
Fig. 3 |. Intelligible speech synthesis from neural activity.
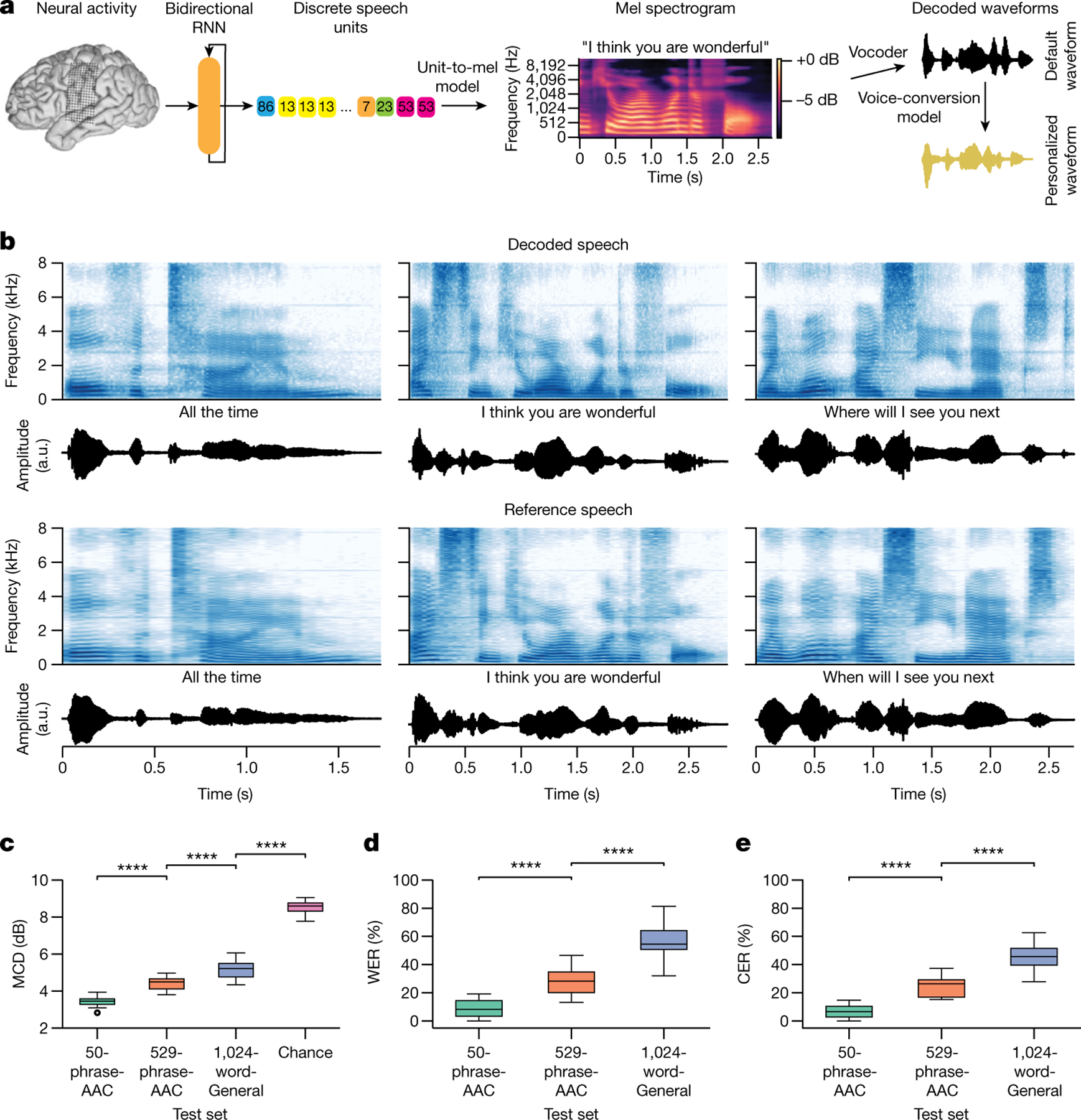
a, Schematic diagram of the speech-synthesis decoding algorithm. During attempts by the participant to silently speak, a bidirectional RNN decodes neural features into a time series of discrete speech units. The RNN was trained using reference speech units computed by applying a large pretrained acoustic model (HuBERT) on basis waveforms. Predicted speech units are then transformed into the mel spectrogram and vocoded into audible speech. The decoded waveform is played back to the participant in real time after a brief delay. Offline, the decoded speech was transformed to be in the participant’s personalized synthetic voice using a voice-conversion model. b, Top two rows: three example decoded spectrograms and accompanying perceptual transcriptions (top) and waveforms (bottom) from the 529-phrase-AAC sentence set. Bottom two rows: the corresponding reference spectrograms, transcriptions and waveforms representing the decoding targets. c, MCDs for the decoded waveforms during real-time evaluation with the three sentence sets and from chance waveforms computed offline. Lower MCD indicates better performance. Chance waveforms were computed by shuffling electrode indices in the test data for the 50-phrase-AAC set with the same synthesis pipeline. d, Perceptual WERs from untrained human evaluators during a transcription task. e, Perceptual CERs from the same human-evaluation results as d. In c–e, ****P < 0.0001, Mann–Whitney U-test with 19-way Holm–Bonferroni correction for multiple comparisons; all non-adjacent comparisons were also significant (P < 0.0001; not depicted); n = 15 pseudo-blocks for the AAC sets, n = 20 pseudo-blocks for the 1024-word-General set. P values and statistics in Extended Data Table 2. In b–e, all decoded waveforms, spectrograms and quantitative results use the non-personalized voice (see Extended Data Fig. 5 and Supplementary Table 1 for results with the personalized voice). A.u., arbitrary units.