
Figure 2.
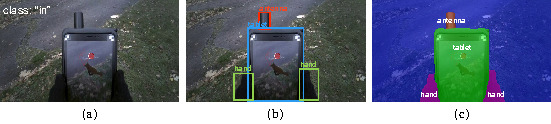
(a) Image classification: an entire image is assigned with a label, or “class”. Our approach consists in training a model to detect whether the red gaze marker is located within the tablet.
(b) Object detection: several objects are detected as well as their locations as rectangular frames. While more insightful than image classification, determining if the red gaze marker lies in the tablet would require an extra step of geometric calculation to cross-reference the marker’s coordinates with that of the tablet’s area, and rectangular shape of the latter makes it prone to inaccuracies.
(c) Semantic segmentation: several objects are detected, and the detail of their contour. Using this approach to compute dwell time on the tablet would also require extra geometric calculation, without being prone to inaccuracies, because the contours accurately fit the detected objects.