7. Supporting Information.
Data S8. Supporting Information.
Data S9. Supporting Information.
ACKNOWLEDGMENTS
This work was supported by grants from the National Institutes of Health grant numbers 1U24RR021992, 1U24RR025736, R01EB020407, R01MH118695, R01MH123610, and R01EB006841 and the National Science Foundation grant number 2112455 to Dr. Vince D. Calhoun; the National Institutes of Health grant number R01MH117107 to Dr. Jing Sui; the National Science Foundation grant number 1631838 to Dr. Tulay Adali; and the Lawson Health Research Institute, grant number LHR D1374, Pfizer Independent Investigator Award, grant number WS2249136, and CIHR grant FRN 153359 to Dr. Elizabeth A. Osuch. We would also like to acknowledge the Georgia State University RISE Award, which significantly helped to accomplish this work. Data were provided in part by the Adolescent Brain Cognitive Development SM (ABCD) Study (Jernigan & Brown, 2018), held in the NIMH Data Archive (NDA). This is a multisite, longitudinal study designed to recruit more than 10,000 children aged 9–10 and follow them over 10 years into early adulthood. The ABCD Study® is supported by the National Institutes of Health (NIH) and additional federal partners under award numbers U01DA041048, U01DA050989, U01DA051016, U01DA041022, U01DA051018, U01DA051037, U01DA050987, U01DA041174, U01DA041106, U01DA041117, U01DA041028, U01DA041134, U01DA050988, U01DA051039, U01DA041156, U01DA041025, U01DA041120, U01DA051038, U01DA041148, U01DA041093, U01DA041089, U24DA041123, U24DA041147; by the Autism Brain Imaging Data Exchange (ABIDE) (Di Martino et al., 2014, 2017) support for the work by Adriana Di Martino provided by the (NIMH K23MH087770) and the Leon Levy Foundation and primary support for the work by Michael P. Milham and the INDI team was provided by gifts from Joseph P. Healy and the Stavros Niarchos Foundation to the Child Mind Institute, as well as by an NIMH award to MPM (NIMH R03MH096321); by the Attention Deficit Hyperactivity Disorder‐200 (ADHD200) Consortium (HD‐200 Consortium, 2012). Consortium steering committee includes Jan Buitelaar, MD, F. Xavier Castellanos, MD, PhD, Daniel Dickstein, PhD, Damien Fair, P.A.‐C., PhD, David Kennedy, PhD, Beatric Luna, PhD, Michael P. Milham (Project Coordinator), MD, PhD, Stewart Mostofsky, MD, Joel Nigg, PhD, Julie B. Schweitzer, PhD, Katerina Velanova, PhD, Yu‐Feng Wang, MD, PhD, Yu‐Feng Zang, MD; by the Alzheimer's Disease Neuroimaging Initiative (ADNI) (Jack Jr. et al., 2008) (National Institutes of Health Grant U01 AG024904) and DOD ADNI (Department of Defense award number W81XWH‐12‐2‐0012). ADNI is funded by the National Institute on Aging, the National Institute of Biomedical Imaging and Bioengineering, and through generous contributions from the following: AbbVie, Alzheimer's Association; Alzheimer's Drug Discovery Foundation; Araclon Biotech; BioClinica, Inc.; Biogen; Bristol‐Myers Squibb Company; CereSpir, Inc.; Cogstate; Eisai Inc.; Elan Pharmaceuticals, Inc.; Eli Lilly and Company; EuroImmun; F. Hoffmann‐La Roche Ltd and its affiliated company Genentech, Inc.; Fujirebio; GE Healthcare; IXICO Ltd.; Janssen Alzheimer Immunotherapy Research & Development, LLC.; Johnson & Johnson Pharmaceutical Research & Development LLC.; Lumosity; Lundbeck; Merck & Co., Inc.; Meso Scale Diagnostics, LLC.; NeuroRx Research; Neurotrack Technologies; Novartis Pharmaceuticals Corporation; Pfizer Inc.; Piramal Imaging; Servier; Takeda Pharmaceutical Company; and Transition Therapeutics. The Canadian Institutes of Health Research is providing funds to support ADNI clinical sites in Canada. Private sector contributions are facilitated by the Foundation for the National Institutes of Health. The grantee organization is the Northern California Institute for Research and Education, and the study is coordinated by the Alzheimer's Therapeutic Research Institute at the University of Southern California. ADNI data are disseminated by the Laboratory for Neuro Imaging at the University of Southern California; by the Bipolar & Schizophrenia Consortium for Parsing Intermediate Phenotypes (B‐SNIP) study (Tamminga et al., 2013); by the Brain Genomics Superstruct Project (GSP) (Holmes et al., 2015) of Harvard University and the Massachusetts General Hospital, (Principal Investigators: Randy Buckner, Joshua Roffman, and Jordan Smoller), with support from the Center for Brain Science Neuroinformatics Research Group, the Athinoula A. Martinos Center for Biomedical Imaging, and the Center for Human Genetic Research. 