
TABLE 2.
Simulation result for Scenario 1b with 2 stages and 3 treatment options (sample size N = 1000, 100 replications).
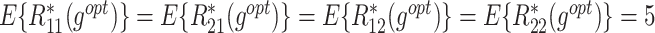 ;
; | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
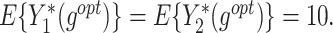
| ||||||||||
| Method | Stage 1 | Stage 2 | Overall | |||||||
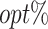
|
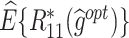
|
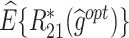
|
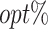
|
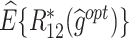
|
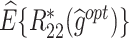
|
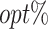
|

|
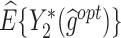
|
||
| T-RL | Y 1 as outcome | 77.75 (1.32) | 4.98 (0.07) | 3.35 (0.09) | 65.51 (5.20) | 4.31 (0.11) | 2.74 (0.28) | 43.89 (5.33) | 9.29 (0.14) | 6.09 (0.28) |
| Y 2 as outcome | 21.31 (1.19) | −0.36 (0.07) | 4.94 (0.07) | 77.36 (13.12) | 3.89 (1.06) | 4.20 (0.30) | 18.51 (6.74) | 3.53 (1.05) | 9.14 (0.30) | |
| MOT-RL: w = (0.3, 0.7) | ||||||||||
| 100% tolerant | 71.07 (12.41) | 3.11 (0.78) | 4.39 (0.20) | 96.02 (2.81) | 4.76 (0.16) | 4.58 (0.05) | 69.08 (12.04) | 7.87 (0.77) | 8.97 (0.21) | |
| 90% tolerant | 71.59 (12.46) | 3.12 (0.78) | 4.38 (0.20) | 96.16 (2.73) | 4.76 (0.16) | 4.58 (0.05) | 69.66 (12.11) | 7.88 (0.78) | 8.96 (0.21) | |
| 70% tolerant | 72.64 (12.19) | 3.10 (0.76) | 4.39 (0.20) | 96.38 (2.83) | 4.70 (0.17) | 4.58 (0.05) | 70.82 (11.94) | 7.80 (0.78) | 8.96 (0.20) | |
| 50% tolerant | 73.94 (12.01) | 2.94 (0.83) | 4.40 (0.23) | 96.62 (2.96) | 4.26 (0.28) | 4.51 (0.06) | 71.23 (11.89) | 7.19 (0.83) | 8.91 (0.24) | |
| MOT-RL: w = (0.4, 0.6) | ||||||||||
| 100% tolerant | 82.49 (12.28) | 3.78 (0.71) | 4.31 (0.23) | 96.08 (3.13) | 4.76 (0.19) | 4.58 (0.06) | 79.18 (12.36) | 8.54 (0.72) | 8.90 (0.24) | |
| 90% tolerant | 82.74 (12.30) | 3.79 (0.70) | 4.31 (0.24) | 96.08 (3.13) | 4.76 (0.19) | 4.58 (0.06) | 79.39 (12.36) | 8.55 (0.71) | 8.89 (0.24) | |
| 70% tolerant | 83.02 (12.57) | 3.82 (0.69) | 4.30 (0.23) | 96.18 (3.15) | 4.74 (0.19) | 4.58 (0.06) | 80.70 (12.69) | 8.55 (0.71) | 8.88 (0.24) | |
| 50% tolerant | 84.13 (12.27) | 3.76 (0.63) | 4.33 (0.25) | 96.52 (2.75) | 4.61 (0.24) | 4.55 (0.11) | 82.98 (12.45) | 8.37 (0.69) | 8.88 (0.28) | |
| MOT-RL: w = (0.5, 0.5) | ||||||||||
| 100% tolerant | 91.19 (9.96) | 4.35 (0.51) | 4.28 (0.23) | 95.99 (3.10) | 4.76 (0.18) | 4.58 (0.06) | 89.53 (10.49) | 9.10 (0.56) | 8.86 (0.23) | |
| 90% tolerant | 91.54 (9.94) | 4.36 (0.50) | 4.28 (0.24) | 95.99 (3.10) | 4.76 (0.18) | 4.58 (0.06) | 89.86 (10.52) | 9.12 (0.56) | 8.86 (0.24) | |
| 70% tolerant | 92.27 (9.89) | 4.37 (0.50) | 4.27 (0.24) | 95.99 (3.10) | 4.75 (0.19) | 4.58 (0.06) | 90.55 (10.57) | 9.12 (0.56) | 8.85 (0.24) | |
