
Fig. 1.
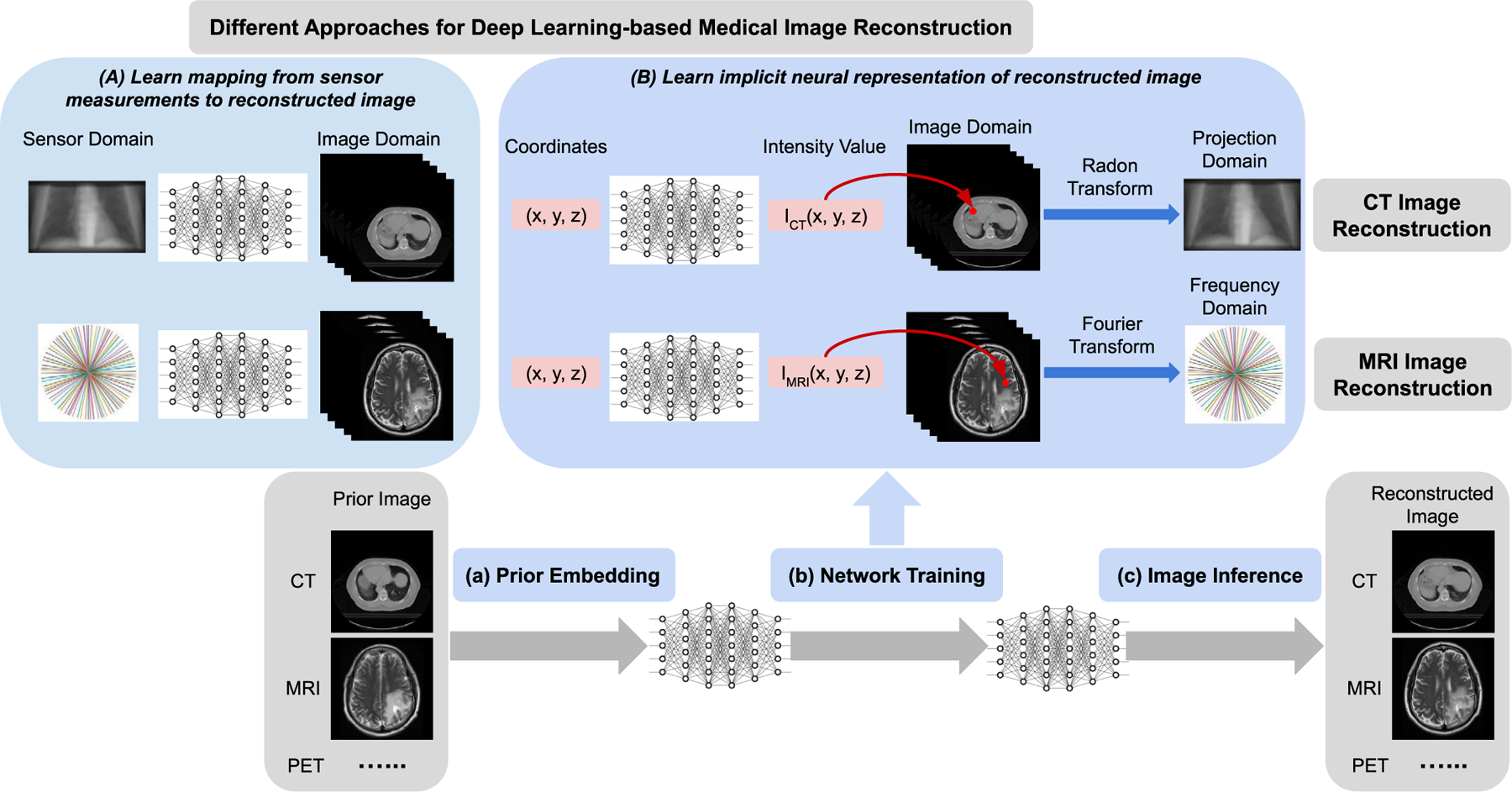
Schematic illustration of different approaches for deep learning-based medical image reconstruction. (A) Deep neural network is developed to learn the mapping from the sensor (measurements) domain (e.g. projection space, frequency space) to image domain (e.g. CT, MRI). (B) Deep neural network is developed to learn the implicit neural representation of the reconstructed image. The input to the network is the spatial coordinates for any points within the image field, while the output is the corresponding intensity values. Any image (e.g. CT, MRI) can be implicitly represented by a continuous function which is encoded into the neural network’s parameters. The proposed image reconstruction framework of implicit neural representation learning with prior embedding (NeRP) consists of three modules: (a) Prior Embedding: prior image is embedded into the neural network’s parameters by training with coordinate-intensity pairs. (b) Network Training: using the prior-embedded network as initialization, we train the reconstruction network constrained by the sparse samples in sensor (measurement) domain (i.e. projection domain for CT imaging, frequency domain for MRI imaging), and learn the implicit neural representation for the reconstructed image. (c) Image Inference: the reconstructed image is obtained by inferring the trained network across all the spatial coordinates in the image grid.