
Fig 1.
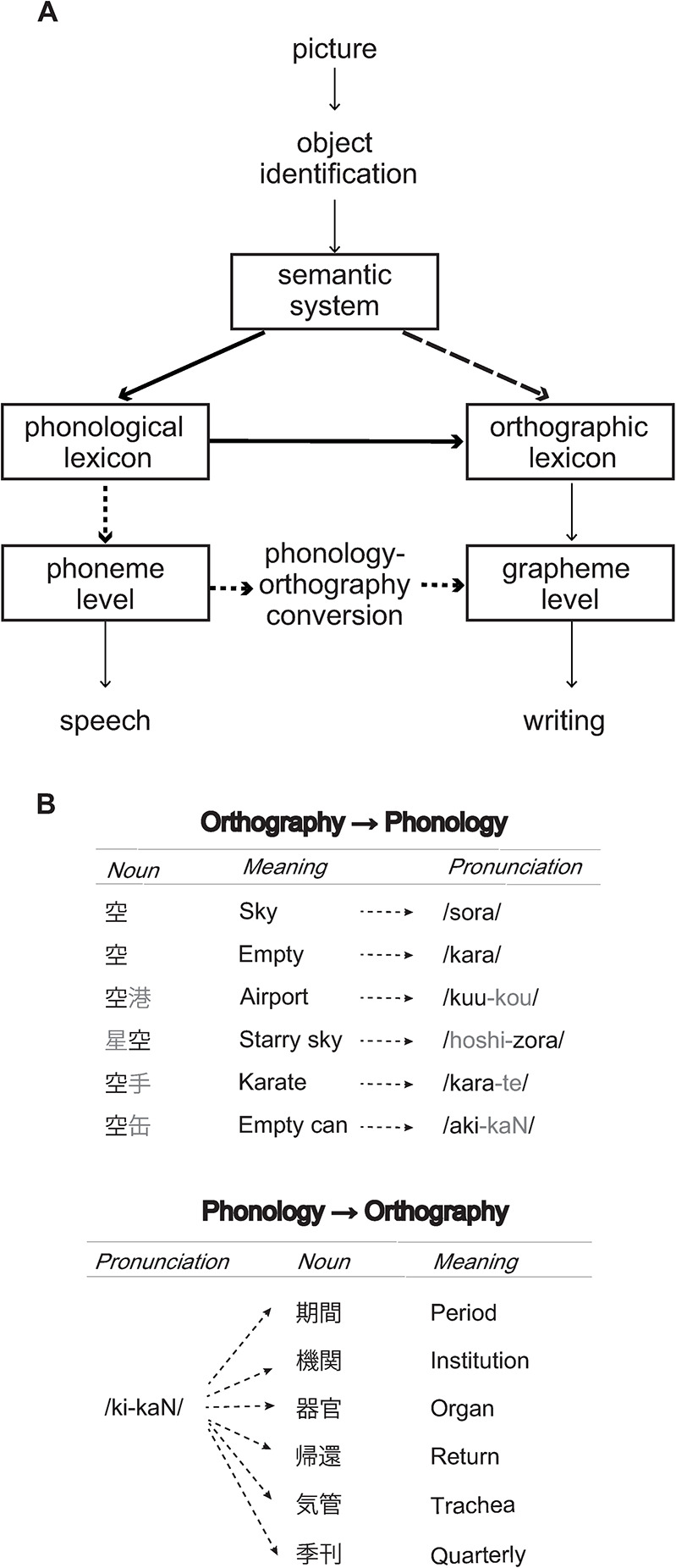
A. Cognitive model of spoken and written naming (modified from Bonin et al. (2011). Spoken and written production systems consist of shared components for visual structural analysis and semantic analysis as well as modality-specific components for generating response outputs, that is, phonological lexicons/ lexemes for naming and orthographic lexicons/lexemes for writing. After common visual structural and semantic analyses, orthographic lexicons/lexemes required for writing may be accessed directly from the semantic system during written production (“orthographic autonomy hypothesis”, dashed line). Alternatively, such orthographic codes may be accessed either via the direct lexical-level link between phonological and orthographic lexicons (solid line) or via the sublexical-level link between phonological and orthographic lexemes (dotted line) (“phonological mediation hypothesis”). B. Orthography and phonology in kanji. The kanji script is a highly opaque writing system whose correspondence between form and sound is one-to-many in both directions. That is, each character (e.g., “空”) can represent, either on its own or in conjunction with other characters, several different sounds and meanings (top). On the other hand, the same sound (e.g., “kikaN”) can be mapped onto several different words and meanings, each written with different kanji characters (bottom).