
Figure 1.
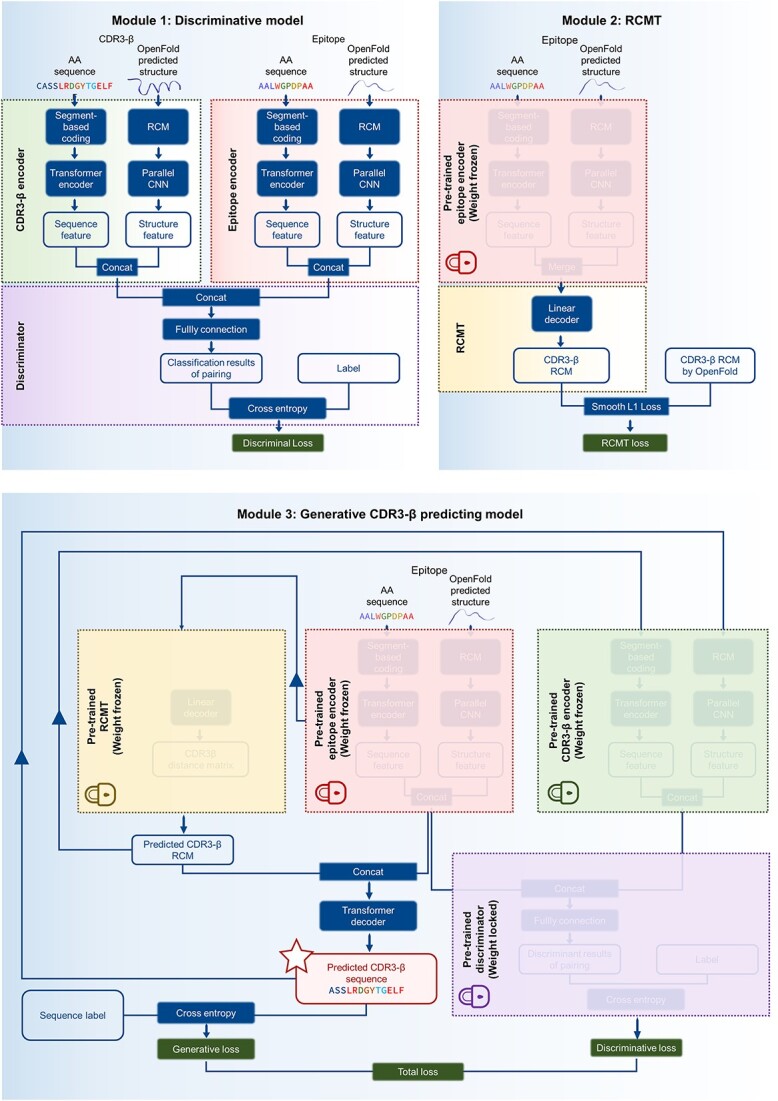
Model architecture. The model comprises three modules. The first module, the discriminator module (CATCR-D), employs a CNN to extract structural features as predicted by OpenFold and a transformer encoder for sequence feature extraction. Structures are represented using RCMs, and sequences are encoded using a segment-based coding scheme before embedding. The features extracted from the epitope and CDR3-β are concatenated and fed into a classifier to determine the binding outcome. The second module, the RCMT, leverages the pretrained epitope encoder from the first module to extract epitope features and utilizes a linear decoder to predict the RCM for CDR3-β. The third module, the generator module, integrates the predicted CDR3-β RCM with epitope features from the epitope encoder and employs the transformer decoder to generate the CDR3-β sequence. This predicted sequence and the predicted CDR3-β RCM are reintroduced into the discriminator to refine the generative model via feedback from the discriminator loss. AA: amino acid; RCM: residue contact matrices; RCMT: residue contact matrices transformer.