
Fig. 3 |. Identifying the best model/method.
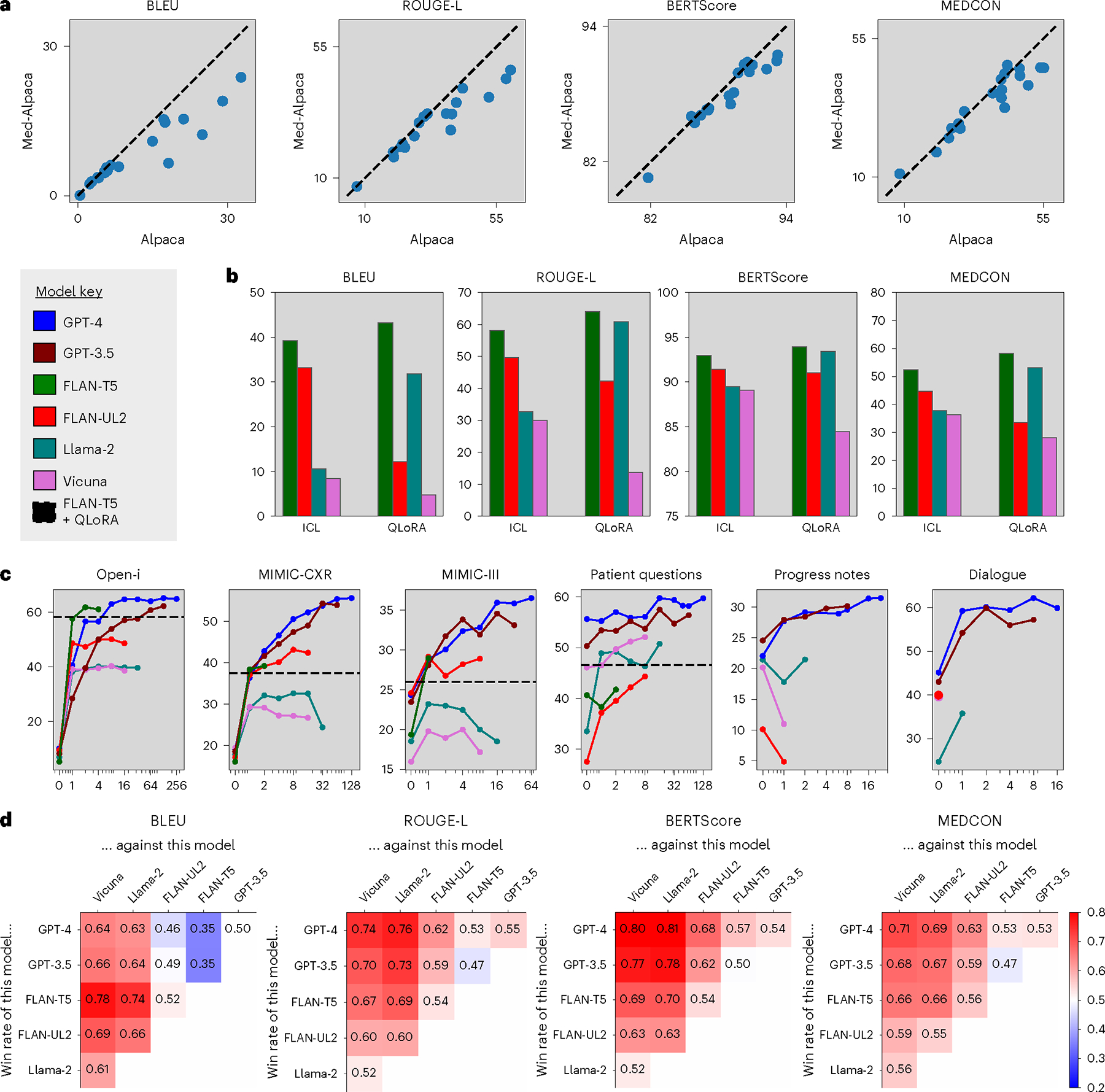
a, Impact of domain-specific fine-tuning. Alpaca versus Med-Alpaca. Each data point corresponds to one experimental configuration, and the dashed lines denote equal performance. b, Comparison of adaptation strategies. One in-context example (ICL) versus QLoRA across all open-source models on the Open-i radiology report dataset. c, Effect of context length for ICL. MEDCON scores versus number of in-context examples across models and datasets. We also included the best QLoRA fine-tuned model (FLAN-T5) as a horizontal dashed line for valid datasets. d, Head-to-head model comparison. Win percentages of each head-to-head model combination, where red/blue intensities highlight the degree to which models on the vertical axis outperform models on the horizontal axis.