
FIGURE 1.
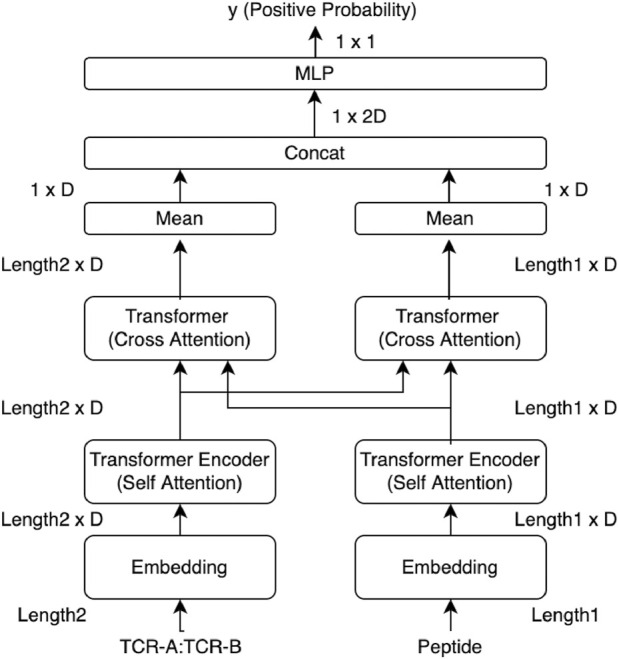
Overview of our cross-TCR-interpreter model. Data tensor sizes are denoted. The cross-attention layers in the middle of the figure were analyzed using structural data after being trained with sequence data. Each embedding layer takes amino acid sequences as the input.