
Table 2.
A comprehensive summary of search space and optimal values of hyper-parameters
| Expression | Search Space | Optimal Value | ||
|---|---|---|---|---|
| Language Model | Classifier | |||
| Enhancers Identification | Strength Prediction | |||
| Number of LSTM layers | 1,2,3 | 3 | - | - |
| Number of neurons | 32, 64, 128, 256, 512 | 256 | - | - |
| Number of CNN layers | 1,2,3 | - | 1 | 1 |
| Number of filters | 10,20,30,40,50 | - | 30 | 30 |
| Kernal size | 1,2,3,4,5 | - | 3 | 3 |
| Weight Decay |
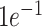 ,
, 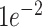 , , 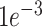 , , 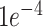 , , 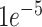
|
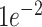
|
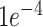
|
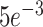
|
| Batch size | 16, 32, 64, 128, 256 | 64 | 64 | 64 |
| Dropout |
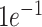 ,
, 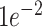 , , 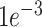 , , 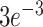 , , 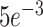 , , 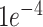 , , 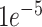
|
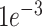
|
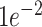
|
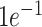
|
| Embedding size | 100, 200, 300, 400, 500 | 400 | 400 | 400 |
| Learning rate |
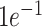 ,
, 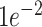 , , 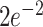 , , 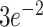 , , 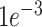 , , 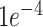 , , 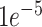
|
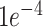
|
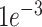
|
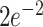
|
| Early Stopping | 1-200 | 50 | 5 | 7 |