
Fig 4. Concordance of ChatGPT4 on Chinese National Medical Licensing Examination after encoding.
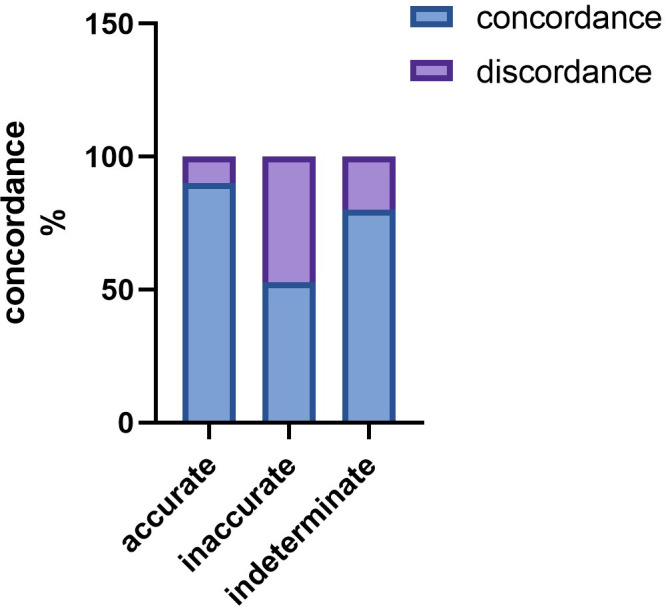
For Units 1, 2, 3, and 4 after encoding, ChatGPT’s outputs were evaluated as concordant or discordant, based on the scoring system detailed in S2 Table. This figure demonstrates the concordance rates stratified between accurate, inaccurate, and indeterminate outputs, across all case analysis questions.