
Fig. 3 |. Generalization to natural speech perception.
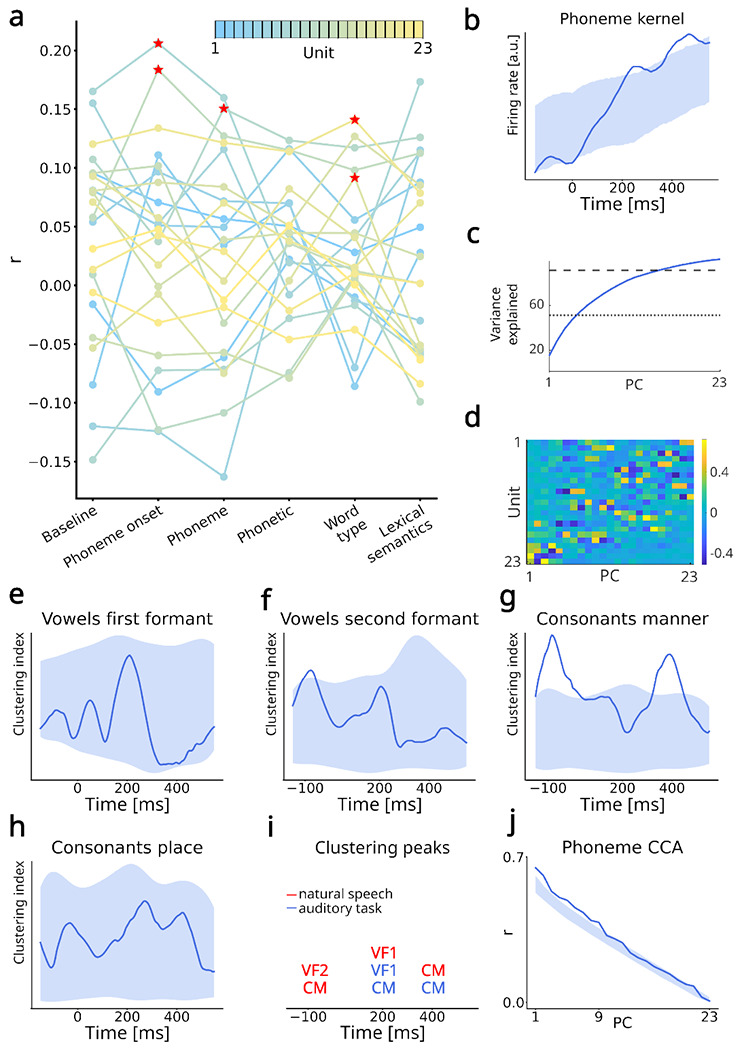
a. r values for each model and 23 most-spiking units. The units are color-coded based on their firing rate, from blue (lower) to yellow (higher). Red stars indicate model-unit pairs significantly higher than the baseline in a permutation test. b. Average mTRF kernel for phoneme feature. The shaded area indicates the 95% confidence region of the surrogate (chance-level) distribution. Phoneme kernel was significant at two time periods, centered around 250 and 450 ms. c. PCA variance explained. Four PCs explain 50% of variance (dotted line) and 15 explain 90% (dashed line). d. Principal component (PC) coefficients of identified units. Several units are represented in the first PCs, indicating distributed encoding of phonemes also during natural speech perception. e-h. Clustering index for the four groups of phonetic features. i. Overview of the significant clustering peaks observed both during the auditory task and natural speech perception. j. Canonical correlation analysis (CCA) between the PC projections of phoneme kernels obtained during the auditory task and natural speech perception. The shaded area indicates the 95% confidence region of the surrogate distribution. CCA revealed significant correlations for the first nine PCs.