20 individual investigators at Harvard and MGH generously contributed data to the overall project; by the Human Connectome Project for Early Psychosis study (Lewandowski et al., 2020); the Human Connectome Project (van Essen et al., 2013), WU‐Minn Consortium (Principal Investigators: David Van Essen and Kamil Ugurbil; 1U54MH091657) funded by the 16 NIH Institutes and Centers that support the NIH Blueprint for Neuroscience Research; and by the McDonnell Center for Systems Neuroscience at Washington University; by the OASIS (LaMontagne et al., 2019) Longitudinal Multimodal Neuroimaging: Principal Investigators: T. Benzinger, D. Marcus, J. Morris; NIH P50 AG00561, P30 NS09857781, P01 AG026276, P01 AG003991, R01 AG043434, UL1 TR000448, R01 EB009352. AV‐45 doses were provided by Avid Radiopharmaceuticals, a wholly owned subsidiary of Eli Lilly; and using the UK Biobank (Littlejohns et al., 2020) Resource under Application Number 49636.
Iraji, A. , Fu, Z. , Faghiri, A. , Duda, M. , Chen, J. , Rachakonda, S. , DeRamus, T. , Kochunov, P. , Adhikari, B. M. , Belger, A. , Ford, J. M. , Mathalon, D. H. , Pearlson, G. D. , Potkin, S. G. , Preda, A. , Turner, J. A. , van Erp, T. G. M. , Bustillo, J. R. , Yang, K. , … Calhoun, V. D. (2023). Identifying canonical and replicable multi‐scale intrinsic connectivity networks in 100k+ resting‐state fMRI datasets. Human Brain Mapping, 44(17), 5729–5748. 10.1002/hbm.26472
Contributor Information
A. Iraji, Email: armin.iraji@gmail.com.
V. D. Calhoun, Email: vcalhoun@gsu.edu.
DATA AVAILABILITY STATEMENT
The full list of datasets and resources for obtaining further details on each can be found in Supporting Information S1. The links for publicly available datasets and contact information for private datasets are included in Supporting Information S1. All the code used in this study could be made available by contacting the corresponding author (A. Iraji).
REFERENCES
- Allen, E. A. , Erhardt, E. B. , Damaraju, E. , Gruner, W. , Segall, J. M. , Silva, R. F. , Havlicek, M. , Rachakonda, S. , Fries, J. , Kalyanam, R. , Michael, A. M. , Caprihan, A. , Turner, J. A. , Eichele, T. , Adelsheim, S. , Bryan, A. D. , Bustillo, J. , Clark, V. P. , Feldstein Ewing, S. W. , … Calhoun, V. D. (2011). A baseline for the multivariate comparison of resting‐state networks. Frontiers in Systems Neuroscience, 5, 2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Allen, E. A. , Erhardt, E. B. , Wei, Y. , Eichele, T. , & Calhoun, V. D. (2012). Capturing inter‐subject variability with group independent component analysis of fMRI data: A simulation study. NeuroImage, 59, 4141–4159. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bell, A. J. , & Sejnowski, T. J. (1995). An information‐maximization approach to blind separation and blind deconvolution. Neural Computation, 7, 1129–1159. [DOI] [PubMed] [Google Scholar]
- Bhinge, S. , Long, Q. , Calhoun, V. D. , & Adali, T. (2019). Spatial dynamic functional connectivity analysis identifies distinctive biomarkers in schizophrenia. Frontiers in Neuroscience, 13, 1006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Birn, R. M. , Molloy, E. K. , Patriat, R. , Parker, T. , Meier, T. B. , Kirk, G. R. , Nair, V. A. , Meyerand, M. E. , & Prabhakaran, V. (2013). The effect of scan length on the reliability of resting‐state fMRI connectivity estimates. NeuroImage, 83, 550–558. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Boukhdhir, A. , Zhang, Y. , Mignotte, M. , & Bellec, P. (2021). Unraveling reproducible dynamic states of individual brain functional parcellation. Network Neuroscience, 5, 28–55. