
Extended Data 1. The detailed network architecture of cryo-READ.
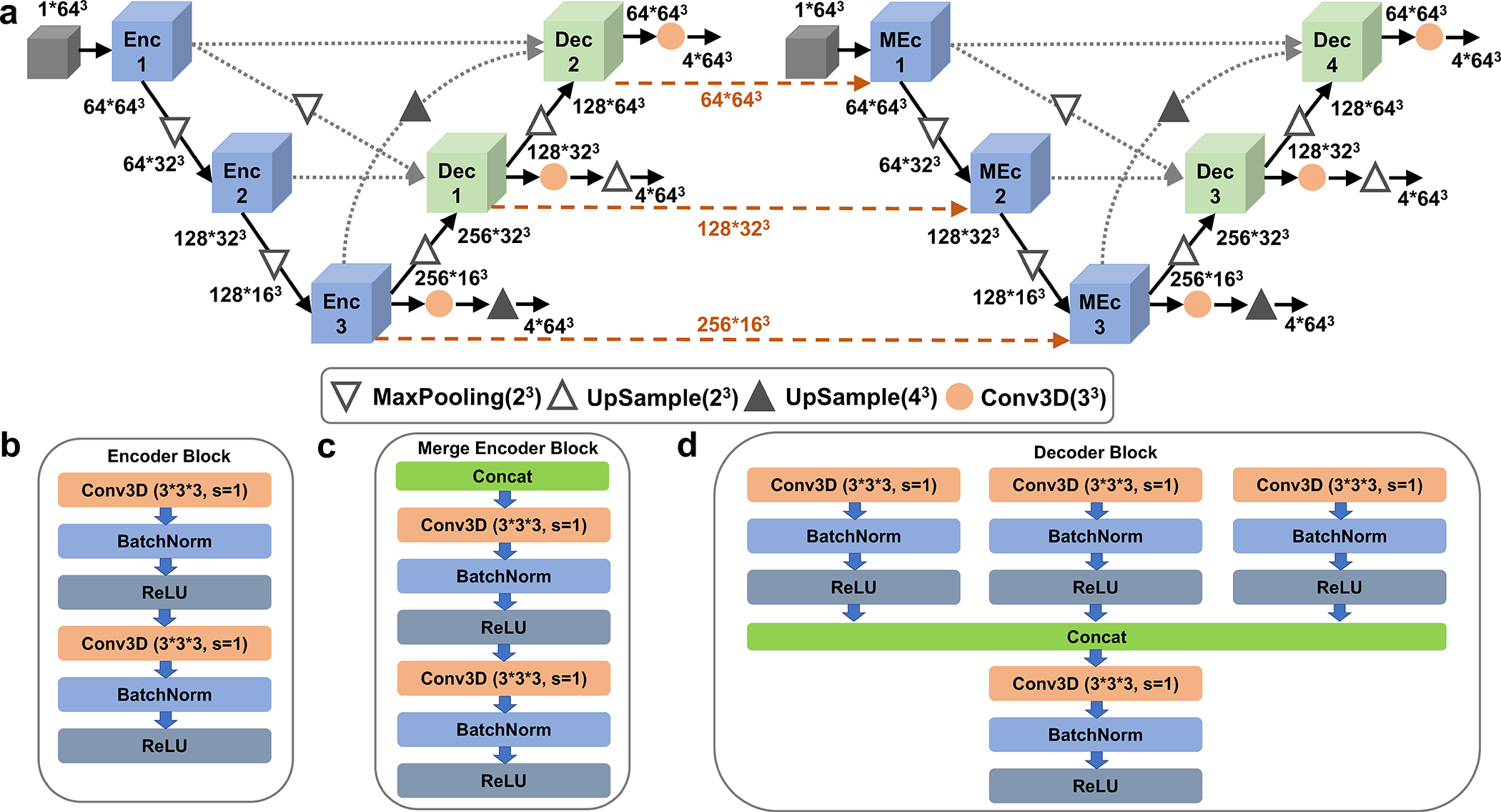
a, the network architecture. The entire network consists of two stages of U-Net networks and here we show the 1st stage networks. It concatenates two U-Net architectures. They are 3D U-shape-based convolutional Network (UNet) with full-scale skip connections and deep supervisions. The channel size of different layers is also illustrated in the figure. b, The Encoder Block (Enc1 in panel a); c, The Merge Encoder Block (MEnc); and d, the Decoder Block (Dec). Conv3D, a 3-dimentional (3D) convolutional layer with the filter size of 3*3*3, stride 1 and padding 1. BatchNorm, a normalization layer that takes statistics in a batch to normalize the input data. ReLU, Rectified Linear Unit, a commonly used activation layer.
It is a cascaded U-net, where the first U-Net (on the left) focuses on the prediction of high-level detection of sugar, phosphate, base, and protein while the second U-Net (on the right) focuses predicting different base types: A, C, G, and T/U. The processed information of the 1st U-Net encoder is also passed as input for the 2nd U-Net to help its predictions (dashed lines in orange). We applied deep supervision to the loss on output of different decoder outputs, which was shown to improve the performance. The stage 2 network only includes the first U-Net architecture of the stage 1 network. It takes predicted probabilities of 8*643 Å3 predictions (8 probabilities: protein, phosphate, sugar, base, and four different base types) from the stage 1 network and outputs the refined probabilities in a box of 8*64*64*64 Å3.