
Figure 4.
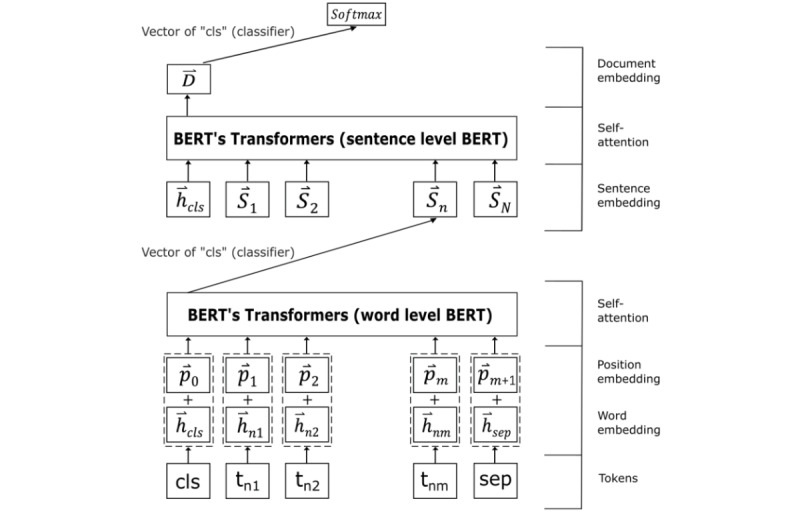
Composition of input sequence representations for text classification using BERT. The meaning of one sentence is summarized into the vector of [CLS] (classifier), an artifact token concatenated at the beginning of each sentence to become the sentence embedding. The sentence embedding is then fed to another transformer to generate the document embedding. An output layer with SoftMax activation provides the probability of text classification. BERT: bidirectional encoder representations from transformers.