
Figure 2:
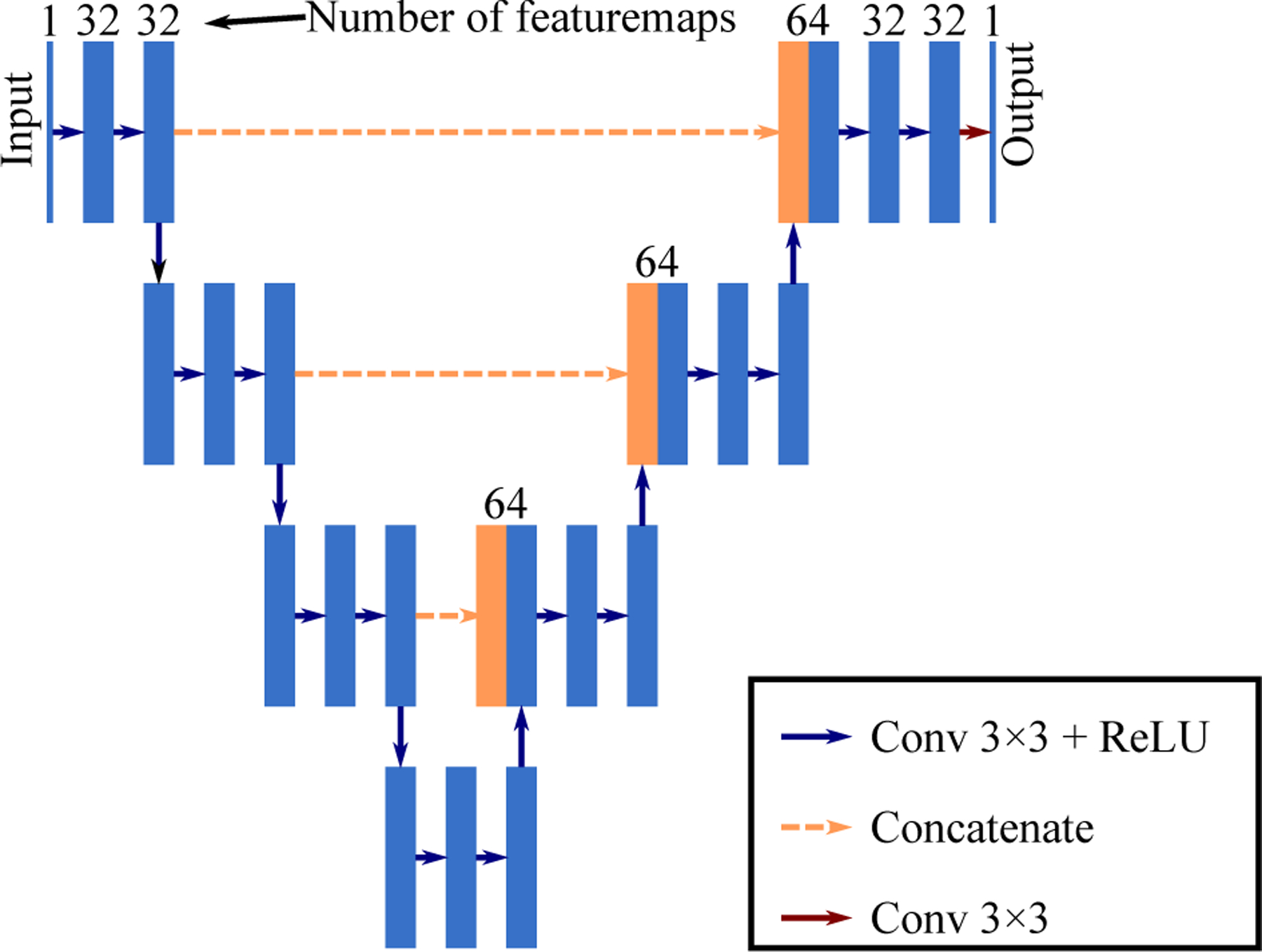
The encoder-decoder network used in the studies. The resolution remained the same for all the featuremaps in the network, which was 96 × 96 during patch-based training and 640 × 640 during inference. The number of channels for all the blue blocks were 32 except for the input and output layer.