
Figure 1.

Overview of UltraMutate’s architecture and workflow. (A) For a given pHLA pair, the SL policy network takes embedded sequences and flattened vectors from three distinct attention matrices as input. It uses a linear layer to combine features from four input heads to generate a conditional probability distribution 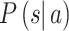 for all possible mutation actions. (B) The interactive environment for the agent, where rewards are given based on the binding probability of the mutated peptide with the HLA molecule and the homology between the mutated and original peptides. (C) UltraMutate’s overall workflow includes: (1) supervised learning with the AOMP dataset; (2) fine-tuning the policy network using RL with PPO; and (3) integrating with an MCTS algorithm to determine the final mutation action.
for all possible mutation actions. (B) The interactive environment for the agent, where rewards are given based on the binding probability of the mutated peptide with the HLA molecule and the homology between the mutated and original peptides. (C) UltraMutate’s overall workflow includes: (1) supervised learning with the AOMP dataset; (2) fine-tuning the policy network using RL with PPO; and (3) integrating with an MCTS algorithm to determine the final mutation action.