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Braga, R. M. , & Buckner, R. L. (2017). Parallel interdigitated distributed networks within the individual estimated by intrinsic functional connectivity. Neuron, 95, 457–471.e455. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Calhoun, V. D. , & Adali, T. (2012). Multisubject independent component analysis of fMRI: A decade of intrinsic networks, default mode, and neurodiagnostic discovery. IEEE Reviews in Biomedical Engineering, 5, 60–73. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Calhoun, V. D. , Adali, T. , McGinty, V. B. , Pekar, J. J. , Watson, T. D. , & Pearlson, G. D. (2001). fMRI activation in a visual‐perception task: Network of areas detected using the general linear model and independent components analysis. NeuroImage, 14, 1080–1088. [DOI] [PubMed] [Google Scholar]
- Calhoun, V. D. , Adali, T. , Pearlson, G. D. , & Pekar, J. J. (2001). A method for making group inferences from functional MRI data using independent component analysis. Human Brain Mapping, 14, 140–151. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Calhoun, V. D. , & de Lacy, N. (2017). Ten key observations on the analysis of resting‐state functional MR imaging data using independent component analysis. Neuroimaging Clinics of North America, 27, 561–579. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Calhoun, V. D. , Kiehl, K. A. , & Pearlson, G. D. (2008). Modulation of temporally coherent brain networks estimated using ICA at rest and during cognitive tasks. Human Brain Mapping, 29, 828–838. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Calhoun, V. D. , Liu, J. , & Adali, T. (2009). A review of group ICA for fMRI data and ICA for joint inference of imaging, genetic, and ERP data. NeuroImage, 45, S163–S172. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Calhoun, V. D. , Wager, T. D. , Krishnan, A. , Rosch, K. S. , Seymour, K. E. , Nebel, M. B. , Mostofsky, S. H. , Nyalakanai, P. , & Kiehl, K. (2017). The impact of T1 versus EPI spatial normalization templates for fMRI data analyses. Human Brain Mapping, 38, 5331–5342. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Damoiseaux, J. S. , Beckmann, C. F. , Arigita, E. J. , Barkhof, F. , Scheltens, P. , Stam, C. J. , Smith, S. M. , & Rombouts, S. A. (2008). Reduced resting‐state brain activity in the “default network” in normal aging. Cerebral Cortex, 18, 1856–1864. [DOI] [PubMed] [Google Scholar]
- DeRamus, T. , Iraji, A. , Fu, Z. , Silva, R. , Stephen, J. , Wilson, T. W. , Wang, Y. P. , Du, Y. , Liu, J. , & Calhoun, V. (2021). Stability of functional network connectivity (FNC) values across multiple spatial normalization pipelines in spatially constrained independent component analysis. In Proceedings of the 2021 IEEE 21st International Conference on Bioinformatics and Bioengineering (BIBE), pp. 1–6.
- di Martino, A. , O'Connor, D. , Chen, B. , Alaerts, K. , Anderson, J. S. , Assaf, M. , Balsters, J. H. , Baxter, L. , Beggiato, A. , Bernaerts, S. , Blanken, L. M. , Bookheimer, S. Y. , Braden, B. B. , Byrge, L. , Castellanos, F. X. , Dapretto, M. , Delorme, R. , Fair, D. A. , Fishman, I. , … Milham, M. P. (2017). Enhancing studies of the connectome in autism using the autism brain imaging data exchange II. Scientific Data, 4, 170010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- di Martino, A. , Yan, C. G. , Li, Q. , Denio, E. , Castellanos, F. X. , Alaerts, K. , Anderson, J. S. , Assaf, M. , Bookheimer, S. Y. , Dapretto, M. , Deen, B. , Delmonte, S. , Dinstein, I. , Ertl‐Wagner, B. , Fair, D. A. , Gallagher, L. , Kennedy, D. P. , Keown, C. L. , Keysers, C. , … Milham, M. P. (2014). The autism brain imaging data exchange: Towards a large‐scale evaluation of the intrinsic brain architecture in autism. Molecular Psychiatry, 19, 659–667. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Du, W. , Ma, S. , Fu, G. , Calhoun, V. D. , & Adali, T. (2014). A novel approach for assessing reliability of ICA for FMRI analysis. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 2084–2088.
