
Fig. 4 |. Direct decoding of orofacial articulatory gestures from neural activity to drive an avatar.
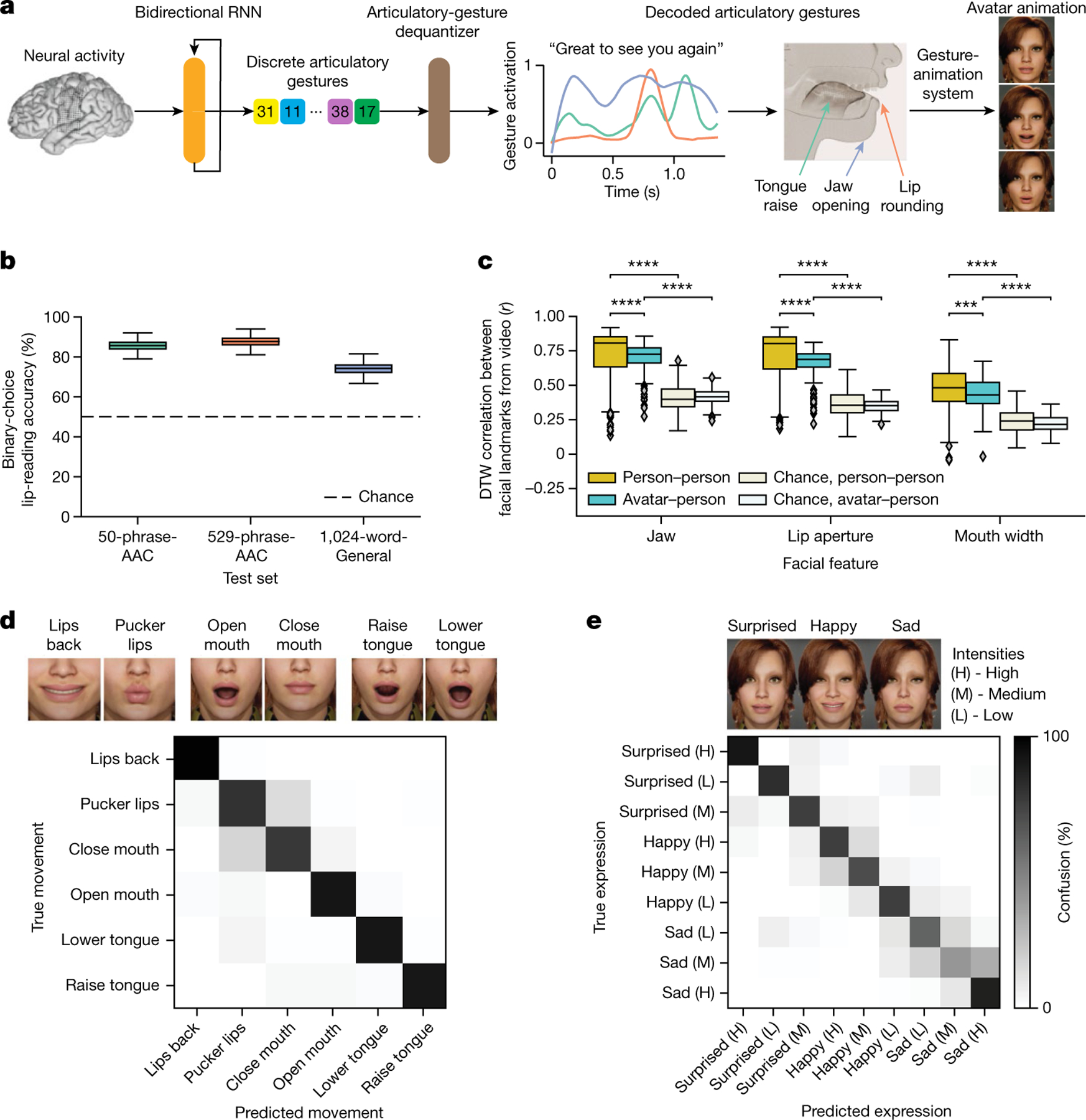
a, Schematic diagram of the avatar-decoding algorithm. Offline, a bidirectional RNN decodes neural activity recorded during attempts to silently speak into discretized articulatory gestures (quantized by a VQ-VAE). A convolutional neural network dequantizer (VQ-VAE decoder) is then applied to generate the final predicted gestures, which are then passed through a pretrained gesture-animation model to animate the avatar in a virtual environment. b, Binary perceptual accuracies from human evaluators on avatar animations generated from neural activity, n = 2,000 bootstrapped points. c, Correlations after applying dynamics time warping (DTW) for jaw, lip and mouth-width movements between decoded avatar renderings and videos of real human speakers on the 1024-word-General sentence set across all pseudo-blocks for each comparison (n = 152 for avatar–person comparison, n = 532 for person–person comparisons; ****P < 0.0001, Mann–Whitney U-test with nine-way Holm–Bonferroni correction; P values and U-statistics in Supplementary Table 3). A facial-landmark detector (dlib) was used to measure orofacial movements from the videos. d, Top: snapshots of avatar animations of six non-speech articulatory movements in the articulatory-movement task. Bottom: confusion matrix depicting classification accuracy across the movements. The classifier was trained to predict which movement the participant was attempting from her neural activity, and the prediction was used to animate the avatar. e, Top: snapshots of avatar animations of three non-speech emotional expressions in the emotional-expression task. Bottom: confusion matrix depicting classification accuracy across three intensity levels (high, medium and low) of the three expressions, ordered using a hierarchical agglomerative clustering on the confusion values. The classifier was trained to predict which expression the participant was attempting from her neural activity, and the prediction was used to animate the avatar.