
Figure 1:
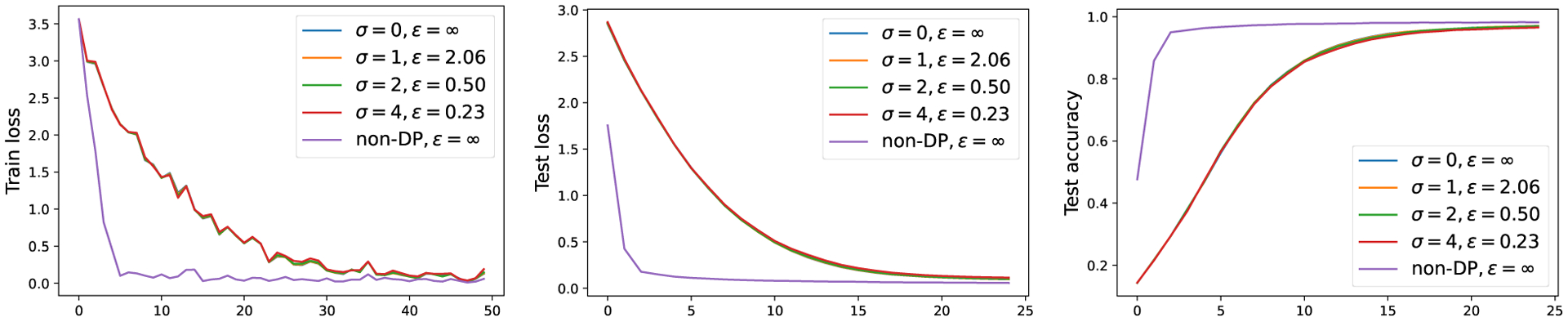
For fixed , ViT-base trained with DP-SGD under various noise has similar performance on CIFAR10 (setting in Section 5.3). Here ‘non-DP’ means both and no clipping. Notice that the loss curves for different are very similar (though not the same) to each other, because we fix the random seed at the beginning of each iteration among different runs. This is to eliminate the potential difference from uncontrolled random realizations for fair comparison.