- Du, Y. , Allen, E. A. , He, H. , Sui, J. , Wu, L. , & Calhoun, V. D. (2016). Artifact removal in the context of group ICA: A comparison of single‐subject and group approaches. Human Brain Mapping, 37, 1005–1025. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Du, Y. , & Fan, Y. (2013). Group information guided ICA for fMRI data analysis. NeuroImage, 69, 157–197. [DOI] [PubMed] [Google Scholar]
- Du, Y. , Fu, Z. , Sui, J. , Gao, S. , Xing, Y. , Lin, D. , Salman, M. , Abrol, A. , Rahaman, M. A. , Chen, J. , Hong, L. E. , Kochunov, P. , Osuch, E. A. , & Calhoun, V. D. (2020). NeuroMark: An automated and adaptive ICA based pipeline to identify reproducible fMRI markers of brain disorders. Neuroimage Clinical, 28, 102375. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Du, Y. , He, X. , & Calhoun, V. D. (2021). SMART (splitting‐merging assisted reliable) independent component analysis for brain functional networks. In Proceedings of the 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), pp. 3263–3266. [DOI] [PubMed]
- Duda, M. , Iraji, A. , Ford, J. M. , Lim, K. O. , Mathalon, D. H. , Mueller, B. A. , Potkin, S. G. , Preda, A. , van Erp, T. G. M. , & Calhoun, V. D. (2023). Spatially constrained ICA enables robust detection of schizophrenia from very short resting‐state fMRI data. Human Brain Mapping, 44, 2620–2635. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Durieux, J. , & Wilderjans, T. F. (2019). Partitioning subjects based on high‐dimensional fMRI data: Comparison of several clustering methods and studying the influence of ICA data reduction in big data. Behaviormetrika, 46, 271–311. [Google Scholar]
- Erhardt, E. B. , Rachakonda, S. , Bedrick, E. J. , Allen, E. A. , Adali, T. , & Calhoun, V. D. (2011). Comparison of multi‐subject ICA methods for analysis of fMRI data. Human Brain Mapping, 32, 2075–2095. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Esposito, F. , Scarabino, T. , Hyvarinen, A. , Himberg, J. , Formisano, E. , Comani, S. , Tedeschi, G. , Goebel, R. , Seifritz, E. , & di Salle, F. (2005). Independent component analysis of fMRI group studies by self‐organizing clustering. NeuroImage, 25, 193–205. [DOI] [PubMed] [Google Scholar]
- Fan, L. , Zhong, Q. , Qin, J. , Li, N. , Su, J. , Zeng, L. L. , Hu, D. , & Shen, H. (2021). Brain parcellation driven by dynamic functional connectivity better capture intrinsic network dynamics. Human Brain Mapping, 42, 1416–1433. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Finn, E. S. , Shen, X. , Scheinost, D. , Rosenberg, M. D. , Huang, J. , Chun, M. M. , Papademetris, X. , & Constable, R. T. (2015). Functional connectome fingerprinting: Identifying individuals using patterns of brain connectivity. Nature Neuroscience, 18, 1664–1671. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gordon, E. M. , Laumann, T. O. , Adeyemo, B. , & Petersen, S. E. (2017). Individual variability of the system‐level organization of the human brain. Cerebral Cortex, 27, 386–399. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gordon, E. M. , Laumann, T. O. , Gilmore, A. W. , Newbold, D. J. , Greene, D. J. , Berg, J. J. , Ortega, M. , Hoyt‐Drazen, C. , Gratton, C. , Sun, H. , Hampton, J. M. , Coalson, R. S. , Nguyen, A. L. , McDermott, K. B. , Shimony, J. S. , Snyder, A. Z. , Schlaggar, B. L. , Petersen, S. E. , Nelson, S. M. , & Dosenbach, N. U. F. (2017). Precision functional mapping of individual human brains. Neuron, 95, 791–807.e797. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Griffanti, L. , Douaud, G. , Bijsterbosch, J. , Evangelisti, S. , Alfaro‐Almagro, F. , Glasser, M. F. , Duff, E. P. , Fitzgibbon, S. , Westphal, R. , Carone, D. , Beckmann, C. F. , & Smith, S. M. (2017). Hand classification of fMRI ICA noise components. NeuroImage, 154, 188–205. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Haak, K. V. , & Beckmann, C. F. (2020). Understanding brain organisation in the face of functional heterogeneity and functional multiplicity. NeuroImage, 220, 117061. [DOI] [PubMed] [Google Scholar]
