
Figure 1. Large Language Model (LLM) Potential Harm Ratings and Comparison of LLM vs Radiation Oncology Expert Responses for 115 Questions.
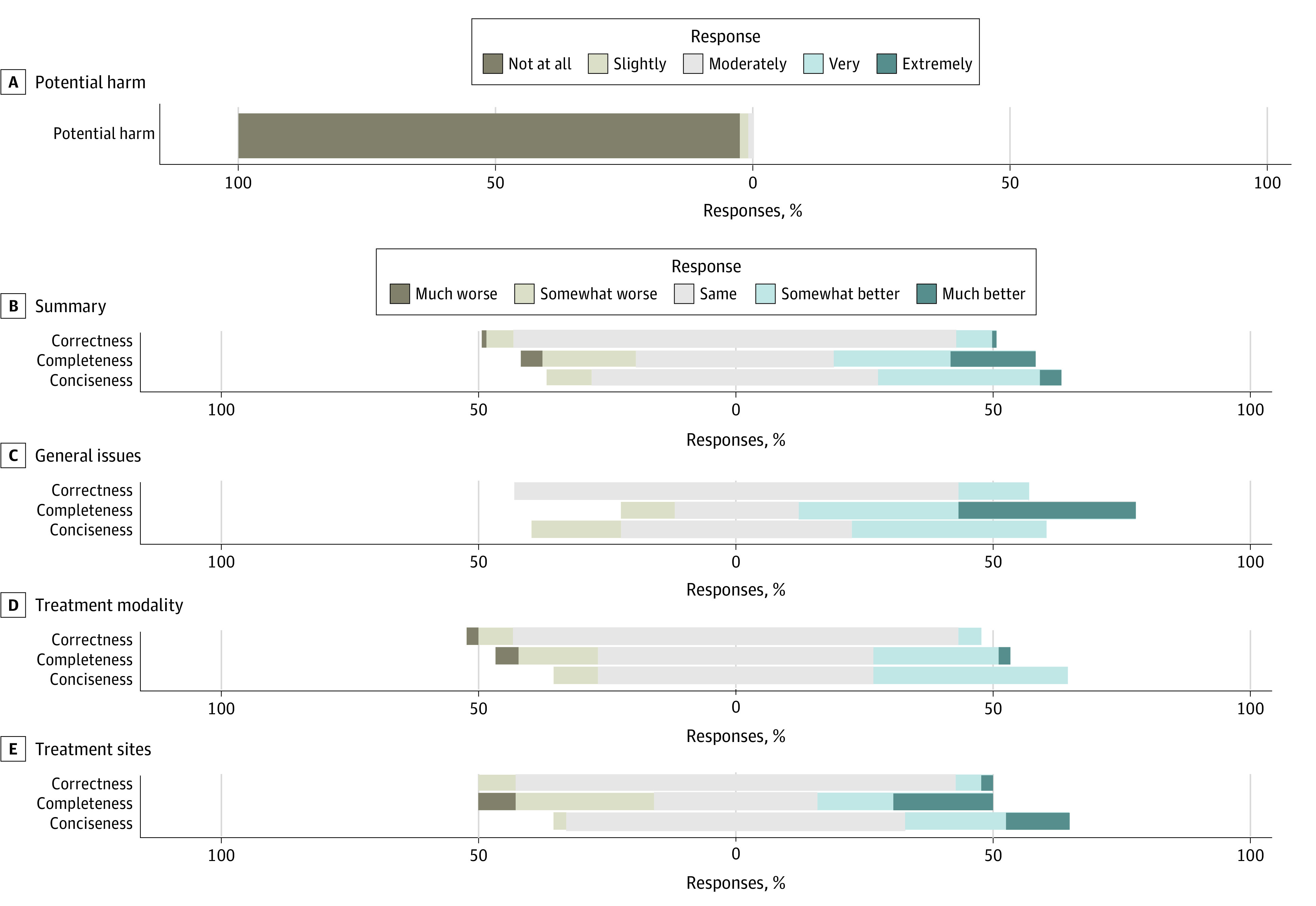
Likert scale plot including potential harm ratings for all 115 LLM-generated responses (A); followed by comparisons of the LLM’s responses to expert answers from online resources, evaluating relative factual correctness, completeness, and conciseness, across all questions (B), general radiation oncology topics (C), treatment modality–specific issues (D), and treatment site-specific queries (E).