
Figure 2.
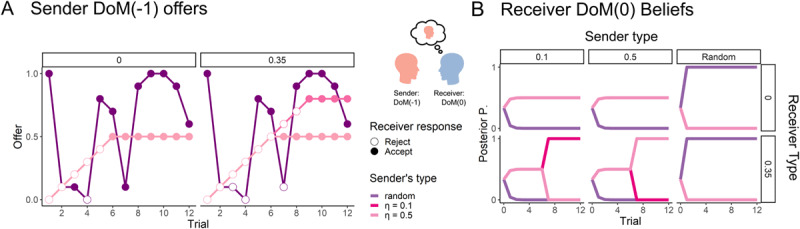
Illustration of DoM(0) IRL: (A, B) In interacting with the DoM(–1) sender (A), the DoM(0) receiver makes inferences about the sender’s type (B). Notably, the first offer is usually sufficient to tell the random sender from the threshold senders. When the receiver’s belief favours the threshold sender, the receiver manipulates the sender by rejecting the offers until a desired offer is met, according to the receiver’s threshold. Both DoM(–1) threshold agents are reactive – that is, they respond to the behaviour of others. Hence they react similarly to the strategic behaviour of the DoM(0) until their “willingness” to bounded is limited by their threshold (after 6 trials) – the main difference between their behaviour is the maximal offer they are willing to make. The thresholds of the agents determine the range of possible agreement – agents with higher thresholds are less willing to “compromise”. For example, agents (both receiver and sender) with higher thresholds need a more egalitarian split of the endowment compared to those with low thresholds.
Note: Posterior P(θ) means the posterior distribution of the inferring agent after observing the actions of the other agent. P(θ) = 0 means that the inferring agent’s belief places zero probability that the observed agents has type θ and P(θ) = 1 means that the inferring agent is certain that the observed agent has type θ (when lines overlap the behaviour of the DoM(–1) sender or the updated beliefs of the DoM(0) are the same for both thresholds).