- HD‐200 Consortium . (2012). The ADHD‐200 consortium: A model to advance the translational potential of neuroimaging in clinical neuroscience. Frontiers in Systems Neuroscience, 6, 62. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Holmes, A. J. , Hollinshead, M. O. , O'Keefe, T. M. , Petrov, V. I. , Fariello, G. R. , Wald, L. L. , Fischl, B. , Rosen, B. R. , Mair, R. W. , Roffman, J. L. , Smoller, J. W. , & Buckner, R. L. (2015). Brain genomics Superstruct project initial data release with structural, functional, and behavioral measures. Scientific Data, 2, 150031. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Iraji, A. , Calhoun, V. D. , Wiseman, N. M. , Davoodi‐Bojd, E. , Avanaki, M. R. N. , Haacke, E. M. , & Kou, Z. (2016). The connectivity domain: Analyzing resting state fMRI data using feature‐based data‐driven and model‐based methods. NeuroImage, 134, 494–507. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Iraji, A. , Deramus, T. P. , Lewis, N. , Yaesoubi, M. , Stephen, J. M. , Erhardt, E. , Belger, A. , Ford, J. M. , McEwen, S. , Mathalon, D. H. , Mueller, B. A. , Pearlson, G. D. , Potkin, S. G. , Preda, A. , Turner, J. A. , Vaidya, J. G. , van Erp, T. G. M. , & Calhoun, V. D. (2019). The spatial connectome reveals a dynamic interplay between functional segregation and integration. Human Brain Mapping, 40, 3058–3077. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Iraji, A. , Faghiri, A. , Fu, Z. , Rachakonda, S. , Kochunov, P. , Belger, A. , Ford, J. M. , McEwen, S. , Mathalon, D. H. , Mueller, B. A. , Pearlson, G. D. , Potkin, S. G. , Preda, A. , Turner, J. A. , van Erp, T. G. M. , & Calhoun, V. D. (2022). Multi‐spatial‐scale dynamic interactions between functional sources reveal sex‐specific changes in schizophrenia. Network Neuroscience, 6, 357–381. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Iraji, A. , Faghiri, A. , Lewis, N. , Fu, Z. , DeRamus, T. , Qi, S. , Rachakonda, S. , Du, Y. , & Calhoun, V. (2019). Ultra‐high‐order ICA: An exploration of highly resolved data‐driven representation of intrinsic connectivity networks (sparse ICNs). Wavelets and Sparsity XVIII (p. 111380I). International Society for Optics and Photonics. [Google Scholar]
- Iraji, A. , Faghiri, A. , Lewis, N. , Fu, Z. , Rachakonda, S. , & Calhoun, V. D. (2021). Tools of the trade: Estimating time‐varying connectivity patterns from fMRI data. Social Cognitive and Affective Neuroscience, 16, 849–874. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Iraji, A. , Fu, Z. , Damaraju, E. , DeRamus, T. P. , Lewis, N. , Bustillo, J. R. , Lenroot, R. K. , Belger, A. , Ford, J. M. , McEwen, S. , Mathalon, D. H. , Mueller, B. A. , Pearlson, G. D. , Potkin, S. G. , Preda, A. , Turner, J. A. , Vaidya, J. G. , van Erp, T. G. M. , & Calhoun, V. D. (2019). Spatial dynamics within and between brain functional domains: A hierarchical approach to study time‐varying brain function. Human Brain Mapping, 40, 1969–1986. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Iraji, A. , Miller, R. , Adali, T. , & Calhoun, V. D. (2020). Space: A missing piece of the dynamic puzzle. Trends in Cognitive Sciences, 24, 135–149. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jack, C. R., Jr. , Bernstein, M. A. , Fox, N. C. , Thompson, P. , Alexander, G. , Harvey, D. , Borowski, B. , Britson, P. J. , Whitwell, L. J. , Ward, C. , Dale, A. M. , Felmlee, J. P. , Gunter, J. L. , Hill, D. L. , Killiany, R. , Schuff, N. , Fox‐Bosetti, S. , Lin, C. , Studholme, C. , … Weiner, M. W. (2008). The Alzheimer's disease neuroimaging initiative (ADNI): MRI methods. Journal of Magnetic Resonance Imaging, 27, 685–691. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jernigan, T. L. , & Brown, S. A. (2018). Introduction. Developmental Cognitive Neuroscience, 32, 1–3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Joliot, M. , Jobard, G. , Naveau, M. , Delcroix, N. , Petit, L. , Zago, L. , Crivello, F. , Mellet, E. , Mazoyer, B. , & Tzourio‐Mazoyer, N. (2015). AICHA: An atlas of intrinsic connectivity of homotopic areas. Journal of Neuroscience Methods, 254, 46–59. [DOI] [PubMed] [Google Scholar]
