
Fig. 1 |. Geneformer architecture and transfer learning strategy.
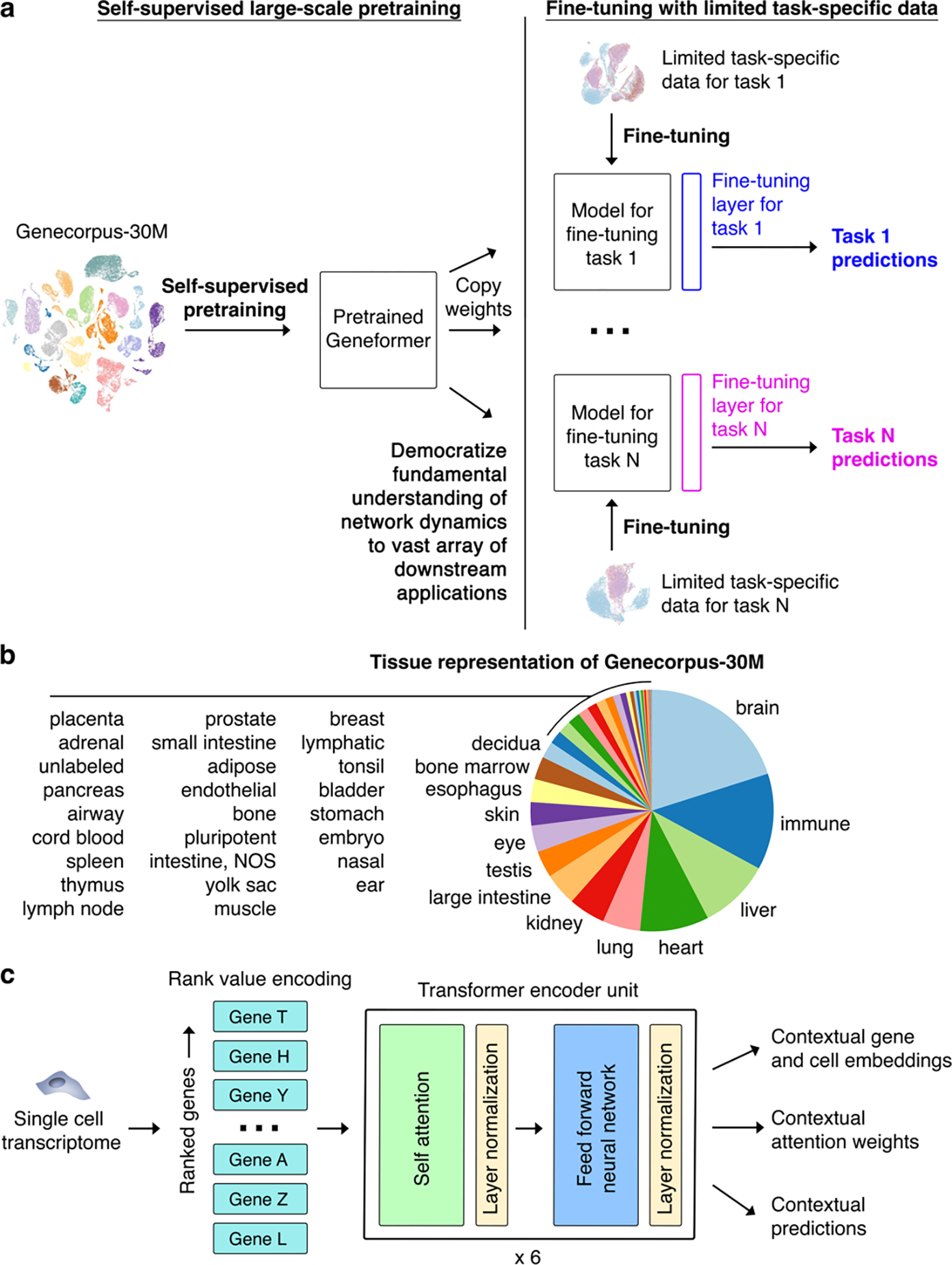
a, Schematic of transfer learning strategy with initial self-supervised large-scale pretraining, copying pretrained weights to models for each fine-tuning task, adding fine-tuning layer, and fine-tuning with limited task-specific data towards each downstream task. Through the single initial self-supervised large-scale pretraining on a generalizable learning objective, the model gains fundamental knowledge of the learning domain that is then democratized to a multitude of downstream applications distinct from the pretraining learning objective, transferring knowledge to new tasks. b, Tissue representation of Genecorpus-30M. NOS=not otherwise specified. c, Pretrained Geneformer architecture. Each single cell transcriptome is encoded into a rank value encoding that then proceeds through 6 layers of transformer encoder units with parameters: input size of 2048 (fully represents 93% of rank value encodings in Geneformer-30M), 256 embedding dimensions, 4 attention heads per layer, and feed forward size of 512. Geneformer employs full dense self-attention across the input size of 2048. Extractable outputs include contextual gene and cell embeddings, contextual attention weights, and contextual predictions.