
Figure 5.
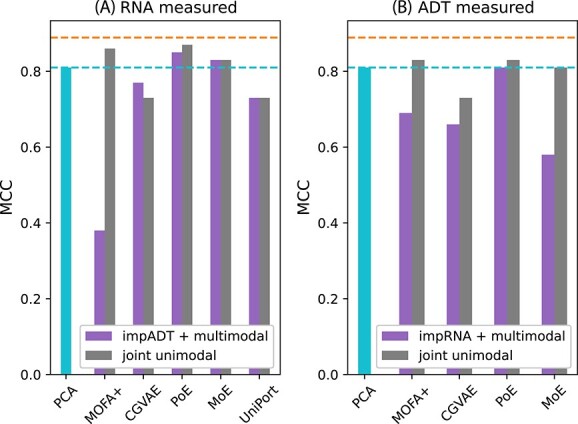
Comparison of training a cell type classifier in the joint space (joint unimodal, Figure 2C) versus using the joint space to impute a missing modality and using a classifier trained on both modalities (impRNA/ADT + multimodal, Figure 2E). Panel (A) shows the case when only RNA is available at test time, and (B) when only ADT measurements are available at test time. Performance is quantified by the MCC (higher is better). The left-most bar (light blue) and attached dashed line correspond to the performance of a MLP trained only on the measured modality, while the other dashed line (orange) shows the highest performance achieved by any model that used both measure d modalities (0.89).