- Keator, D. B. , van Erp, T. G. M. , Turner, J. A. , Glover, G. H. , Mueller, B. A. , Liu, T. T. , Voyvodic, J. T. , Rasmussen, J. , Calhoun, V. D. , Lee, H. J. , Toga, A. W. , McEwen, S. , Ford, J. M. , Mathalon, D. H. , Diaz, M. , O'Leary, D. S. , Jeremy Bockholt, H. , Gadde, S. , Preda, A. , … Potkin, S. G. (2016). The function biomedical informatics research network data repository. NeuroImage, 124, 1074–1079. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krienen, F. M. , Yeo, B. T. , & Buckner, R. L. (2014). Reconfigurable task‐dependent functional coupling modes cluster around a core functional architecture. Philosophical Transactions of the Royal Society of London. Series B, Biological Sciences, 369, 20130526. [DOI] [PMC free article] [PubMed] [Google Scholar]
- LaMontagne, P. J. , Benzinger, T. L. , Morris, J. C. , Keefe, S. , Hornbeck, R. , Xiong, C. , Grant, E. , Hassenstab, J. , Moulder, K. , Vlassenko, A. G. , Raichle, M. E. , Cruchaga, C. , & Marcus, D. (2019). OASIS‐3: Longitudinal neuroimaging, clinical, and cognitive dataset for normal aging and Alzheimer's disease. medRxiv, 2019.2012.2013.19014902.
- Lewandowski, K. E. , Bouix, S. , Ongur, D. , & Shenton, M. E. (2020). Neuroprogression across the early course of psychosis. Journal of Psychiatry and Brain Science, 5, e200002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lin, Q. H. , Liu, J. , Zheng, Y. R. , Liang, H. , & Calhoun, V. D. (2010). Semiblind spatial ICA of fMRI using spatial constraints. Human Brain Mapping, 31, 1076–1088. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Littlejohns, T. J. , Holliday, J. , Gibson, L. M. , Garratt, S. , Oesingmann, N. , Alfaro‐Almagro, F. , Bell, J. D. , Boultwood, C. , Collins, R. , Conroy, M. C. , Crabtree, N. , Doherty, N. , Frangi, A. F. , Harvey, N. C. , Leeson, P. , Miller, K. L. , Neubauer, S. , Petersen, S. E. , Sellors, J. , … Allen, N. E. (2020). The UK biobank imaging enhancement of 100,000 participants: Rationale, data collection, management and future directions. Nature Communications, 11, 2624. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Luo, W. , Greene, A. S. , & Constable, R. T. (2021). Within node connectivity changes, not simply edge changes, influence graph theory measures in functional connectivity studies of the brain. NeuroImage, 240, 118332. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ma, S. , Correa, N. M. , Li, X. L. , Eichele, T. , Calhoun, V. D. , & Adali, T. (2011). Automatic identification of functional clusters in FMRI data using spatial dependence. IEEE Transactions on Biomedical Engineering, 58, 3406–3417. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mejia, A. F. , Nebel, M. B. , Wang, Y. , Caffo, B. S. , & Guo, Y. (2020). Template independent component analysis: Targeted and reliable estimation of subject‐level brain networks using big data population priors. Journal of the American Statistical Association, 115, 1151–1177. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Meng, X. , Iraji, A. , Fu, Z. , Kochunov, P. , Belger, A. , Ford, J. , McEwen, S. , Mathalon, D. H. , Mueller, B. A. , Pearlson, G. , Potkin, S. G. , Preda, A. , Turner, J. , van Erp, T. , Sui, J. , & Calhoun, V. D. (2021). Multi‐model order ICA: A data‐driven method for evaluating brain functional network connectivity within and between multiple spatial scales. Brain Connect. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Murphy, K. , Bodurka, J. , & Bandettini, P. A. (2007). How long to scan? The relationship between fMRI temporal signal to noise ratio and necessary scan duration. NeuroImage, 34, 565–574. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rachakonda, S. , Silva, R. F. , Liu, J. , & Calhoun, V. D. (2016). Memory efficient PCA methods for large group ICA. Frontiers in Neuroscience, 10, 17. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Salehi, M. , Greene, A. S. , Karbasi, A. , Shen, X. , Scheinost, D. , & Constable, R. T. (2020). There is no single functional atlas even for a single individual: Functional parcel definitions change with task. NeuroImage, 208, 116366. [DOI] [PubMed] [Google Scholar]
