
Fig. 4. Confusion matrices for the output phonemes of XLSR-Wav2vec 2.0.
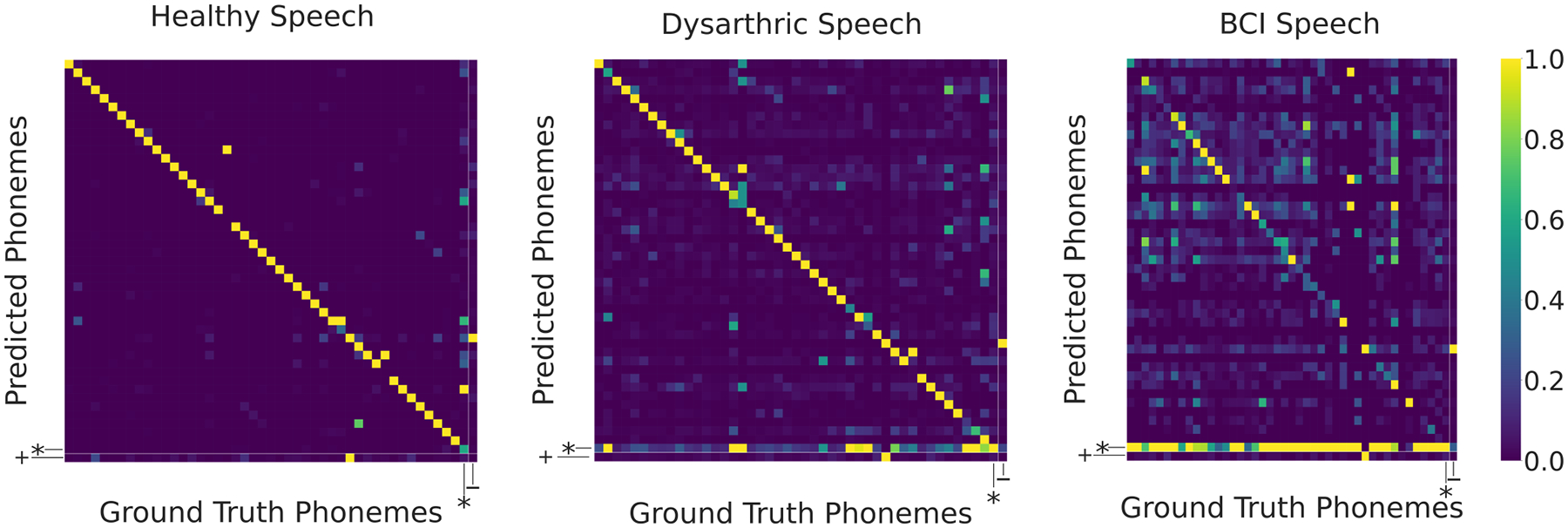
The datasets are grouped into 3 categories: Healthy Speech (the Librispeech test set), Dysarthric Speech (aggregating TORGO, Nemours and UA Speech) and BCI Speech (aggregating the data from Wilson et al. 2020, Herff et al. 2019, Anumanchipalli et al. 2019). Asterisks * indicate rows where the model infers phonemes outside of English IPA or columns where phonemes in the dataset are not in the output space of the model. The “−” symbol indicates when a deletion operation was required to match ground truth, and a “+” indicates when an insertion operation was required. The colorbar corresponds to the proportion of events.