
Figure 8:
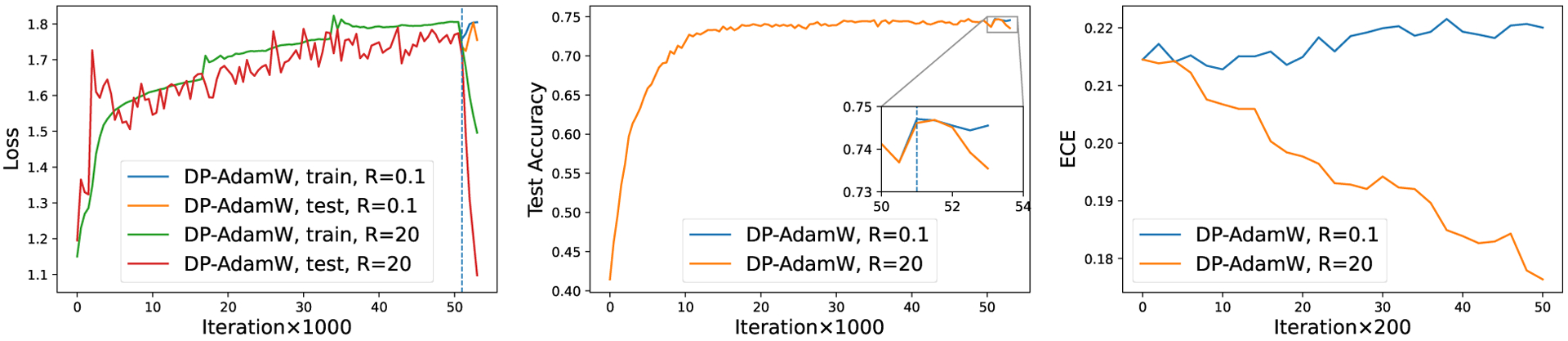
Loss (left), accuracy (middle) and calibration on SNLI with pre-trained BERT, batch size 32, learning rate 0.0005, noise scale 0.4, clipping norm are 0.1 or .
Official websites use .gov
A
.gov website belongs to an official
government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you've safely
connected to the .gov website. Share sensitive
information only on official, secure websites.
Loss (left), accuracy (middle) and calibration on SNLI with pre-trained BERT, batch size 32, learning rate 0.0005, noise scale 0.4, clipping norm are 0.1 or .