- Smith, S. M. , Vidaurre, D. , Beckmann, C. F. , Glasser, M. F. , Jenkinson, M. , Miller, K. L. , Nichols, T. E. , Robinson, E. C. , Salimi‐Khorshidi, G. , Woolrich, M. W. , Barch, D. M. , Uğurbil, K. , & van Essen, D. C. (2013). Functional connectomics from resting‐state fMRI. Trends in Cognitive Sciences, 17, 666–682. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sui, J. , Adali, T. , Pearlson, G. D. , Clark, V. P. , & Calhoun, V. D. (2009). A method for accurate group difference detection by constraining the mixing coefficients in an ICA framework. Human Brain Mapping, 30, 2953–2970. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tamminga, C. A. , Ivleva, E. I. , Keshavan, M. S. , Pearlson, G. D. , Clementz, B. A. , Witte, B. , Morris, D. W. , Bishop, J. , Thaker, G. K. , & Sweeney, J. A. (2013). Clinical phenotypes of psychosis in the bipolar‐schizophrenia network on intermediate phenotypes (B‐SNIP). The American Journal of Psychiatry, 170, 1263–1274. [DOI] [PubMed] [Google Scholar]
- Triana, A. M. , Glerean, E. , Saramäki, J. , & Korhonen, O. (2020). Effects of spatial smoothing on group‐level differences in functional brain networks. Network Neuroscience, 4, 556–574. [DOI] [PMC free article] [PubMed] [Google Scholar]
- van de Ville, D. , Farouj, Y. , Preti, M. G. , Liégeois, R. , & Amico, E. (2021). When makes you unique: Temporality of the human brain fingerprint. Science Advances, 7, eabj0751. [DOI] [PMC free article] [PubMed] [Google Scholar]
- van Essen, D. C. , Smith, S. M. , Barch, D. M. , Behrens, T. E. , Yacoub, E. , & Ugurbil, K. (2013). The WU‐Minn human connectome project: An overview. NeuroImage, 80, 62–79. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang, D. , Buckner, R. L. , Fox, M. D. , Holt, D. J. , Holmes, A. J. , Stoecklein, S. , Langs, G. , Pan, R. , Qian, T. , Li, K. , Baker, J. T. , Stufflebeam, S. M. , Wang, K. , Wang, X. , Hong, B. , & Liu, H. (2015). Parcellating cortical functional networks in individuals. Nature Neuroscience, 18, 1853–1860. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wu, L. , Caprihan, A. , & Calhoun, V. (2021). Tracking spatial dynamics of functional connectivity during a task. NeuroImage, 239, 118310. [DOI] [PubMed] [Google Scholar]
- Yeo, B. T. , Krienen, F. M. , Sepulcre, J. , Sabuncu, M. R. , Lashkari, D. , Hollinshead, M. , Roffman, J. L. , Smoller, J. W. , Zöllei, L. , Polimeni, J. R. , Fischl, B. , Liu, H. , & Buckner, R. L. (2011). The organization of the human cerebral cortex estimated by intrinsic functional connectivity. Journal of Neurophysiology, 106, 1125–1165. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data S1. Supporting Information.
Data S2. Supporting Information.
Data S3. Supporting Information.
Data S4. Supporting Information.
Data S5. Supporting Information.
Data S6. Supporting Information.
Data S7. Supporting Information.
Data S8. Supporting Information.
Data S9. Supporting Information.
Data Availability Statement
The full list of datasets and resources for obtaining further details on each can be found in Supporting Information S1. The links for publicly available datasets and contact information for private datasets are included in Supporting Information S1. All the code used in this study could be made available by contacting the corresponding author (A. Iraji).