
Figure 1:
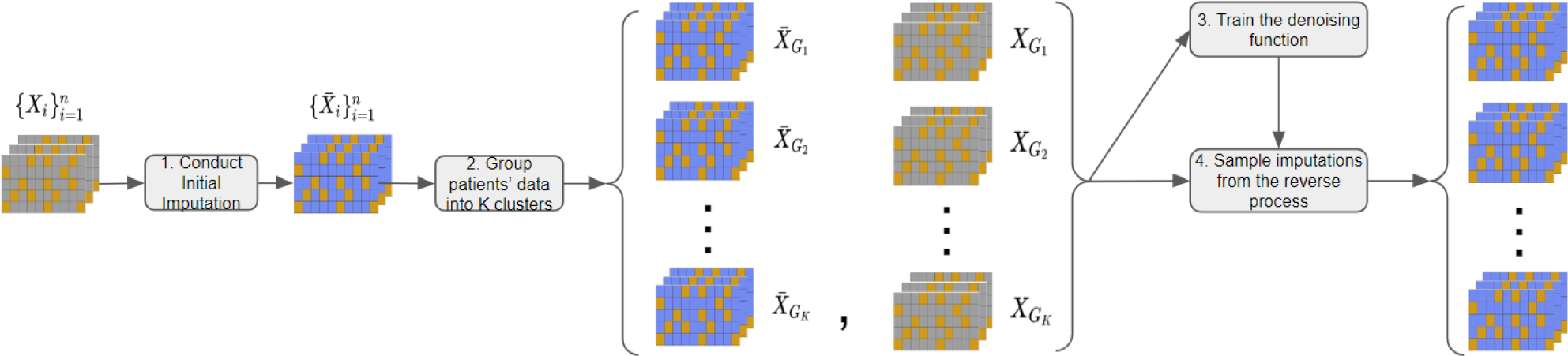
The procedure of temporal missing value imputation with SADI. Each table represents a patient’s EHR data, with gray cells indicating missing values, orange cells indicating observed values, and blue cells indicating imputed values. The process involves (1) conducting an initial imputation (e.g., using CSDI) on the entire dataset to generate imputed data , (2) applying a clustering algorithm (e.g., K-SC) to categorize imputed data into clusters and acquiring the corresponding original data clusters , (3) training SADI on the clustered datasets , and (4) sampling imputations for the data clusters using the reverse process of SADI.