| 50% tolerant | 93.07 (9.58) | 4.27 (0.53) | 4.25 (0.29) | 96.30 (2.66) | 4.68 (0.21) | 4.56 (0.11) | 91.56 (10.05) | 8.96 (0.60) | 8.81 (0.31) | |
| MOT-RL: w = (0.6, 0.4) | ||||||||||
| 100% tolerant | 90.36 (10.73) | 4.72 (0.27) | 4.04 (0.45) | 95.68 (3.27) | 4.74 (0.19) | 4.58 (0.06) | 88.29 (11.35) | 9.46 (0.35) | 8.62 (0.46) | |
| 90% tolerant | 90.46 (10.70) | 4.73 (0.27) | 4.03 (0.47) | 95.68 (3.27) | 4.74 (0.19) | 4.58 (0.06) | 88.36 (11.32) | 9.47 (0.35) | 8.61 (0.48) | |
| 70% tolerant | 91.07 (10.54) | 4.74 (0.24) | 4.04 (0.46) | 95.84 (2.80) | 4.73 (0.21) | 4.57 (0.11) | 89.03 (10.95) | 9.47 (0.30) | 8.61 (0.47) | |
| 50% tolerant | 92.23 (9.98) | 4.68 (0.29) | 4.06 (0.44) | 96.17 (1.91) | 4.70 (0.23) | 4.55 (0.17) | 90.50 (10.12) | 9.38 (0.37) | 8.61 (0.46) | |
| MOT-RL: w = (0.7, 0.3) | ||||||||||
| 100% tolerant | 84.50 (10.11) | 4.88 (0.17) | 3.67 (0.46) | 95.04 (4.06) | 4.71 (0.22) | 4.56 (0.08) | 78.72 (10.65) | 9.59 (0.27) | 8.23 (0.47) | |
| 90% tolerant | 84.57 (10.15) | 4.89 (0.17) | 3.67 (0.47) | 95.08 (3.88) | 4.71 (0.22) | 4.56 (0.08) | 78.83 (10.53) | 9.59 (0.28) | 8.23 (0.48) | |
| 70% tolerant | 84.97 (10.11) | 4.88 (0.16) | 3.66 (0.47) | 95.37 (3.25) | 4.70 (0.24) | 4.55 (0.15) | 79.50 (10.42) | 9.58 (0.27) | 8.21 (0.50) | |
| 50% tolerant | 85.25 (10.02) | 4.87 (0.17) | 3.64 (0.45) | 95.83 (1.99) | 4.69 (0.26) | 4.52 (0.21) | 80.20 (10.36) | 9.55 (0.30) | 8.16 (0.49) | |
The 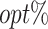 column indicates the empirical mean and standard error (SE) of the percentage of subjects whose estimated treatment set includes the actual optimal treatment, which is recorded for stage 1, stage 2, and both stage 1 and stage 2 (overall). The
column indicates the empirical mean and standard error (SE) of the percentage of subjects whose estimated treatment set includes the actual optimal treatment, which is recorded for stage 1, stage 2, and both stage 1 and stage 2 (overall). The  column presents the empirical mean and SE of the estimated counterfactual mean rewards of i th objective at stage j, Rij (i, j = 1, 2), which are obtained from true rewards and the estimated optimal (or tolerant) regime. The
column presents the empirical mean and SE of the estimated counterfactual mean rewards of i th objective at stage j, Rij (i, j = 1, 2), which are obtained from true rewards and the estimated optimal (or tolerant) regime. The  column presents the empirical mean and SE of the estimated counterfactual mean outcome of the ith objective.
column presents the empirical mean and SE of the estimated counterfactual mean outcome of the ith objective.