
Fig. 3.
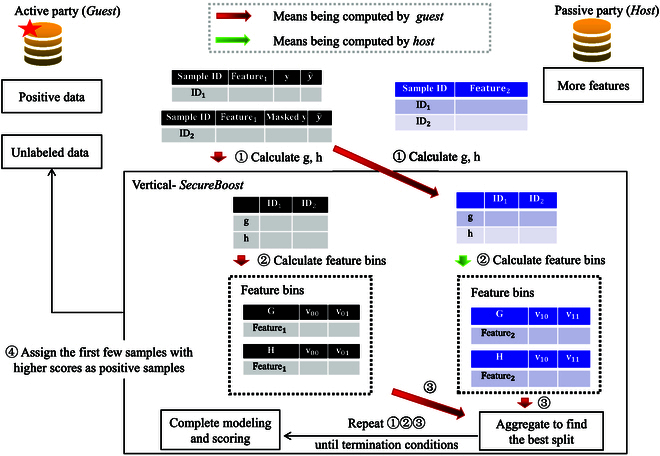
Rough outline of the workflow of semisupervised vertical-SecureBoost. The illustration shows 2 federation participants, a host party and a guest party. In the guest side, ID1 represents labeled samples, ID2 represents unlabeled samples. Masked y refers to our treatment of unlabeled samples based on the PU learning strategy. y represents the predictions of the samples from the previous round. The host side does not have labels and only provides features. In stage 1, the guest side calculates the first-order derivative (gi) and the second-order derivative (hi) of the loss function for each sample ID based on the real or masked labels and the predictions from the previous round, and sends this information to the host side. In stage 2, all parties calculate feature bins based on the information from gi and hi, and this relevant information is transmitted to the guest side. In stage 3, the guest side aggregates all the feature bin information from the participating parties and iteratively calculates the best split points for the tree. In stage 4, the algorithm ranks the samples based on the scoring values obtained using the PU learning strategy.