
Fig. 2 |. High-performance text decoding from neural activity.
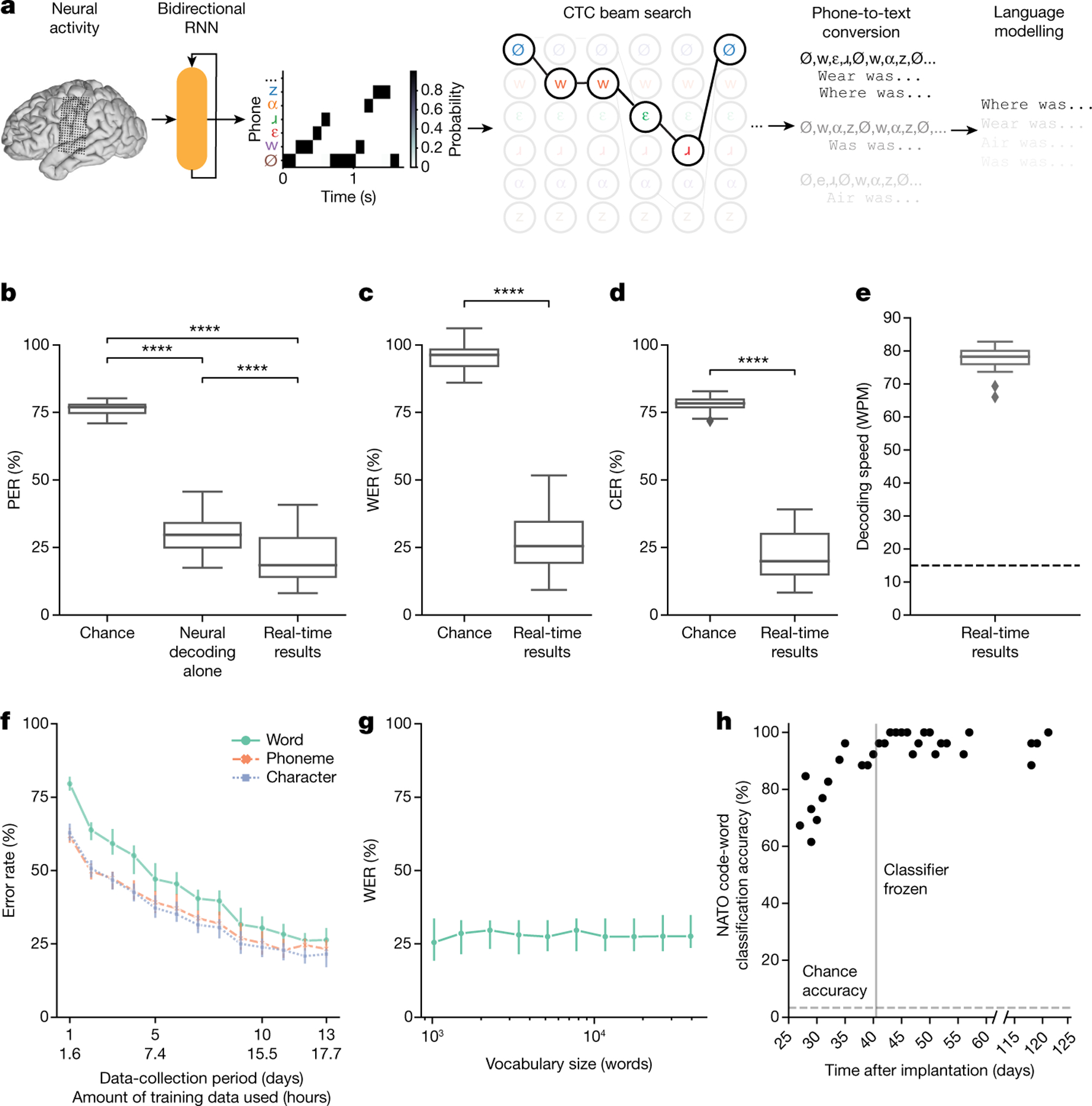
a, During attempts by the participant to silently speak, a bidirectional RNN decodes neural features into a time series of phone and silence (denoted as Ø) probabilities. From these probabilities, a CTC beam search computes the most likely sequence of phones that can be translated into words in the vocabulary. An n-gram language model rescores sentences created from these sequences to yield the most likely sentence. b, Median PERs, calculated using shuffled neural data (Chance), neural decoding without applying vocabulary constraints or language modelling (Neural decoding alone) and the full real-time system (Real-time results) across n = 25 pseudo-blocks. c,d, Word (c) and character (d) error rates for chance and real-time results. In b–d, ****P < 0.0001, two-sided Wilcoxon signed-rank test with five-way Holm–Bonferroni correction for multiple comparisons; P values and statistics in Extended Data Table 1. e, Decoded WPM. Dashed line denotes previous state-of-the-art speech BCI decoding rate in a person with paralysis1. f, Offline evaluation of error rates as a function of training-data quantity. g, Offline evaluation of WER as a function of the number of words used to apply vocabulary constraints and train the language model. Error bars in f,g represent 99% CIs of the median, calculated using 1,000 bootstraps across n = 125 pseudo-blocks (f) and n = 25 pseudo-blocks (g) at each point. h, Decoder stability as assessed using real-time classification accuracy during attempts to silently say 26 NATO code words across days and weeks. The vertical line represents when the classifier was no longer retrained before each session. In b–g, results were computed using the real-time evaluation trials with the 1024-word-General sentence set. Box plots in all figures depict median (horizontal line inside box), 25th and 75th percentiles (box) ± 1.5 times the interquartile range (whiskers) and outliers (diamonds).